本文是Boutros El-Gamil的使用Apache Spark进行预测性数据分析系列文章的第二篇,http://www.data-automaton.com/2019/01/04/predictive-data-analytics-with-apache-spark-part-2-data-preparation/
第一篇详见使用Apache Spark进行预测性数据分析--简介篇
关于Windows 下PySpark的安装教程可以查看Windows 下pyspark的最简化安装
1.下载数据并创建项目目录
我们首先从https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/下载Turbofan Engine Degradation Simulation Data Set。解压缩.zip文件,并将展开的文件夹(/CMAPSSData)添加到您的项目主目录。
数据文件夹由12个.txt文件组成,它们代表测试数据集的四个独立部分,以及它们对应的测试数据集和真实数据。本教程分析数据的第一部分。但是您可以自由添加附加数据部分,并使用相同的代码对其进行测试。
本教程中的代码可以在Python 3.7和Spark 2.4.4版本下执行(原文基于Python2.7和Spark2.3.1,需要Python2.7版本代码的可以直接看原文提供的代码)。
2.清理主目录
在启动Spark编码之前,我们需要从自动生成的组件中清除Spark主目录,这些组件可能在先前的Spark执行过程中添加。从Spark 2.1.x开始,由于Spark-defaults.conf.template文件中的默认设置,Spark在代码的主目录中自动生成metastore_db目录和derby.log文件。这些自动生成的组件中的数据可能会中断当前Spark会话的执行。因此,我们需要同时删除metastore_db目录和derby.log文件,以使Spark会话能够正常启动。以下功能可以完成这项工作。
def clean_project_directory(): ''' This function deletes both '/metastore_db' folder and 'derby.log' file before initializing Apache Spark session. The goal is to avoid any inconsistant startout of Spark session '''
print (os.getcwd())
# delete metastore_db folder if found if os.path.isdir(os.getcwd() + '/metastore_db'): shutil.rmtree(os.getcwd() + '/metastore_db', ignore_errors=True)
# delete derby.log file if found if os.path.exists(os.getcwd() + '/derby.log'): os.remove(os.getcwd() + '/derby.log')
# run functionclean_project_directory()3.启动Spark会话
清理Spark主目录后,我们创建一个新的Spark会话。pyspark.sql模块包含SparkSession() 函数,使我们能够创建新的Spark会话。使用此功能,我们可以设置一些不错的属性,例如会话的主URL,Spark应用程序名称以及为每个执行程序进程保留的最大内存量。在下面的函数中,我们创建一个Spark会话,该会话在本地计算机上运行,最大保留内存为1 GB。
def create_spark_session(app_name, exe_memory): ''' This function creates Spark session with application name and available memory to the session INPUTS: @app_name: name of Spark application @exe_memory: value of reserved memory for Spark session OUTPUTS: @SparkSession instance ''' # create Spark Session return SparkSession.builder \ .master("local") \ .appName(app_name) \ .config("spark.executor.memory", exe_memory) \ .getOrCreate()
# create Spark session spark = create_spark_session('Predictive Maintenance', '1gb')
# set Spark Context objectsc = spark.sparkContext
# print configurations of current Spark sessionsc.getConf().getAll()4.导入.CSV数据文件到Spark会话
在此步骤中,我们将.CSV格式的训练和测试数据文件作为RDD对象导入到Spark会话中。RDD(即弹性分布式数据集)是Apache Spark的核心数据格式,可以通过所有Spark支持的语言(Scala,Python,Java和SQL)调用。与Hadoop分布式文件系统(HDFS)相比,RDD在速度上有着明显优势。
将CSV文件导入为RDD对象的最简单方法是使用sparkContext模块。我们使用union()函数将所有CSV文件附加到一个RDD对象。然后我们使用map()函数将数据字段分为RDD对象。
def read_csv_as_rdd(sc, path, files_list, sep): ''' This function reads .CSV data files into RDD object and returns the RDD object INPUTS: @sc: Spark Context object @path: path of .CSV files @files_list: list of :CVS data files @sep: fields separator OUTPUTS: @rdd: RDD object contains data observations ''' # Read files and append them to RDD rdd = sc.union([sc.textFile(path + f) for f in files_list])
# Split lines on spaces rdd = rdd.map(lambda line: line.split(sep)) # return RDD object return rdd
# get files of training datatrain_files = sorted([filename for filename in os.listdir(path) if (filename.startswith('train') and filename.endswith('.txt'))])
# get files of test datatest_files = sorted([filename for filename in os.listdir(path) if (filename.startswith('test') and filename.endswith('.txt'))])
# read training data in RDDtrain_rdd = read_csv_as_rdd(sc, path, [train_files[0]], " ")
# read test data in RDDtest_rdd = read_csv_as_rdd(sc, path, [test_files[0]], " ")
# print num. of observations of training dataprint ("number of observations in train data: ", train_rdd.count())
# print num. of observations of test dataprint ("number of observations in test data: ", test_rdd.count())5.将RDD转换为Spark Dataframe
PySpark的基本优点是能够将RDD对象转换为Dataframes。对于那些熟悉R或Python Dataframes的读者,使用Spark Dataframes使Spark编码容易得多。与R和Python Dataframes相似,Spark Dataframes也是将数据对象组成的组,这些数据对象被组织到命名字段(即列)中。为了将RDD对象转换为Spark Dataframe,您所需要做的就是定义要分配给数据的列名列表。函数toDF()将为您完成其余工作。
def convert_rdd_to_df(rdd, header): ''' This function converts data from RDD format to Spark Dataframe, and adds header to the dataframe INPUTS: @rdd: RDD object contains data features @header: list of column names OUTPUTS: PySpark DF version of @rdd ''' # convert RDD to DF with header return rdd.toDF(header)
# Set data header, contains list of names of data columnsheader = ["id", "cycle", "setting1", "setting2", "setting3", "s1", "s2", "s3", "s4", "s5", "s6", "s7", "s8", "s9", "s10", "s11", "s12", "s13", "s14", "s15", "s16","s17", "s18", "s19", "s20", "s21"]
# get df of both train and test data out of corresponded RDD objectstrain_df = convert_rdd_to_df(train_rdd, header)test_df = convert_rdd_to_df(test_rdd, header)
# drop empty columns from DFtrain_df= train_df.drop("_27").drop("_28")test_df= test_df.drop("_27").drop("_28")
# check the dimensions of the dataprint (train_df.count(), len(train_df.columns))print (test_df.count(), len(test_df.columns))6.删除NULL值
在将数据集作为Spark Dataframes获取之后,我们想要删除NULL观察值(即没有值的数据观察值)。为此,我们所需要做的就是将na.drop()应用于我们的数据帧。
def remove_na_rows(df): ''' This function removes rows with empty values from Spark Dataframe INPUTS: @df: Spark Dataframe with possible NULL values OUTPUTS: @df: Spark Dataframe without NULL values ''' return df.na.drop()
# check the dimensions of the dataprint ("Before removing NULL rows:")print (train_df.count(), len(train_df.columns))print (test_df.count(), len(test_df.columns))
# remove empty rowstrain_df = remove_na_rows(train_df)test_df = remove_na_rows(test_df)
print ("After removing NULL rows:")# check the dimensions of the dataprint (train_df.count(), len(train_df.columns))print (test_df.count(), len(test_df.columns))7.设置数据类型
下一步是为数据框中的每一列分配一种数据类型。为此,我们将各列转换为适当的数据类型(例如Integer,Double,String等)。下面的代码将列列表转换为Integer数据类型。
from pyspark.sql.types import IntegerTypeif len(int_list) > 0: for f in int_list: df = df.withColumn(f, df[f].cast(IntegerType()))8.可视化数据
Apache Spark没有用于数据可视化的原生模块。因此,为了可视化我们的数据,我们需要将Spark Dataframes转换为另一种格式。我们可以在PySpark中应用的直接方法是将PySpark Dataframes转换为Pandas Dataframes。为了以有效的方式进行这种转换,我们选择要可视化的数据特征集,以Pandas DF的方式获取之。以下函数使用SQL查询获取Pandas DF。
def get_pandasdf_from_sparkdf(spark_df, view_name, query): ''' This function queries Spark DF, and returns the result table as Pandas DF INPUTS: @spark_df: Spark Dataframe to be queried @view_name: name of SQL view to be created from Spark Dataframe @query: SQL query to be run on @spark_df OUTPUTS: SQL view of @query in Pandas format ''' spark_df.createOrReplaceTempView(view_name) return spark.sql(query).toPandas()获得Pandas版本的数据后,我们可以使用matplotlib库轻松地对其进行可视化。
# set SQL query for dataframe dfsqlQuery = """ SELECT cycle, setting1, setting2, setting3, s1, s2, s3, s4, s5, s6, s7, s8, s9, s10, s11, s12, s13, s14, s15, s16,s17, s18, s19, s20, s21 FROM df1 WHERE df1.id=15 """
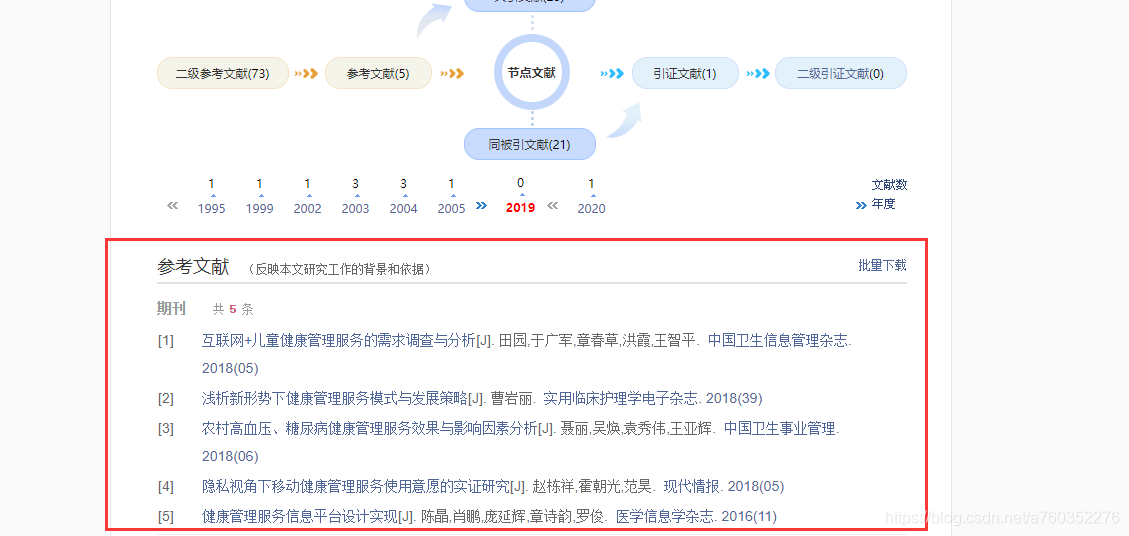
# get SQL query result as Pandas DFplotdata1 = get_pandasdf_from_sparkdf(train_df, "df1", sqlQuery)下图显示了训练数据集中15号发动机的特征随时间的变化。
正如我们从上面的图表中看到的那样,测试数据具有随时间没有变化或变化很小的特征。这种类型的特征在构建预测数据模型中几乎没有用。因此,我们将通过删除低方差特征来开始本教程的下一篇文章。
9.完整代码
可以在我的Github中https://github.com/boutrosrg/Predictive-Maintenance-In-PySpark中找到本教程的代码。(该代码经测试,仅仅print函数需要加括号,其它代码不需要修改,能顺利运行通过)
P.S.
其实使用spark.read_csv可以更方便快速地获得Spark Dataframes,有兴趣的可以自己尝试下,如果想更多了解Spark Dataframe,可以参考PySpark 之Spark DataFrame入门
![王者服务器维护段位掉了,王者荣耀s13赛季段位掉段规则 s13段位重置掉段继承表[图]...](https://img-blog.csdnimg.cn/img_convert/d4da7d7512f50d9663f8fdd6c4815006.png)