目录
S13.1Supervised vs Unsupervised Learning
S13.2生成模型Generative Model
S13.2.1Fully visible belief network
S13.2.3变分编码器(Variational Autoencoders ,VAE)
S13.2.4对抗生成网络(Generative Adversarial Networks ,GAN)
S13.1Supervised vs Unsupervised Learning
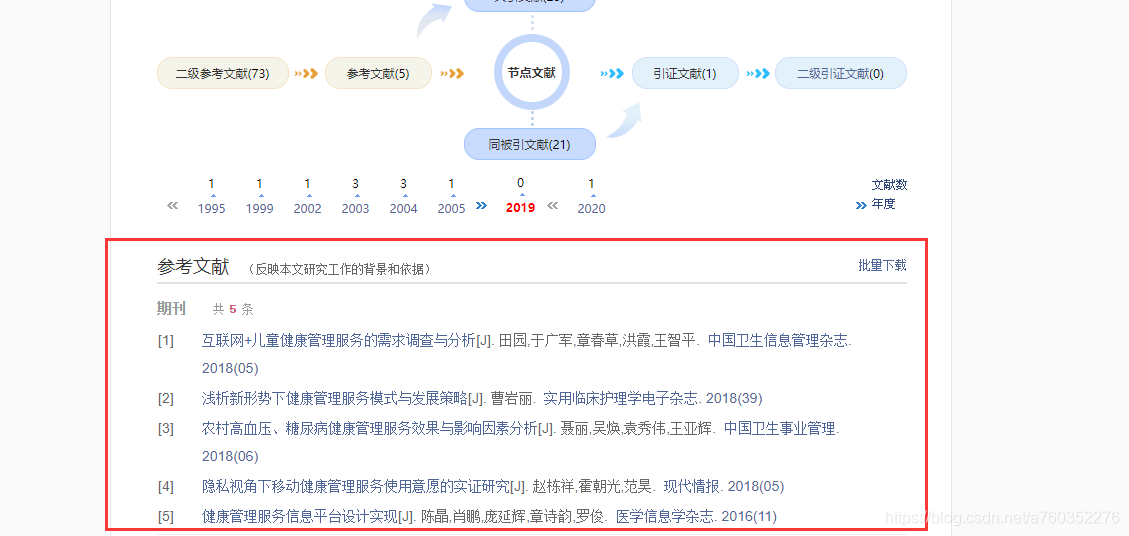
机器学习中,依据数据x是否有标签y,将任务分为有监督学习(有y)和无监督学习(没有y),下图是两种方法简要比较。

S13.2生成模型Generative Model
生成模型是无监督学习范畴下的一类模型。给定训练集X,该模型学习X的分布,最终从相同的数据分布中生成新的数据,如下图所示。 有训练数据,是由某种分布p-data中生成的。然后从中学到一个模型p-model,来以相同的分布生成样本。也就是说,学习到的p-model和p-data尽可能的相似。

X的数据分布/密度估计是无监督学习的核心问题。生成式模型可以解决密度估计问题。依据是否显式学习X的密度,将生成模型其分为显式密度方法和隐式密度方法,如下图所示。本节主要对PixelRNN/CNN,变分自编码(Variational Autiocoder,VA),GAN三个常见的模型进行简要介绍。

生成模型有以下好处:
- 用于艺术品、超分辨率、着色等的逼真样品;
- 时序数据的生成模型可用仿真和规划(强化学习应用);
- 训练生成模型也可以推理潜在的数据表示,可以作为有用的一般特征。
S13.2.1Fully visible belief network
Fully visible belief network:模型对一个密度分布p(x)显式建模。利用链式法则将一张图像x的似然函数p(x)分解为一维分布的乘积。x的似然函数如下所示。其中n为图片x像素的个数,为第i个像素的值。
模型的训练目标是最大化训练数据X的似然函数。注意,模型需要定义"previous pixels"的顺序。当X的分布复杂时,可以使用神经网络来进行表示,如PixelRNN/PixelCNN。这两个模型定义了可解释的密度函数,训练时优化X的似然函数。
PixelRNN:论文[van der Oord et al. 2016]。模型从左上角点开始生成图像像素。某个像素的生成依赖先前生成的像素。像素由RNN/LSTM网络生成。
PixelCNN:论文[van der Oord et al. 2016]。模型从角点开始生成图像像素。在像素附近的区域上,使用CNN网络来生成像素。模型会比PixelRNN快一点,但像素还是顺序生成,所以还是比较慢。
PixelCNN/PixelRNN优缺点:
- 优点:可以显式计算x的似然概率p(x);训练数据的显式似然函数给出了良好的评价指标;生成的样本好。
- 缺点:像素是顺序生成,模型比较慢。
S13.2.3变分编码器(Variational Autoencoders ,VAE)
Autoencoders(AE):AE用于从未标记的训练数据中学习低维特征表示的无监督方法。该模型由编码器和解码器组成。编码器生成输入数据的特征z。一般来说z的维度比x要小。因为想要z捕捉到数据中有意义的变化因素的特征。而且编码器和解码器的构成应该是对称的,例如编码器是卷积层,那么解码器是反卷积层。在训练时,比较x和重建后x的距离,使得重构数据像素和输入数据像素一样。训练完成后,使用编码器来得到x的特征。AE可以重建数据,并可以学习数据的低维特征表示。

VAE:论文"Auto-Encoding Variational Bayes"。VAE是通过向AE加入随机因子获得的一种模型。VAE模型用于从X中学习数据分布,生成符合X分布的新的样本。模型使用潜在向量z,z的元素要捕捉的信息是在训练数据中某种变化因子的多少。z的元素可能是某种类似于属性的东西。设置关于z的先验分布中采样。高斯分布就是一个对z中每个元素的一种先验假设。模型定义不可解释的密度函数:
该函数不能直接优化,所以在似然上推导并优化下界。因此模型在训练时,优化似然的变分下界。编码器网络也是一种识别或者推断网络,因为我们是在给定x的条件下形成对隐变量z的推断。而解码器网络,用来执行生成过程。

训练完之后,使用解码器网络,z从设定好的先验分布中采样,来生成样本。

VAE优缺点:
- 优:生成模型的原则方法;允许推理的q(z|x),可以是有用的特征表示为其他任务。
- 缺:最大似然下界,但不如PixelRNN/PixelCNN容易评估;与最先进的GANs相比,样品更模糊,质量更差。
S13.2.4对抗生成网络(Generative Adversarial Networks ,GAN)
GAN模型:论文"Generative Adversarial Nets"。模型分为生成网络和判别网络。生成网络尽力去生成逼真的图像来欺骗判别器,判别网络尽力去判别图片是真的还是生成器生成的。模型如下所示。生成网络一般由卷积神经网络构成。

GAN的目标函数:目标函数如下。g为生成网络,d为判别网络。

GAN的训练过程:采用博弈论方法进行训练。判别器和生成器进行交替训练。先训练判别器,再训练生成器。k的选择一般是1,但有时也选择大于1。z的先验函数有高斯函数等。训练结束之后,使用生成器来生成新的图片。

GAN的优缺点:
- 优点:生成的样本最佳。
- 缺点:训练不稳定,难以训练;不能直接进行推断查询,例如p(x),p(z|x)。
GAN的相关网络:
- GAN的相关模型:https://github.com/hindupuravinash/the-gan-zoo
- GAN网络训练技巧:https://github.com/soumith/ganhacks
![王者服务器维护段位掉了,王者荣耀s13赛季段位掉段规则 s13段位重置掉段继承表[图]...](https://img-blog.csdnimg.cn/img_convert/d4da7d7512f50d9663f8fdd6c4815006.png)