作者:金雪锋
链接:https://www.zhihu.com/question/456443707/answer/1856014437
这次HDC大会,华为联合鹏城发布了两个千亿的NLP大模型(其中一个模型还和循环智能进行了合作),都是盘古命名的。
一个是4月25日发布的Transformer encoder-decoder的中文理解模型;另外一个4月26日发布的是Transformer decoder的中文预训练模型。这两个模型是不同的定位,也是分别训练出来的。其中第二个预训练模型现在已经开源出来了。
这种超大的模型考验的是全栈和全流程的能力:
1、丰富的数据集和良好的数据清洗
2、硬件系统:芯片、互联、整机
3、硬件使能:高性能的算子库和融合能力
4、AI框架:分布式并行、编译优化
5、AI使能平台:资源管理和调度
6、优秀的算法和模型设计
7、全面的系统工程:包括精度调优、性能调优、模型切分、集群可靠性等等
只有这些能力都达到一流/没有短板,你才能训练出这样的大模型,否则即便给你K级集群,你也用不起来。所以这两个千亿模型训练出来是鹏城、华为EI/智能计算/海思/诺亚实验室/中央软件院等通力协作的结果。
MindSpore作为AI框架有幸同时支撑了这两个千亿模型的训练,过程其实非常艰辛,但总算熬过来。下面就简单介绍一下作为AI框架支撑千亿模型的挑战和解决方案:
挑战:
千亿参数,
TB级显存的模型以盘古2000亿(基于Transformer decoder结构的预训练模型)为例,如果我们训练时权重都用标准的 FP32 数据格式,那么算下来,权重占的空间就达到了 750GB,训练过程中内存开销还会数倍上升。这 750GB 参数,不是放在硬盘上,也不是加载到内存中,而是需要移到昇腾基础硬件平台 HBM(High Bandwidth Memory高带宽存储器)内存中,以利用昇腾基础软硬件平台进行模型训练。
模型大 ,意味着数据也大,而且都需要是高质量数据。为了满足数据需求,研发团队从互联网爬取了80TB文本,并最后清洗为1TB的中文数据集。
这样的模型与数据,已经不是我们几台服务器能加载上的了,更不用说进行训练。好在研发团队会提供 API,一般算法工程师直接调用接口就能试试效果。
 图注:盘古千亿模型架构。
图注:盘古千亿模型架构。
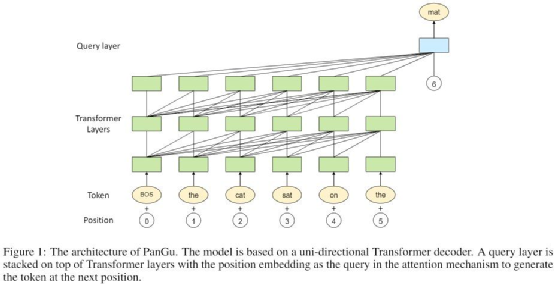 图注:盘古 2 千亿模型架构。
图注:盘古 2 千亿模型架构。
超大规模并行
如果给你足够的计算力,你能想到如何训练这么大的模型吗?我们最常用的分布式训练方式数据并行,单独这么做肯定是不行的,因为没有哪个 计算硬件能放下 800GB 的参数。那么再加上模型并行呢?又产生了新问题,我们该如何拆分如此巨大的「盘古」?硬件产品(如GPU等)之间的梯度流、数据流通信又是什么样的?
显然训练如此庞大的模型,远比我们想象中的复杂,需要大量的工程化操作,并保证这些操作不会或极少影响到模型最终收敛效果。
如果手动来写分布式训练逻辑,那么需要综合考虑计算量与类型、集群带宽、拓扑结构、样本数量等等一大堆复杂的东西,然后再设计出性能比较优秀的并行切分策略,并编写大量并行切分和节点间的通信代码。如果系统环境变了,还要重新设计并修改算法,想想就觉得头大。
MindSpore的解决方案
5 大维度的并行能力
MindSpore提供了5维的并行方式:数据并行、算子级模型并行、Pipeline模型并行、优化器模型并行和重计算,并且在图编译阶段,有机融合了5个维度的并行。这5维并行方式组合起来构成了盘古的并行策略。

1、数据并行
数据并行是最基本,应用最广的并行方式,其将训练数据(mini-batch)切分,每台设备取得其中一份;每台设备拥有完整的模型。在训练时,每台设备经过梯度计算后,需要经过设备间的梯度同步,然后才能进行模型参数的更新。
2、算子级模型并行
算子级模型并行是对模型网络中的每个算子涉及到的张量进行切分。MindSpore对每个算子都独立建模,每个算子可以拥有不同的切分策略。
以矩阵乘算子MatMul(x, w)为例,x是训练数据,w是模型参数,两者都是二维矩阵。并行策略((4, 1), (1, 1))表示将x按行切4份,保持w不切,如果一共有4台设备,那么每台设备拥有一份x的切片,和完整的w。
3、Pipeline 模型并行
Pipeline模型并行将模型的按层分成多个stage,再把各个sage映射到多台设备上。为了提高设备资源的利用率,又将mini-batch划分成多个micro-batch,这样就能够使得不同设备在同一时刻处理不同micro-batch的数据。
一种Pipeline并行方式(Gpipe) 要求反向计算要等所有设备的正向计算完成后才开始,而反向计算可能依赖于正向的输出,导致每个卡正向计算过程中累积的activation内存与micro-batch数量成正比,从而限制了micro-batch的数量。MindSpore的Pipeline并行中,将反向提前,每个micro-batch计算完成后,就开始计算反向,有效降低activation存储时间,从而提升整体并行效率。
 4、优化器模型并行
4、优化器模型并行
优化器模型并行将优化器涉及到的参数和梯度切分到多台设备上。以Adam优化器为例,其内部可能有多份与权重同等大小的“动量”需要参与计算。在数据并行的情况下,每个卡都拥有完整的“动量”,它们在每个卡上都重复计算,造成了内存及计算的浪费。通过引入优化器并行,每个卡只保存权重及“动量”的切片,能降低每个卡的静态内存及提升计算效率。
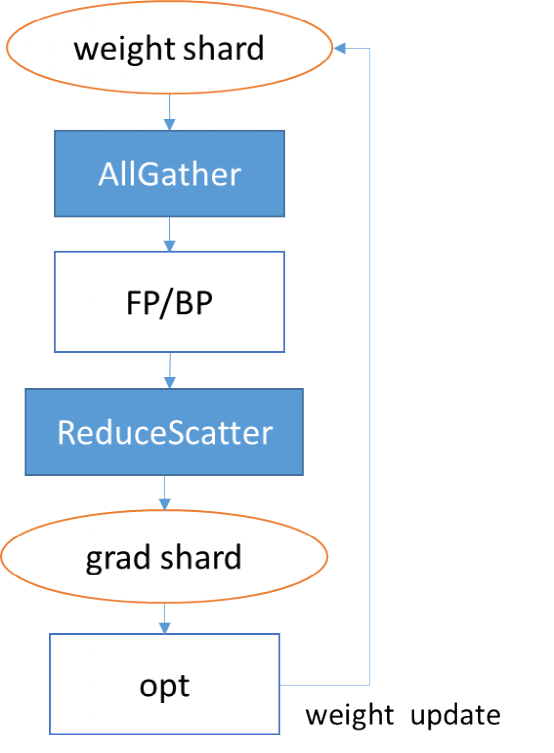
5、重计算
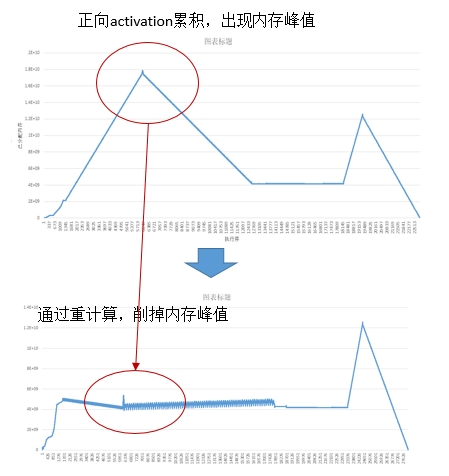
重计算(Rematerialization)针对正向算子的输出累计保存在内存中,导致内存峰值过大的问题,舍弃了部分正向算子的输出,而是在反向阶段用到时再重新计算一遍。这样做有效地降低了训练过程中的内存使用峰值。如下图所示,第一个内存峰值通过重计算消除,第二个内存峰值可以通过前面讲到的优化器并行消除。

有了这5维的并行维度后,如何将其组合起来作用于盘古,并且如何将切分后的模型分片分配到每台设备上仍然是难题。MindSpore自动并行,把这5个维度并行有机组合起来,可以实现非常高效的大模型分布式训练能力。
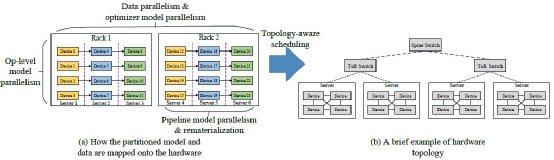
下图(b)是一典型的树形的硬件拓扑结构,其带宽随着树深度的增加而降低,并且会产生一些流量冲突。为了利用此特征,MindSpore的目标是最大化计算通信比,将通信量大的并行方式(算子级并行)放置在服务器内部的多卡之间;将通信量较小(Pipeline并行)的放置在同一机架内的服务器间;将数据并行(优化器并行)的部分放置在不同机架间,因为该通信可以和计算同时执行(overlap),对带宽要求较低。
在盘古2000亿模型中,MindSpore将64层(layer)划分为16个stage,每个stage包含4层。在每层中,利用算子级并行的方式对张量进行切分。
如下图中的Q,K,V的参数在实际中(按列)被切了8份,输入张量(按行)被切了16份,输出张量因此被切了128份(8*16)。重计算配置是配置在每层内的,也就是重计算引入的多余的计算量不会超过一层的计算量。总计,MindSpore使用了2048块昇腾处理器来训练盘古。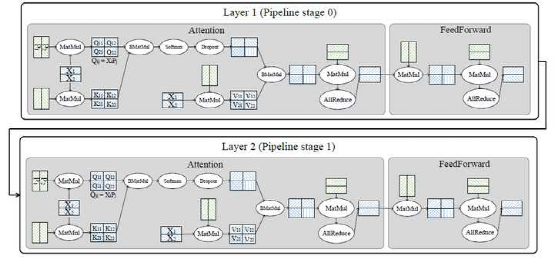
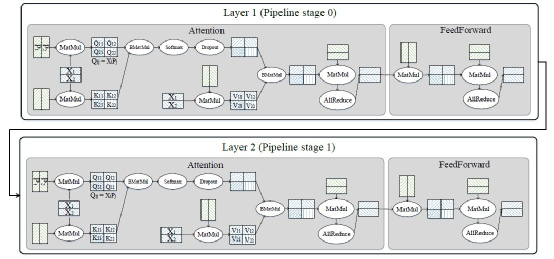
MindSpore对外屏蔽了复杂并行实现的细节,使得用户像编写单机模型脚本那样简单。用户在单机脚本的基础上,仅通过少了配置就能实现多维度的混合并行。下图是简化版的盘古脚本,其中红色加粗字体表示的在MindSpore中的并行策略。将红色加粗字体去掉,则是单机脚本。

图算跨层联合优化,发挥硬件极致性能
除了跨节点间的大规模自动外,在单卡节点内,MindSpore通过图层和算子层的跨层协同优化,来进一步发挥昇腾算力。
在传统的NN网络中,不同算子承载的计算量和计算复杂度也各不相同。如LayerNorm由11个基本算子组成,而Add则只有1个基本算子。这种基于用户角度的算子定义,通常是无法充分发挥硬件资源计算能力的。因为计算量过大、过复杂的算子,通常很难生成切分较好的高性能算子。从而降低设备利用率;而计算量过小的算子,由于计算无法有效隐藏数据搬移开销,也可能会造成计算的空等时延,从而降低设备利用率。
为了提升硬件利用率,MindSpore使用了图算融合优化技术,通过图层和算子层联合优化,并将“用户使用角度的易用性算子”进行重组融合,然后转换为“硬件执行角度的高性能算子”,从而充分提升硬件资源利用率,进而提升整网执行性能。具体优化流程如下图所示:

以LayerNorm算子为例,通过算子拆分和重组,11个小算子,组成了1个单算子和2个融合算子。这些重组后的算子可以生成更加高性能的算子,从而大大降低了整体网络运行时间。

在盘古模型中,图算融合帮助整体训练时间减少了20%以上。除此之外,对于其它 NLP、CV等任务,图算融合在优化性能方面都有不错的表现。
总结一下
即使给我们足够的算力,超大模型的训练还是异常复杂,远比想象中的困难。对于我们一般算法工程师来说,针对某个任务,上亿参数量已经算大的了,但是并不会感到训练上会有什么困难,因为各个深度学习框架直接调用数据并行接口就能搞定。
但是如果模型继续增大到百亿级、千亿级甚至万亿级,并行与优化策略的复杂度猛然上升,算法工程师一点点地编写与优化代码可太难了。MindSpore通过编译器并行优化能力,把计算逻辑和并行逻辑解耦,单卡串行代码自动实现分布式并行,从而使得算法科学家将精力都解放到模型本身上。
为了从预训练获取更多的知识, GPT-3 与盘古 这样的模型会越来越大,毕竟到现在我们还没看到大模型预训练效果的极限在哪。届时,这类模型对基础设施的需求会更大,并行与优化策略也会更加复杂。预训练的效果,看的也已经不是模型本身,而是基础设施构建得是否足够优秀。大规模计算集群及软硬件协同优化,这次在盘古 的训练上得到了充分的完美体现。
当然,也诚如以上所言,盘古只是对超大规模分布式训练、超大规模中文预训练模型的一次探索,未来还需要更多的研究工作者投入到通用智能与大规模分布式计算的研究工作中。
往期精彩回顾适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: