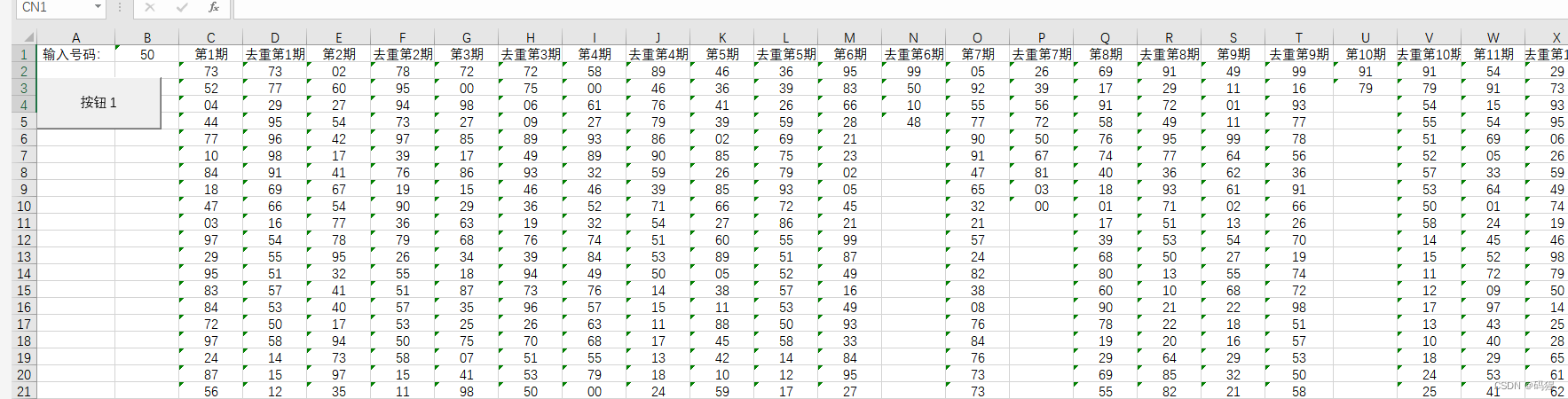
python爬虫好久没用都生疏了,刚好朋友要排列三数据,就用这个练手,
去体彩官网http://www.lottery.gov.cn/historykj/history.jspx?_ltype=pls
不闲聊,直接上代码
import requests
from requests.exceptions import RequestException
import csv
from bs4 import BeautifulSoup as bs
数据存储到csv
def write_to_file(item):
file_name = ‘PLS.csv’
# ‘a’为追加模式(添加)
# utf_8_sig格式导出csv不乱码
with open(file_name, ‘a’, encoding=‘utf_8_sig’, newline=’’) as f:
fieldnames = [‘期号’, ‘中奖号码’, ‘开奖日期’]
w = csv.DictWriter(f, fieldnames=fieldnames)
w.writerow(item)
def get_page(i):
try:
# 这是一个UA伪装,告诉网站你浏览器和操作系统系统
headers = {
‘User-Agent’: 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ’
‘Chrome/66.0.3359.181 Safari/537.36’,
‘Connection’: ‘keep-alive’
}
url = "http://www.lottery.gov.cn/historykj/history_" + str(i) + ".jspx?_ltype=pls"response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:print('return code is %s' % (str(response.status_code)))return Noneexcept RequestException:print('访问异常')
def parse_one_page(get_html):
pls = {}
data = bs(get_html, ‘lxml’)
data = data.find(‘tbody’).find_all(‘tr’)
for content in data:all_tr = content.find_all('td')pls['期号'] = all_tr[0].get_text()pls['中奖号码'] = all_tr[1].get_text()pls['开奖日期'] = all_tr[10].get_text()write_to_file(pls)
def crawler():
for i in range(1, 275):
parse_one_page(get_page(i))
if name == ‘main’:
crawler()
测试结果,一条不差

我按朋友的要求,只取了期号,中奖号码,开奖日期
有需要其他列的数据,自己修改下就能用