今天我们来说说Blazor选择语句和循环语句。
下面我们以一个简单的例子来讲解相关的语法,我已经创建好了一个Student类,以此类来进行语法的运用

因为我们需要交互性所以我们将类创建在*.client目录下
@ if
我们做一个学生信息的显示,Gender为0时显示男,为1时显示女,我们的代码可以这样写
@page "/StudentInfo"
@rendermode InteractiveAuto
<h3>StudentInfo</h3><table><thead><tr><th>Name</th><th>Age</th><th>Gender</th></tr></thead><tbody><tr><td>@student.Name</td><td>@student.Age</td>@if (student.Gender == 0){<td>男</td>}else{<td>女</td>}</tr></tbody>
</table>@code {Student student = new Student(){Name = "John",Age = 20,Gender = 0,};
}
看看效果

@ Switch
我们的需求发生了变化,Gender添加了2,当Gender为2时,显示未知。
@page "/StudentInfo"
@rendermode InteractiveAuto
<h3>StudentInfo</h3><table><thead><tr><th>Name</th><th>Age</th><th>Gender</th></tr></thead><tbody><tr><td>@student.Name</td><td>@student.Age</td>@switch(student.Gender){case 0:{<td>男</td>break;}case 1:{<td>女</td>break;}case 2:{<td>未知</td>break;}}</tr></tbody>
</table>@code {Student student = new Student(){Name = "John",Age = 20,Gender = 2,};
}
效果如下

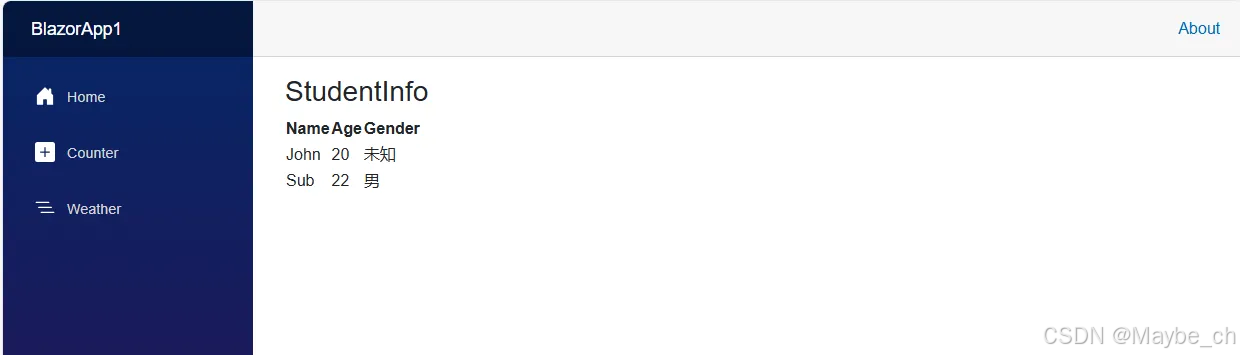
@ foreach
下面我们有一个list需要显示多个学生信息,@for,@do…while,@while 与foreach类似这里就不在赘述
@page "/StudentInfo"
@rendermode InteractiveAuto
<h3>StudentInfo</h3><table><thead><tr><th>Name</th><th>Age</th><th>Gender</th></tr></thead><tbody>@foreach (var item in list){<tr><td>@item.Name</td><td>@item.Age</td>@switch (item.Gender){case 0:{<td>男</td>break;}case 1:{<td>女</td>break;}case 2:{<td>未知</td>break;}}</tr>}</tbody></table>@code {List<Student> list = new List<Student>();Student student1 = new Student(){Name = "John",Age = 20,Gender = 2,};Student student2 = new Student(){Name = "Sub",Age = 22,Gender = 0,};protected override void OnInitialized(){list.Add(student1);list.Add(student2);}
}
下次我们将继续讲解语法相关的内容,欢迎大家的关注



![[ACTF2020 新生赛]Upload1](https://i-blog.csdnimg.cn/direct/065a9b3ad6d64f58865cbd6e4a650aa5.png)
![SpringMVC新版本踩坑[已解决]](https://i-blog.csdnimg.cn/direct/9f7ca3b9fb7c40eca1d9bbfd6e863dc7.png)