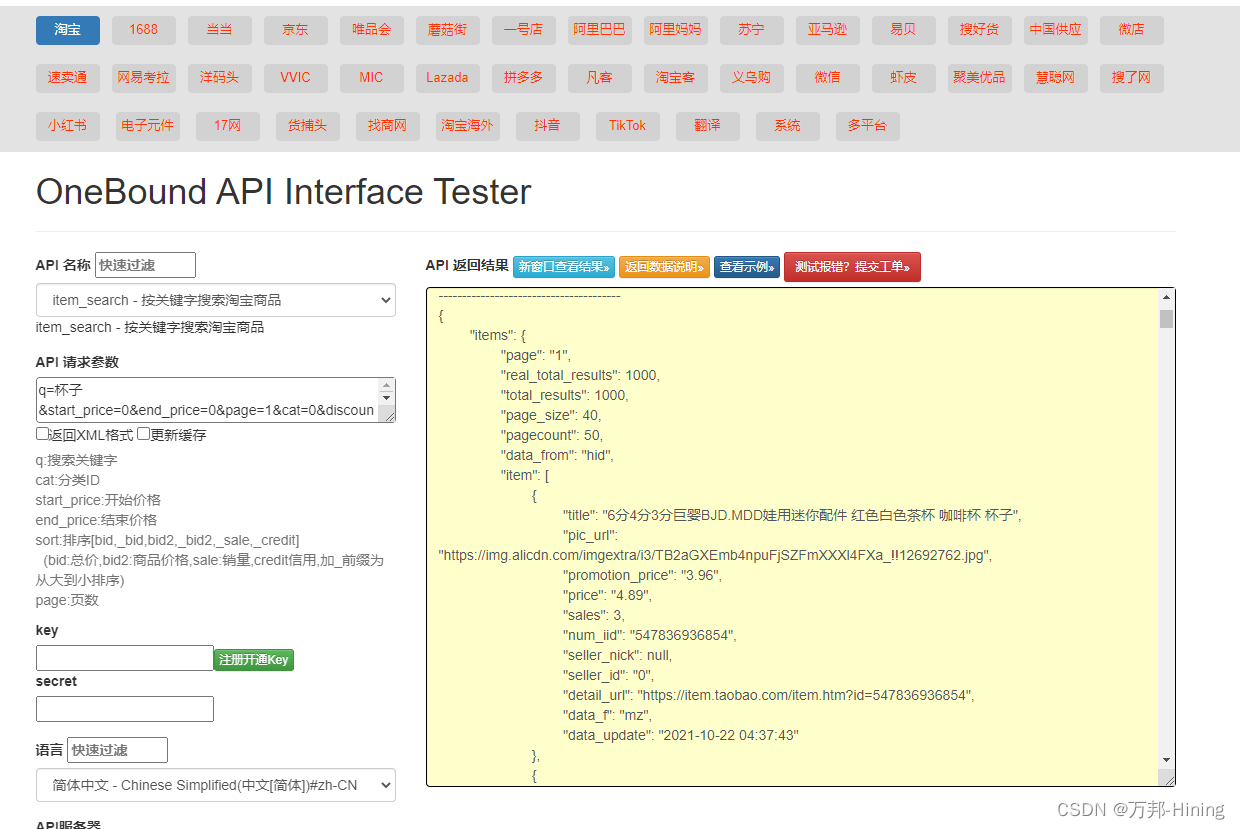
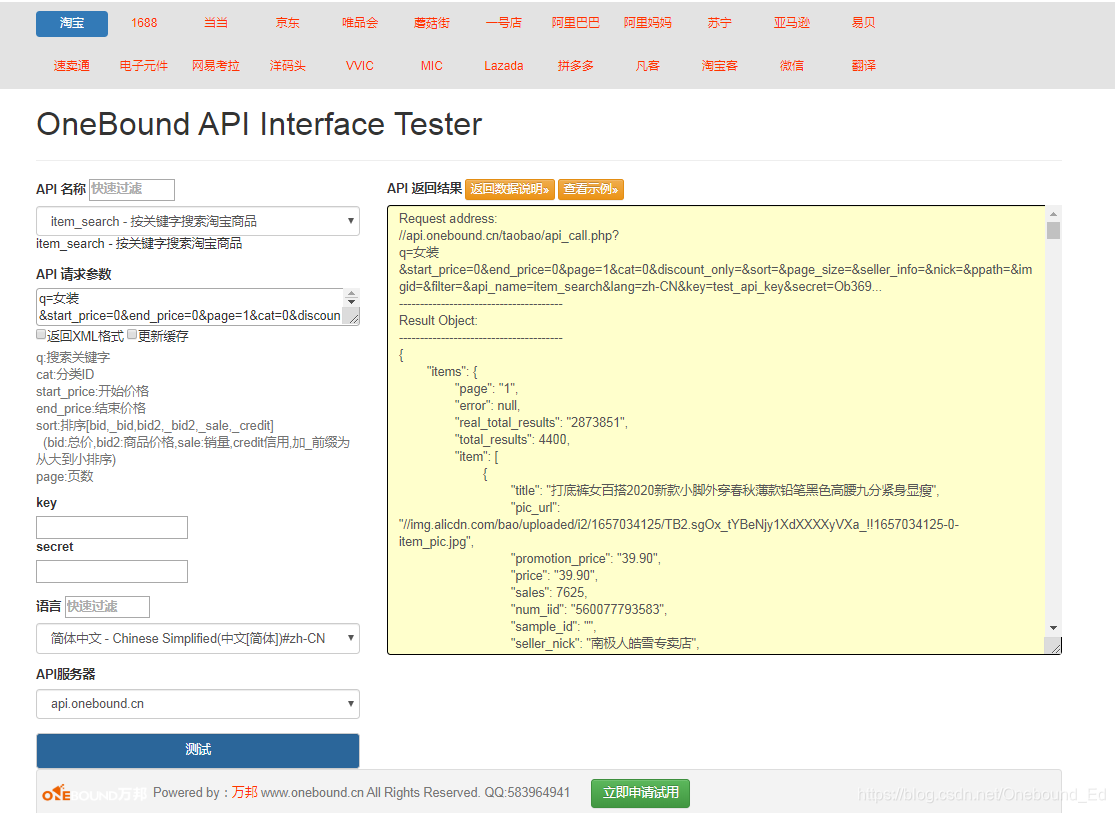
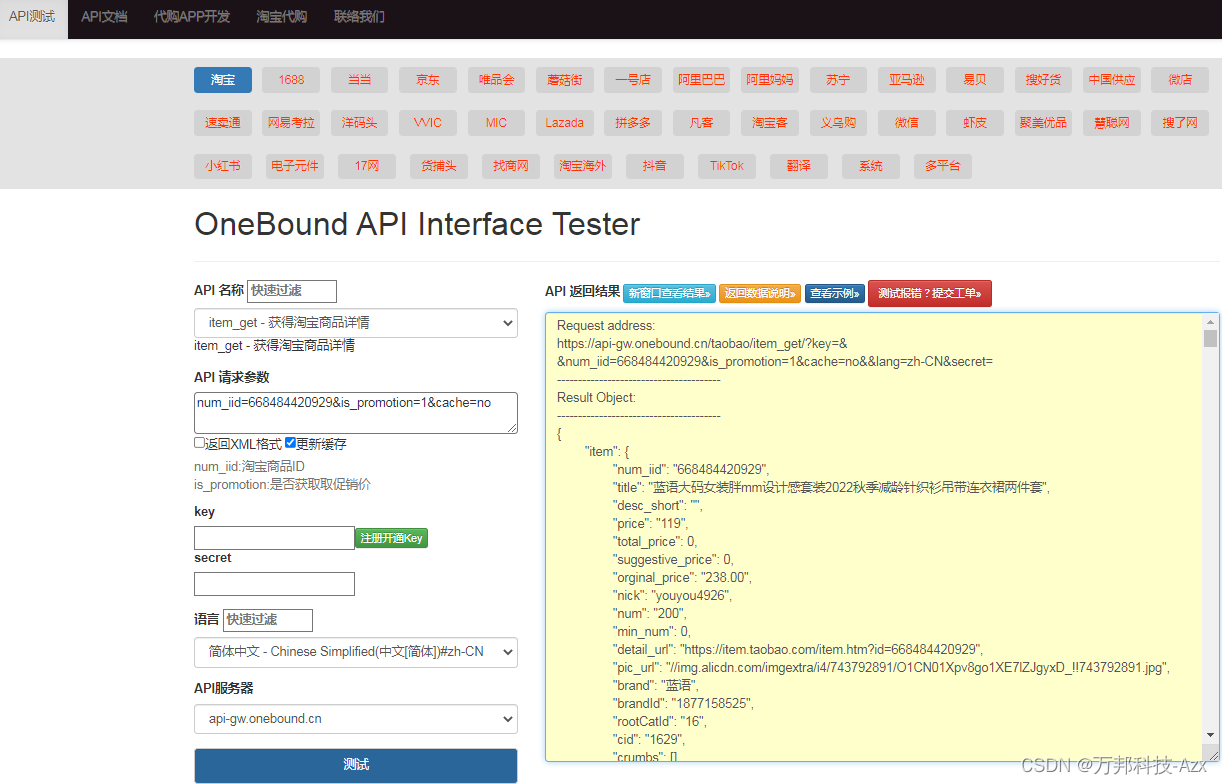
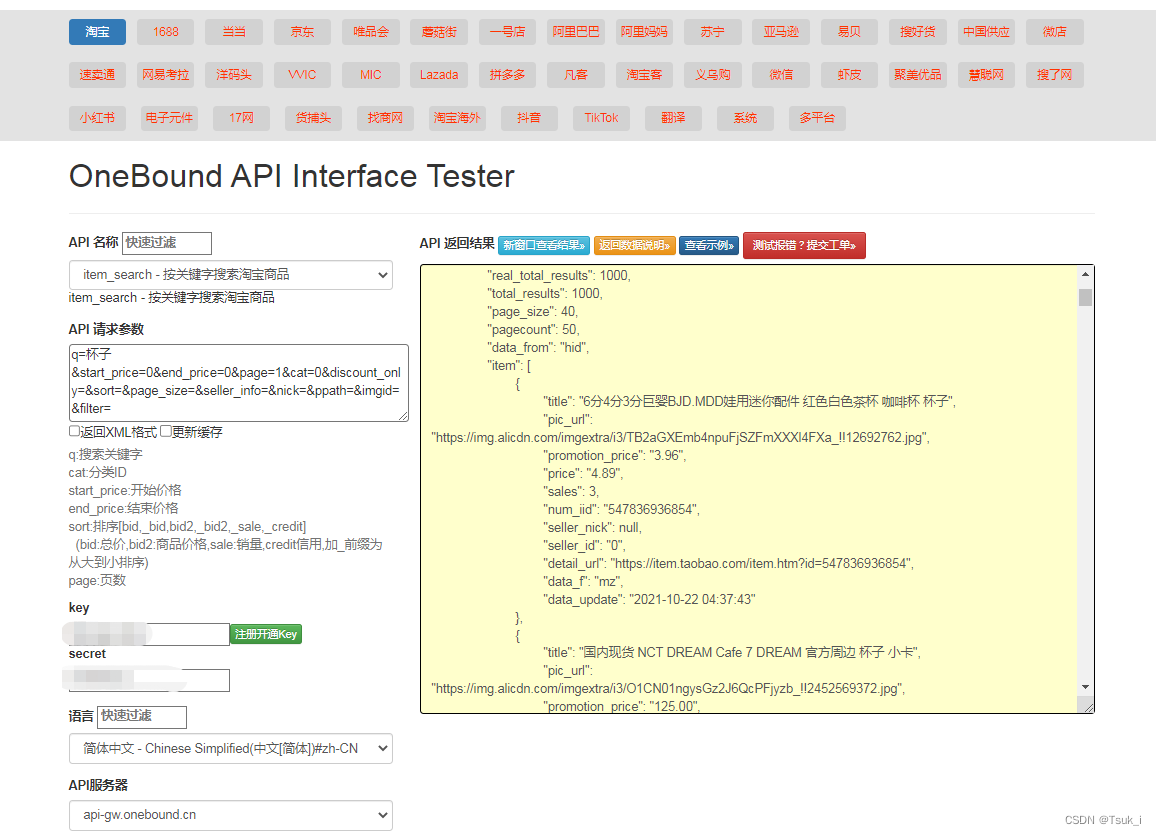
第一篇文章
一、序列特征处理方式
1:淘宝的类目体系中,有大类目、小类目(淘宝大类目和小类目怎么区分?有何运营技巧?-卖家网),在做推荐系统时,有个sim建模(search-based interest model),或者说是长序列建模时先需要根据类目来做hard search,就需要用到类目。对于大类目一般用二级类目来检索(没有得到官方说明,通过查看淘宝app中分类这个icon页中的信息,大类目可能会是食品、男装、女装这种,假如是女装的话,一二级类目举个例子为:上装->衬衫),小类目一般用一级类目来检索(奢品、车品这种,假如是奢品的话,一级类目为:女鞋女装、箱包配饰等)
2:类目检索序列,就是用上面的方法对“某某序列”进行检索,在体验业务的时候,这些序列应该有这几种,首先肯定用到的有:曝光序列(但是曝光序列一般不能直接用,会用负反馈方式来设计)、点击序列、购买序列、加购序列、搜索词序列(搜索词序列因为涉及到文本,而且非item序列,可以根据nlp方式先筛选出来相关的序列,比如bert,或者经典的word2vec,但是淘宝的搜索词经常有很多长词,怎么处理也是个设计点。这个过程耗时很多,一般不能直接使用,比如采用预处理的方式,在请求进行到精排时,除了user-fs、item-fs外,再并行单独一台链路来处理用户搜索词序列和精排item。这个博主也只是个设想,并没有见到实际应用过)。上面提到的这些序列都是全场景序列,具体到每个子场景中,比如猜你喜欢、详情页推荐中可能会在特征中加入自己子场景的序列
3: 精排:看一些文章中讲序列建模时,有下面这样的图,我理解首先对于点击序列是和预估item做了attention,其次对点击序列利用预估item做完类目检索后(假设点击序列是30长度,和预估item同类目的有13个,那么检索后的长度是13)也和预估item做了attention,这两个特征抽取是同时存在于模型中的

4:粗排不能像上面的精排一样,每个预估Item都做attention,因为粗排的数量是1万+,所以只能做self attention,用来高度抽取序列信息。要是做item_target_attention的话,性能怎么样都是扛不住的
首先有一个概念:不管离线模型结构怎么样设计,肯定是离线就做好user、item的向量,然后线上直接做查询+排序
如下图,左边结构是简单的“双塔模型”,任何团队在最开始迭代的时候都是这种做法,这里有一个稍特殊的做法:其中对序列特征做的是self attention,做完self_attention后把user作为了attention的query,首先对耗时没有什么影响,因为离线可以把这个结构加到模型中去,然后得到对应的向量(如果是离线做的话,就没有实时特征一说了);其次这样一种attention结构对用户click seq做了加权,效果一般会好
可能是想拿到cate_attention这种收益(在精排上已经验证是很有效的,sim),所以增加了左边这个结构,淘宝的用户体系在30亿左右,日活在3.5亿左右,不用对着3.5亿用户都存储在每种cate上的向量,只需要做过去N天(比如60天活跃),cate也是选择交互过的cate,这样做出来的kkv表,数据量就不是特别大了,可以满足线上性能,再把emb维度缩小点,这样性能会更好一点

博主这个专栏记录”沉浸式推荐算法“工作经验,博主先后做过推荐算法、搜索广告算法,现在从事”沉浸式推荐算法“也为咱们程序员做了一个专属的小程序:猿媛-程序员一站式服务,还没正式上线(也可以试着搜索,后面哪天
说不定就突然上线了),在开发内测中主要有技术博客、程序员行业短视频、行业热点、你的朋友圈、it公众圈、每个细分行业的论坛、
解决我们的老大难相亲问题、各大互联网公司的招聘、我们it人的专属好物...这些功能,
想要一起来做的加微信(微信名:ranksearch,或者扫下面的码),最好是加微信群,
大家一起商量来做(加微信拉你,或者扫下面的码),开发、产品设计、运营推广都可以。
博主这些自己都会,所以先开发上线+运营着,但是每个方向要是能有更专业的人来做肯定更好,
希望真的爱咱们这个行业的同事们能加入我们,一起做一些一个人做不到的事情!
二、多目标模型
1:淘宝app的种草行为,收藏、加购物车
2:淘宝的一跳、二跳,以猜你喜欢为例,选择一个商品后进行点击,这个过程是一跳

点击了上面这个item后,会进入下面这个页面(这个是淘宝现在有区别于之前的设计,从猜你喜欢、某些导购场景进去后,不会直接是这个item的详细信息,而是同类目的商品信息流;在京东app的猜你喜欢也有这个情况),进到这个页面再点击某些item的话,这个属于二跳

3: 讲解几个电商中常见的指标,以“猜你喜欢”这个为例
pv: 场景内,24小时里所有页面的访问量;ipv:仅仅是pv里面商品详情页的访问量(因为猜你喜欢第一次点击是同类目信息流格式,所以ipv也就是二跳的目标页面);dpv可能是载有广告的pv
click是点击次数;pctr是预估item的ctr;uctr是用户的ctr(比如进入淘宝首页的用户量是3亿,从这里进入淘宝直播宫格的是1亿,那么uctr是0.33);collect是收藏率;cart是加购物车率
grs是种草率(具体可以参考这个文章:5大经典排序算法在淘宝“有好货”场景的实践_阿里巴巴淘系技术团队官网博客的博客-CSDN博客)

CTR、IPV、GRS、CVR这四个指标连贯解释下:在猜你喜欢界面,选择某一个item后点击进去会进到一个同类目的信息流列表中,这个过程是CTR;再从这个列表中选择一个确切的item,点击进到详情页,称为IPV,也就是统计进入详情页的次数;GRS就是收藏、加购这两个种草指标;CVR就是最后的下单购买,也就是GMV
4:精排模型
上面第一部分讲了特征设计,这里的精排模型是在特征设计上面,由1个tower变成了n个tower,而且除了各自tower的全连接参数各自训练外,所有共享的参数只由ctr模型更新
分数混合公式

5:粗排模型
上面第一部分讲解了粗排模型的特征设计、双塔模型设计(分别得到两个user*item的结果,然后再相加作为结果)。因为是多目标要增加一个”种草分数“,基于原先的加购,两个user*item分别是”基础版内积“、”类目检索序列内积“,在增加一个”种草分数“时,就是复制这1个分数(因为”类目检索序列内积“可以复用,所以就只用复制”基础版内积“),将loss改成”种草loss“