THE大学排名
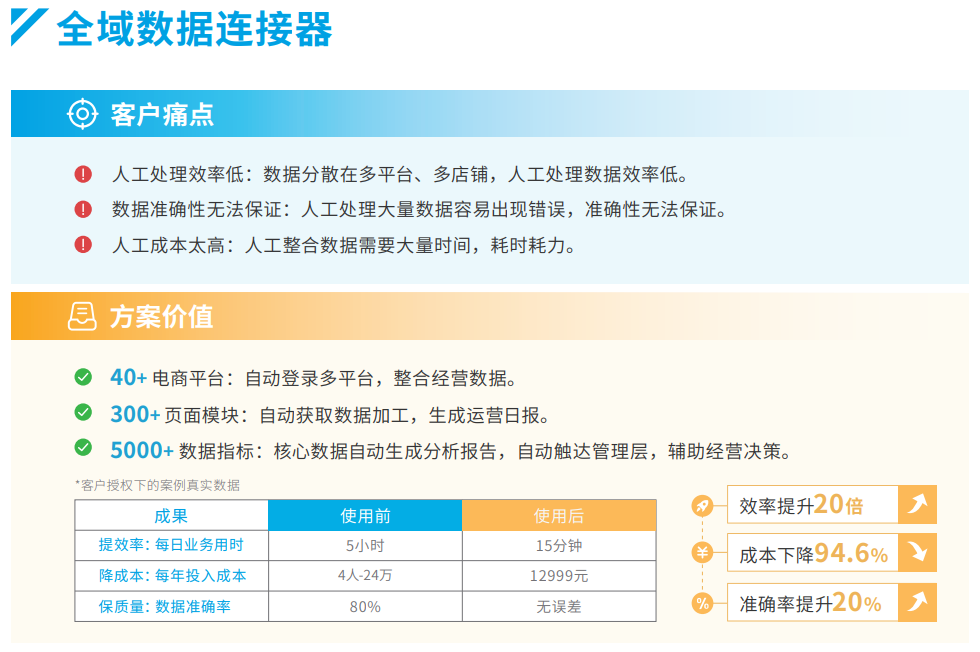
THE大学排名的数据比较容易获取,THE大学排名2022,所有数据都可以在这一个网页中找到。
- “any subject”下拉菜单中可以选择不同学科,如果不选的话那就是综合排名;
- 不需要翻页,一页就是一个学科;
- 每种学科(包括综合排名)排名都可以写入一个excel中;
- 每种学科排名有两个标签栏中的数据需要获取,一个是“Rankings”,一个是“Scores”。

遇到的问题是,“any subject”的“select”是不可见的,所以不能用selemium的Select方法,解决方法就是用js脚本让它显示出来:
#get select object and make it visible
sel = Select(driver.find_element(By.XPATH, '//*[@id="subjects"]'))
js = 'document.querySelectorAll("select")[3].style.display="block";'
driver.execute_script(js)
用这个方法会让网页变得有点鬼畜,但确实是有效的

下面是完整的脚本:
#encoding=utf-8
# THE ranks 2022 for all subjects
from re import I
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
import xlsxwriter
from selenium.webdriver.support.ui import Selectdriver = Edge()
curl = 'https://www.timeshighereducation.com/world-university-rankings/2022/world-ranking#!/page/0/length/-1/sort_by/rank/sort_order/asc/cols/stats'
driver.get(curl)
time.sleep(1)
#get object used to change to status tab
ch2status = driver.find_element(By.XPATH, '//*[@id="stats"]')
#get object used to change to score tab
ch2score = driver.find_element(By.XPATH, '//*[@id="scores"]')
#get select object and make it visible
sel = Select(driver.find_element(By.XPATH, '//*[@id="subjects"]'))
js = 'document.querySelectorAll("select")[3].style.display="block";'
driver.execute_script(js)for q in range(1, 33, 1):#select subjectsel.select_by_index(q-1)#get current select nameOpt = driver.find_element(By.XPATH, '//*[@id="subjects"]/option['+str(q)+']')SubjectName = Opt.textprint(SubjectName + ' start')Workbook = xlsxwriter.Workbook(SubjectName+'.xlsx')Sheet = Workbook.add_worksheet()Sheet.write(0, 0, 'Rank')Sheet.write(0, 1, 'University')Sheet.write(0, 2, 'Location')Sheet.write(0, 3, 'No. of FTE Students')Sheet.write(0, 4, 'No. of Students per Staff')Sheet.write(0, 5, 'International Students')Sheet.write(0, 6, 'Female:Male Ratio')Sheet.write(0, 7, 'Overall')Sheet.write(0, 8, 'Teaching')Sheet.write(0, 9, 'Research')Sheet.write(0, 10, 'Citations')Sheet.write(0, 11, 'Industry Income')Sheet.write(0, 12, 'International Outlook')currentRow = 1while True:try:driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(currentRow)+']')except:breaksubItem = driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(currentRow)+']/td[1]')Sheet.write(currentRow, 0, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(currentRow)+']/td[2]/a')Sheet.write(currentRow, 1, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(currentRow)+']/td[2]/div/div/span/a')Sheet.write(currentRow, 2, subItem.text)for k in range(3,7,1):subItem = driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(currentRow)+']/td['+str(k)+']')Sheet.write(currentRow, k, subItem.text)print(SubjectName + ': ' + str(currentRow) + ' Status finished!')currentRow = currentRow + 1totalItem = currentRowprint('total Item of '+SubjectName+' is '+str(totalItem))driver.execute_script('arguments[0].click();', ch2score)for i in range(1, totalItem, 1):for k in range(3,9,1):subItem = driver.find_element(By.XPATH, '//*[@id="datatable-1"]/tbody/tr['+str(i)+']/td['+str(k)+']')Sheet.write(i, k+4, subItem.text)print(SubjectName + ': ' + str(i)+'/'+str(totalItem-1)+' Score finished!')driver.execute_script('arguments[0].click();', ch2status)Workbook.close()driver.close()软科大学排名
世界大学学术排名
软科的排名数据也比较容易获取,软科世界大学学术排名2021
- 总共1000条记录,需要翻页
- 每个大学的具体指标需要下拉栏选择
翻页按键的XPATH会根据页数不同发生变化,所以采用了动态搜寻的方法;每次先把当前页面的数据拿到,然后逐个更换指标依次获取所有指标。

#encoding=utf-8
# 软科世界大学学术排名 2021
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
import xlsxwriterWorkbook = xlsxwriter.Workbook("软科世界大学学术排名_2021.xlsx")
Sheet = Workbook.add_worksheet()
driver = Edge()Sheet.write(0, 0, '排名')
Sheet.write(0, 1, '学校名称')
Sheet.write(0, 2, '国家/地区')
Sheet.write(0, 3, '国家/地区排名')
Sheet.write(0, 4, '总分')
Sheet.write(0, 5, '校友获奖')
Sheet.write(0, 6, '教师获奖')
Sheet.write(0, 7, '高被引科学家')
Sheet.write(0, 8, 'N&S论文')
Sheet.write(0, 9, '国际论文')
Sheet.write(0, 10, '师均表现')curl = 'https://www.shanghairanking.cn/rankings/arwu/2021'
driver.get(curl)time.sleep(1)
lastRow = 1
for page in range(34):#34 pageprint('page ' + str(page+1))currentRow = lastRowfor itemIndx in range(1, 31, 1):try:subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')except:breaksubItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[1]/div')Sheet.write(currentRow, 0, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[2]/div/div[2]/div')Sheet.write(currentRow, 1, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[3]')Sheet.write(currentRow, 2, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[4]')Sheet.write(currentRow, 3, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[5]')Sheet.write(currentRow, 4, subItem.text)currentRow = currentRow + 1for scoreIndx in range(1, 7, 1):currentRow = lastRowscoreSel = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[1]')driver.execute_script('arguments[0].click();', scoreSel)time.sleep(1)score = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[6]/div/div[1]/div[2]/ul/li['+str(scoreIndx)+']')scoreName = score.textdriver.execute_script('arguments[0].click();', score)time.sleep(1)# print(scoreName)for itemIndx in range(1, 31, 1):try:subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')except:breaksubItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[6]')Sheet.write(currentRow, scoreIndx+4, subItem.text)currentRow = currentRow + 1lastRow = currentRowif page < 33:nextPageLoc = 3while True:nextPage = driver.find_element(By.XPATH, '//*[@id="content-box"]/ul/li['+str(nextPageLoc)+']')# //*[@id="content-box"]/ul/li[9]attr = nextPage.get_attribute('title')if attr == '下一页':breaknextPageLoc = nextPageLoc + 1driver.execute_script('arguments[0].click();', nextPage)time.sleep(1)Workbook.close()
driver.close()
世界一流学科排名
世界一流学科排名对每个学科都有专门的序号,这个序号和对应的网页有关,所以只需要建立一个序号的字典,就可以依次遍历所有的学科网页。在每个网页中类似世界大学学术排名一样处理即可。

#encoding=utf-8
#软科世界一流学科排名 2021
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
import xlsxwriterfp = open('linksTail.txt', 'r')
linksDict = {0:'RS0101', 1:'RS0102', 2:'RS0103', 3:'RS0104', 4:'RS0105', 5:'RS0106', 6:'RS0107',7:'RS0108', 8:'RS0201', 9:'RS0202', 10:'RS0205', 11:'RS0206', 12:'RS0207', 13:'RS0208',14:'RS0210', 15:'RS0211', 16:'RS0212', 17:'RS0213', 18:'RS0214', 19:'RS0215', 20:'RS0216',21:'RS0217', 22:'RS0219', 23:'RS0220', 24:'RS0221', 25:'RS0222', 26:'RS0223', 27:'RS0224',28:'RS0226', 29:'RS0227', 30:'RS0301', 31:'RS0302', 32:'RS0303', 33:'RS0304', 34:'RS0401',35:'RS0402', 36:'RS0403', 37:'RS0404', 38:'RS0405', 39:'RS0406', 40:'RS0501', 41:'RS0502',42:'RS0503', 43:'RS0504', 44:'RS0505', 45:'RS0506', 46:'RS0507', 47:'RS0508', 48:'RS0509',49:'RS0510', 50:'RS0511', 51:'RS0512', 52:'RS0513', 53:'RS0515'}driver = Edge()for linkNum in range(54):url = 'https://www.shanghairanking.cn/rankings/gras/2021/'+linksDict[linkNum]driver.get(url)time.sleep(1)subjectObj = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[1]/div[1]/div[3]')subjectName = subjectObj.textprint('Start of '+subjectName)Workbook = xlsxwriter.Workbook(subjectName+'.xlsx')Sheet = Workbook.add_worksheet()Sheet.write(0, 0, '排名')Sheet.write(0, 1, '学校名称')Sheet.write(0, 2, '国家/地区')Sheet.write(0, 3, '总分')Sheet.write(0, 4, '重要期刊论文数')Sheet.write(0, 5, '论文标准化影响力')Sheet.write(0, 6, '国际合作论文比例')Sheet.write(0, 7, '顶尖期刊论文数')Sheet.write(0, 8, '教师获权威奖项数')lastRow = 1page = 1while True:currentRow = lastRowfor itemIndx in range(1, 31, 1):try:subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')except:breaksubItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[1]/div')Sheet.write(currentRow, 0, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[2]/div/div[2]/div')Sheet.write(currentRow, 1, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[3]')Sheet.write(currentRow, 2, subItem.text)subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[4]')Sheet.write(currentRow, 3, subItem.text)currentRow = currentRow + 1for scoreIndx in range(1, 6, 1):currentRow = lastRowscoreSel = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[5]/div/div[1]/div[1]')driver.execute_script('arguments[0].click();', scoreSel)time.sleep(1)score = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[5]/div/div[1]/div[2]/ul/li['+str(scoreIndx)+']')scoreName = score.textdriver.execute_script('arguments[0].click();', score)time.sleep(1)for itemIndx in range(1, 31, 1):try:subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')except:breaksubItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[5]')Sheet.write(currentRow, scoreIndx+3, subItem.text)currentRow = currentRow + 1lastRow = currentRowprint('page ' + str(page) + ' finished!')page = page + 1nextPageLoc = 3while True:nextPage = driver.find_element(By.XPATH, '//*[@id="content-box"]/ul/li['+str(nextPageLoc)+']')attr = nextPage.get_attribute('title')if attr == '下一页':breaknextPageLoc = nextPageLoc + 1attr = nextPage.get_attribute('aria-disabled')if attr == 'true':breakdriver.execute_script('arguments[0].click();', nextPage)time.sleep(1)Workbook.close()print('End of '+subjectName)driver.close()