用Paddle自动生成二次元人物头像
想画出独一无二的动漫头像吗?不会画也没关系!只需要输入一些随机数让卷积神经网络为你画出精致并且独一无二的动漫头像!
同时本项目也是绝佳的学习DCGAN的例子,通过趣味解读深入浅出地了解GAN的魔法世界!
快开始制作你自己的二次元头像吧!!!
先来看看效果图

欢迎大家fork学习~有任何问题欢迎在评论区留言互相交流哦
这里一点小小的宣传,我感兴趣的领域包括迁移学习、生成对抗网络、。欢迎交流关注。来AI Studio互粉吧等你哦
1 项目简介
本项目基于paddlepaddle,结合生成对抗网络(DCGAN),通过弱监督学习的方式,训练生成二次元人物头像网络
1.1 DCGAN
1.1.1 背景介绍
DCGAN是深层卷积网络与 GAN 的结合,其基本原理与 GAN 相同,只是将生成网络和判别网络用两个卷积网络(CNN)替代。为了提高生成样本的质量和网络的收敛速度,论文中的 DCGAN 在网络结构上进行了一些改进:
- 取消 pooling 层:在网络中,所有的pooling层使用步幅卷积(strided convolutions)(判别器)和微步幅度卷积(fractional-strided convolutions)(生成器)进行替换。
- 加入 batch normalization:在生成器和判别器中均加入batchnorm。
- 使用全卷积网络:去掉了FC层,以实现更深的网络结构。
- 激活函数:在生成器(G)中,最后一层使用Tanh函数,其余层采用 ReLu 函数 ; 判别器(D)中都采用LeakyReLu。
DCGAN的生成器G结构如下图所示:
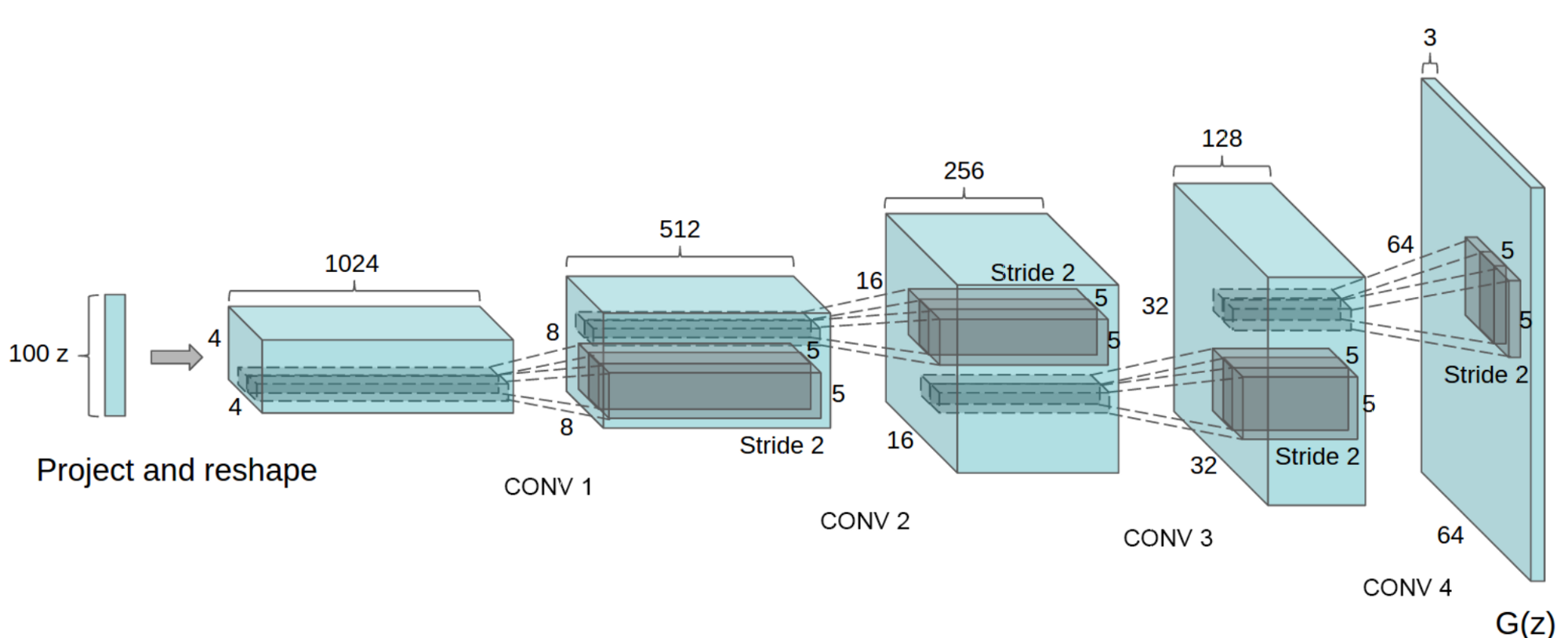
1.1.2 本项目由Chainer项目Chainerで顔イラストの自動生成改写为PaddlePaddle项目
1.2 本文的改进
- 将Adam优化器beta1参数设置为0.8,具体请参考原论文
- 将BatchNorm批归一化中momentum参数设置为0.5
- 将判别器(D)激活函数由elu改为leaky_relu,并将alpha参数设置为0.2
- 在判别器(D)中增加Dropout层,并将dropout_prob设置为0.4
- 将生成器(G)中的第一层全连接层改为基本残差模块
损失函数选用softmax_with_cross_entropy,公式如下:
l o s s j = − logits l a b e l j + log ( ∑ i = 0 K exp ( logits i ) ) , j = 1 , . . . , K loss_j = -\text{logits}_{label_j} +\log\left(\sum_{i=0}^{K}\exp(\text{logits}_i)\right), j = 1,..., K lossj=−logitslabelj+log(∑i=0Kexp(logitsi)),j=1,...,K
1.2.1 改进后,网络收敛速度明显加快,原项目训练时间需要300个epoch训练超过10h,改进后训练epoch仅需要90个epoch训练时间3个小时左右
安装缺失库scikit-image并解压数据集
pip install scikit-image
unzip data/data17962/二次元人物头像.zip -d data/
mkdir ./work/Output
mkdir ./work/Generate
定义数据预处理工具-DataReader
import os
import cv2
import numpy as np
import paddle.dataset as dataset
from skimage import io,color,transform
import matplotlib.pyplot as plt
import math
import time
import paddle
import paddle.fluid as fluid
import six img_dim = 96 '''准备数据,定义Reader()'''
PATH = 'data/faces/'
TEST = 'data/faces/'
class DataGenerater:
def __init__(self):
'''初始化'''
self.datalist = os.listdir(PATH)
self.testlist = os.listdir(TEST) def load(self, image):
'''读取图片'''
img = io.imread(image)
img = transform.resize(img,(img_dim,img_dim))
img = img.transpose()
img = img.astype('float32')
return img def create_train_reader(self):
'''给dataset定义reader''' def reader():
for img in self.datalist:
#print(img)
try:
i = self.load(PATH + img)
yield i.astype('float32')
except Exception as e:
print(e)
return reader def create_test_reader(self,):
'''给test定义reader'''
def reader():
for img in self.datalist:
#print(img)
try:
i = self.load(PATH + img)
yield i.astype('float32')
except Exception as e:
print(e)
return reader def train(batch_sizes = 32):
reader = DataGenerater().create_train_reader()
return reader def test():
reader = DataGenerater().create_test_reader()
return reader 测试DataReader并输出图片
train_reader = paddle.batch(
paddle.reader.shuffle(
reader=train(), buf_size=128*10
),
batch_size=128
)
for batch_id, data in enumerate(train_reader()):
for i in range(10):
image = data[i].transpose()
plt.subplot(1, 10, i + 1)
plt.imshow(image, vmin=-1, vmax=1)
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(wspace=0.1,hspace=0.1)
plt.show()
break

定义网络功能模块
包括卷积池化组、BatchNorm层、全连接层、转置全连接层、卷积BN复合层
use_cudnn = True
use_gpu = True
n = 0
def bn(x, name=None, act=None,momentum=0.5):
return fluid.layers.batch_norm(
x,
param_attr=name + '1',
# 指定权重参数属性的对象
bias_attr=name + '2',
# 指定偏置的属性的对象
moving_mean_name=name + '3',
# moving_mean的名称
moving_variance_name=name + '4',
# moving_variance的名称
name=name,
act=act,
momentum=momentum,
) ###卷积池化组
def conv(x, num_filters,name=None, act=None):
return fluid.nets.simple_img_conv_pool(
input=x,
filter_size=5,
num_filters=num_filters,
pool_size=2,
# 池化窗口大小
pool_stride=2,
# 池化滑动步长
param_attr=name + 'w',
bias_attr=name + 'b',
use_cudnn=use_cudnn,
act=act
) ###全连接层
def fc(x, num_filters, name=None, act=None):
return fluid.layers.fc(
input=x,
size=num_filters,
act=act,
param_attr=name + 'w',
bias_attr=name + 'b'
) ###转置卷积层
def deconv(x, num_filters, name=None, filter_size=5, stride=2, dilation=1, padding=2, output_size=None, act=None):
return fluid.layers.conv2d_transpose(
input=x,
param_attr=name + 'w',
bias_attr=name + 'b',
num_filters=num_filters,
# 滤波器数量
output_size=output_size,
# 输出图片大小
filter_size=filter_size,
# 滤波器大小
stride=stride,
# 步长
dilation=dilation,
# 膨胀比例大小
padding=padding,
use_cudnn=use_cudnn,
# 是否使用cudnn内核
act=act
# 激活函数
) def conv_bn_layer(input,
ch_out,
filter_size,
stride,
padding,
act=None,
groups=64,
name=None):
tmp = fluid.layers.conv2d(
input=input,
filter_size=filter_size,
num_filters=ch_out,
stride=stride,
padding=padding,
act=None,
bias_attr=name + '_conv_b',
param_attr=name + '_conv_w',
)
return fluid.layers.batch_norm(
input=tmp,
act=act,
param_attr=name + '_bn_1',
# 指定权重参数属性的对象
bias_attr=name + '_bn_2',
# 指定偏置的属性的对象
moving_mean_name=name + '_bn_3',
# moving_mean的名称
moving_variance_name=name + '_bn_4',
# moving_variance的名称
name=name + '_bn_',
momentum=0.5,
) 定义基本残差模块

残差模块如图所示,本文采用的是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。
def shortcut(input, ch_in, ch_out, stride,name):
if ch_in != ch_out:
return conv_bn_layer(input, ch_out, 1, stride, 0, None,name=name)
else:
return input def basicblock(input, ch_in, ch_out, stride,name,act):
tmp = conv_bn_layer(input, ch_out, 3, stride, 1, name=name + '_1_',act=act)
tmp = conv_bn_layer(tmp, ch_out, 3, 1, 1, act=None, name=name + '_2_')
short = shortcut(input, ch_in, ch_out, stride,name=name)
return fluid.layers.elementwise_add(x=tmp, y=short, act='relu') def layer_warp(block_func, input, ch_in, ch_out, count, stride,name,act='relu'):
tmp = block_func(input, ch_in, ch_out, stride,name=name + '1',act=act)
for i in range(1, count):
tmp = block_func(tmp, ch_out, ch_out, 1,name=name + str(i + 1),act=act)
return tmp 判别器
- 将BatchNorm批归一化中momentum参数设置为0.5
- 将判别器(D)激活函数由elu改为leaky_relu,并将alpha参数设置为0.2
- 在判别器(D)中增加Dropout层,并将dropout_prob设置为0.4
输入为大小96x96的RGB三通道图片
输出结果经过一层全连接层最后为shape为[batch_size,2]的Tensor
###判别器
def D(x):
# (96 + 2 * 1 - 4) / 2 + 1 = 48
x = conv_bn_layer(x, 64, 4, 2, 1, act=None, name='conv_bn_1')
x = fluid.layers.leaky_relu(x,alpha=0.2,name='leaky_relu_1')
x = fluid.layers.dropout(x,0.4,name='dropout1')
# (48 + 2 * 1 - 4) / 2 + 1 = 24
x = conv_bn_layer(x, 128, 4, 2, 1, act=None, name='conv_bn_2')
x = fluid.layers.leaky_relu(x,alpha=0.2,name='leaky_relu_2')
x = fluid.layers.dropout(x,0.4,name='dropout2')
# (24 + 2 * 1 - 4) / 2 + 1 = 12
x = conv_bn_layer(x, 256, 4, 2, 1, act=None, name='conv_bn_3')
x = fluid.layers.leaky_relu(x,alpha=0.2,name='leaky_relu_3')
x = fluid.layers.dropout(x,0.4,name='dropout3')
# (12 + 2 * 1 - 4) / 2 + 1 = 6
x = conv_bn_layer(x, 512, 4, 2, 1, act=None, name='conv_bn_4')
x = fluid.layers.leaky_relu(x,alpha=0.2,name='leaky_relu_4')
x = fluid.layers.dropout(x,0.4,name='dropout4')
x = fluid.layers.reshape(x,shape=[-1, 512 * 6 * 6])
x = fc(x, 2, name='fc1')
return x
生成器
- 将BatchNorm批归一化中momentum参数设置为0.5
- 将生成器(G)中的第一层全连接层改为基本残差模块
输入Tensor的Shape为[batch_size,72]其中每个数值大小为0~1之间的float32随机数
输出为大小96x96RGB三通道图片
###生成器
def G(x):
#x = fc(x,6 * 6 * 2,name='g_fc1',act='relu')
#x = bn(x, name='g_bn_1', act='relu',momentum=0.5)
x = fluid.layers.reshape(x, shape=[-1, 2, 6, 6])
x = layer_warp(basicblock, x, 2, 256, 1, 1, name='g_res1', act='relu') # 2 * (6 - 1) - 2 * 1 + 4 = 12
x = deconv(x, num_filters=256, filter_size=4, stride=2, padding=1, name='g_deconv_1')
x = bn(x, name='g_bn_2', act='relu',momentum=0.5) # 2 * (12 - 1) - 2 * 1 + 4 = 24
x = deconv(x, num_filters=128, filter_size=4, stride=2, padding=1, name='g_deconv_2')
x = bn(x, name='g_bn_3', act='relu',momentum=0.5) # 2 * (24 - 1) - 2 * 1 + 4 = 48
x = deconv(x, num_filters=64, filter_size=4, stride=2, padding=1, name='g_deconv_3')
x = bn(x, name='g_bn_4', act='relu',momentum=0.5) # 2 * (48 - 1) - 2 * 1 + 4 = 96
x = deconv(x, num_filters=3, filter_size=4, stride=2, padding=1, name='g_deconv_4',act='relu') return x
损失函数选用softmax_with_cross_entropy,公式如下:
l o s s j = − logits l a b e l j + log ( ∑ i = 0 K exp ( logits i ) ) , j = 1 , . . . , K loss_j = -\text{logits}_{label_j} +\log\left(\sum_{i=0}^{K}\exp(\text{logits}_i)\right), j = 1,..., K lossj=−logitslabelj+log(∑i=0Kexp(logitsi)),j=1,...,K
###损失函数
def loss(x, label):
return fluid.layers.mean(fluid.layers.softmax_with_cross_entropy(logits=x, label=label))
训练网络
设置的超参数为:
- 学习率:2e-4
- Epoch: 300
- Mini-Batch:100
- 输入Tensor长度:72
import IPython.display as display
import warnings
warnings.filterwarnings('ignore') img_dim = 96
LEARENING_RATE = 2e-4
SHOWNUM = 12
epoch = 300
output = "work/Output/"
batch_size = 100
G_DIMENSION = 72
d_program = fluid.Program()
dg_program = fluid.Program() ###定义判别器program
# program_guard()接口配合with语句将with block中的算子和变量添加指定的全局主程序(main_program)和启动程序(start_progrom)
with fluid.program_guard(d_program):
# 输入图片大小为28*28
img = fluid.layers.data(name='img', shape=[None,3,img_dim,img_dim], dtype='float32')
# 标签shape=1
label = fluid.layers.data(name='label', shape=[None,1], dtype='int64')
d_logit = D(img)
d_loss = loss(x=d_logit, label=label) ###定义生成器program
with fluid.program_guard(dg_program):
noise = fluid.layers.data(name='noise', shape=[None,G_DIMENSION], dtype='float32')
#label = np.ones(shape=[batch_size, G_DIMENSION], dtype='int64')
# 噪声数据作为输入得到生成照片
g_img = G(x=noise)
g_program = dg_program.clone()
g_program_test = dg_program.clone(for_test=True) # 判断生成图片为真实样本的概率
dg_logit = D(g_img) # 计算生成图片被判别为真实样本的loss
dg_loss = loss(
x=dg_logit,
label=fluid.layers.fill_constant_batch_size_like(input=noise, dtype='int64', shape=[-1,1], value=1)
) ###优化函数
opt = fluid.optimizer.Adam(learning_rate=LEARENING_RATE,beta1=0.5)
opt.minimize(loss=d_loss)
parameters = [p.name for p in g_program.global_block().all_parameters()]
opt.minimize(loss=dg_loss, parameter_list=parameters) train_reader = paddle.batch(
paddle.reader.shuffle(
reader=train(), buf_size=50000
),
batch_size=batch_size
)
test_reader = paddle.batch(
paddle.reader.shuffle(
reader=test(), buf_size=10000
),
batch_size=10
)
###执行器
if use_gpu:
exe = fluid.Executor(fluid.CUDAPlace(0))
else:
exe = fluid.Executor(fluid.CPUPlace())
start_program = fluid.default_startup_program()
exe.run(start_program)
#加载模型
#fluid.io.load_persistables(exe,'work/Model/D/',d_program)
#fluid.io.load_persistables(exe,'work/Model/G/',dg_program) ###训练过程
t_time = 0
losses = [[], []]
# 判别器迭代次数
NUM_TRAIN_TIME_OF_DG = 2
# 最终生成的噪声数据
const_n = np.random.uniform(
low=0.0, high=1.0,
size=[batch_size, G_DIMENSION]).astype('float32')
test_const_n = np.random.uniform(
low=0.0, high=1.0,
size=[100, G_DIMENSION]).astype('float32') #plt.ion()
now = 0
for pass_id in range(epoch):
fluid.io.save_persistables(exe, 'work/Model/G', dg_program)
fluid.io.save_persistables(exe, 'work/Model/D', d_program)
for batch_id, data in enumerate(train_reader()): # enumerate()函数将一个可遍历的数据对象组合成一个序列列表
if len(data) != batch_size:
continue # 生成训练过程的噪声数据
noise_data = np.random.uniform(
low=0.0, high=1.0,
size=[batch_size, G_DIMENSION]).astype('float32')
# 真实图片
real_image = np.array(data)
# 真实标签
real_labels = np.ones(shape=[batch_size,1], dtype='int64')
# real_labels = real_labels * 10
# 虚假标签
fake_labels = np.zeros(shape=[batch_size,1], dtype='int64')
s_time = time.time()
#print(np.max(noise_data))
# 虚假图片
generated_image = exe.run(g_program,
feed={'noise': noise_data},
fetch_list=[g_img])[0] ###训练判别器
# D函数判断虚假图片为假的loss
d_loss_1 = exe.run(d_program,
feed={
'img': generated_image,
'label': fake_labels,
},
fetch_list=[d_loss])[0][0]
# D函数判断真实图片为真的loss
d_loss_2 = exe.run(d_program,
feed={
'img': real_image,
'label': real_labels,
},
fetch_list=[d_loss])[0][0] d_loss_n = d_loss_1 + d_loss_2
losses[0].append(d_loss_n) ###训练生成器
for _ in six.moves.xrange(NUM_TRAIN_TIME_OF_DG):
noise_data = np.random.uniform( # uniform()方法从一个均匀分布[low,high)中随机采样
low=0.0, high=1.0,
size=[batch_size, G_DIMENSION]).astype('float32')
dg_loss_n = exe.run(dg_program,
feed={'noise': noise_data},
fetch_list=[dg_loss])[0][0]
losses[1].append(dg_loss_n)
t_time += (time.time() - s_time) if batch_id % 500 == 0:
if not os.path.exists(output):
os.makedirs(output)
# 每轮的生成结果
generated_image = exe.run(g_program_test, feed={'noise': test_const_n}, fetch_list=[g_img])[0]
#print(generated_image[1])
imgs = []
plt.figure(figsize=(15,15))
try:
# for test in test_reader():
# for i in range(10):
# image = test[i].transpose()
# plt.subplot(4, 10, i + 1)
# plt.imshow(image)
# plt.axis('off')
# plt.xticks([])
# plt.yticks([])
# plt.subplots_adjust(wspace=0.1, hspace=0.1)
# break
for i in range(100):
image = generated_image[i].transpose()
plt.subplot(10, 10, i + 1)
plt.imshow(image)
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
# plt.subplots_adjust(wspace=0.1,hspace=0.1)
msg = 'Epoch ID={0} Batch ID={1} \n D-Loss={2} G-Loss={3}'.format(pass_id + 92, batch_id, d_loss_n, dg_loss_n)
#print(msg)
plt.suptitle(msg,fontsize=20)
plt.draw()
#if batch_id % 10000 == 0:
plt.savefig('{}/{:04d}_{:04d}.png'.format(output, pass_id + 92, batch_id),bbox_inches='tight')
plt.pause(0.01)
display.clear_output(wait=True) #plt.pause(0.01)
except IOError:
print(IOError) #plt.ioff()
plt.close()
plt.figure(figsize=(15, 6))
x = np.arange(len(losses[0]))
plt.title('Loss')
plt.xlabel('Number of Batch')
plt.plot(x,np.array(losses[0]),'r-',label='D Loss')
plt.plot(x,np.array(losses[1]),'b-',label='G Loss')
plt.legend()
plt.savefig('work/Train Process')
plt.show()
最后的损失变化曲线为

横向对比
每次生成一组shape为[1,72]的随机数,平均更改其中某个数值,依次生成20组随机数,输入生成器,得到横向对比图片,得到GAN神奇的过渡
改变发色深浅

改变头发颜色

import warnings
warnings.filterwarnings('ignore')
import IPython.display as display '''定义超参数'''
img_dim = 96
output = "Output/"
G_DIMENSION = 72
use_gpu = False
dg_program = fluid.Program() ###定义生成器program
with fluid.program_guard(dg_program):
noise = fluid.layers.data(name='noise', shape=[None,G_DIMENSION], dtype='float32')
#label = np.ones(shape=[batch_size, G_DIMENSION], dtype='int64')
# 噪声数据作为输入得到生成照片
g_img = G(x=noise)
g_program = dg_program.clone()
g_program_test = dg_program.clone(for_test=True) # 判断生成图片为真实样本的概率
dg_logit = D(g_img) # 计算生成图片被判别为真实样本的loss
dg_loss = loss(
x=dg_logit,
label=fluid.layers.fill_constant_batch_size_like(input=noise, dtype='int64', shape=[-1,1], value=1)
) if use_gpu:
exe = fluid.Executor(fluid.CUDAPlace(0))
else:
exe = fluid.Executor(fluid.CPUPlace())
start_program = fluid.default_startup_program()
exe.run(start_program)
fluid.io.load_persistables(exe,'work/Model/G/',dg_program)
plt.figure(figsize=(25,6))
try:
for i in range(G_DIMENSION):
noise = np.random.uniform(low=0.0, high=1.0,size=[G_DIMENSION]).astype('float32')
const_n = []
for m in range(20):
noise2 = noise.copy()
noise2[i] = (m + 1) / 20
const_n.append(noise2)
const_n = np.array(const_n).astype('float32')
#print(const_n)
generated_image = exe.run(g_program, feed={'noise': const_n}, fetch_list=[g_img])[0]
for j in range(20):
image = generated_image[j].transpose()
plt.subplot(1, 20, j + 1)
plt.imshow(image)
plt.axis('off')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
#plt.suptitle('Generated Image')
plt.savefig('work/Generate/generated_' + str(i + 1), bbox_inches='tight')
display.clear_output(wait=True)
#plt.show()
except IOError:
print(IOError)
项目总结
简单介绍了一下DCGAN的原理,通过对原项目的改进和优化,一步一步依次对生成器和判别器以及训练过程进行介绍。
通过横向对比某个输入元素对生成图片的影响。平均更改其中某个数值,依次生成20组随机数,输入生成器,得到横向对比图片,得到GAN神奇的过渡。
DCGAN生成二次元头像仔细看是足以以假乱真的,通过DCGAN了解到GAN强大的“魔力”