论文题目:CoADNet: Collaborative Aggregation-and-Distribution Networks for Co-Salient Object Detection
论文链接:https://proceedings.neurips.cc/paper/2020/file/4dc3ed26a29c9c3df3ec373524377a5b-Paper.pdf
论文代码:https://github.com/rmcong/CoADNet_NeurIPS20
讲解视频(机器之心NeurIPS‘20 MeetUp@北京):https://www.bilibili.com/video/BV1np4y1z7B7
1 引言
受人类的协同处理机制启发,协同显著性目标检测(CoSOD)任务旨在确定一个图像组数据中反复出现的共有显著性目标。因此,除了判定目标的显著与否以外,如何有效捕获图间关系是CoSOD任务的关键。上图中给出了一个示例,其中只有柠檬是在三幅图像中多次出现的显著性目标,而其他目标需被抑制,最后一列黄色底纹的结果是本文方法得到的,可以看出其可以完整、有效地突出协同显著性目标,并有力抑制杂乱背景的干扰。
目前基于深度学习的协同显著性目标检测研究尚处于起步发展阶段,具有以下三方面问题:
(1)RGB协同显著性检测是在图像组中进行检测,学习到的群组语义会随输入图像组的顺序不同而变化,从而导致训练不稳定;
(2)图内显著性和图间关系存在竞争,学习到的群组语义直接与个体特征融合会导致图像间交互过程中的信息冗余;
(3)特征解码时忽略了图像间的一致性,这导致最终的协同显著性检测结果的图间一致性降低。
基于此,本文提出了一种基于协同集成与分发的协同显著性目标检测算法,网络在公开数据集上获得了更加准确、一致性更好的检测结果,具体贡献包括:
(1)设计了一个在线图内显著性引导(OIaSG)模块,用于提供显著性先验知识,该模块以联合优化的方式提供可训练的显著性指导信息;
(2)提出了一个两阶段的集成和分布架构,以学习群组对应关系和协同显著性特征,主要包括群组注意语义集成(GASA)模块和门控群组分发(GGD)模块。
(3)构建了群组一致性保持解码器(GCPD),更加充分地利用图像间约束在生成全分辨率协同显著性图的同时保持群组一致性。
2 方法
本文方法是一种端到端的结构,在给定图像组的情况下,首先使用共享的骨干特征提取器来获取深层特征,并通过在线的图内显著性引导模块生成图内显著性特征,然后将群组注意力语义集成模块和门控群组分发模块集成到一个两阶段的集成-分发结构中来聚合群组语义特征并自适应地将其分配给不同的个体,以实现协同显著性特征学习。最后,将低分辨率的协同显著性特征送入群组一致性保持解码器和协同显著头部件中来一致性地突出协同显著性目标并生成全分辨率的协同显著性图。
在线图内显著性指导(OIaSG)模块:从概念上讲,协同显著性检测任务可以分解为两个关键部分,即显著性和重复性。前者要求目标在视觉上是显著的、容易引起注意的,而后者则约束目标在图像组中是重复多次出现的。但是,此任务面临的挑战是:1)单个图像中的显著性目标可能不会在其他图像中都出现,2)重复的对象不一定在视觉上是显著的,这使得很难学习到将这两个因素结合在一起的统一表示。因此,采用联合学习框架来提供可训练的显著性先验作为指导信息,以此抑制背景冗余。
得益于图内显著性分支的联合优化框架,协同显著性分支可以得到可信度更高、更为灵活的引导信息。在训练阶段,除了从协同显著性目标检测数据集加载的输入外,还将从单图显著性目标数据集加载的K个辅助样本与图内显著性头部件同时馈送到共享的骨干网络,从而生成单图显著性图,单图显著性和协同显著性预测作为一个多任务学习框架进行联合优化,在提供可靠的显著性先验方面具有更好的灵活性和可扩展性。
群组注意语义集成(GASA)模块:为了有效地捕获具有判别力、鲁棒的组间关系,设置了三个关键标准:1)对输入顺序不敏感,这意味着所学习的群组语义特征应对分组图像的输入顺序不敏感;2)考虑到协同显著性目标可能位于图像中的不同位置,因此需要对空间位置变化鲁棒;3)兼顾计算效率,特别是在处理大型图像组或高维特征时。基于此,提出了一种计算效率高且对顺序不敏感的群组注意力语义集成模块,该模块能够很好的在组语义上下文中建立协同显著对象的局部和全局联系。
直接串联图内显著性特征来学习群组关系不可避免地会导致较高的计算复杂度和顺序敏感性,通过将通道分组调整为按块分组来设计特征重组策略,该重组策略在块级别重新组合了特征通道。此外,为了获取更丰富的语义信息,将每个块级群组特征 独立处理,然后融合得到群组语义表示。由于 只集成了相同位置的图间特征,因此进一步聚合了不同空间位置之间的图间关系。现有的群组集成方法只对局部对应关系进行建模,不能很好地对分散的协同显著性目标的远程依赖关系进行建模,因此本文将局部和全局关系编码为群组注意力结构。首先利用具有不同半径的空洞卷积来整合多感受野特征并捕捉局部上下文信息。然后基于注意力的方式对长距离语义依赖关系进行了建模。
门控群组分发(GGD)模块:在以往的研究中,学习到的群组语义信息被直接复制,然后与图内显著性特征连接,这意味着分组信息被不同的图像平等地利用。实际上,群组语义编码了所有图像之间的关系,对于不同图像的协同显著性预测来说,这可能包括一些信息冗余。因此,本文提出了一种门控群组分发模块来自适应地将最有用的组间信息分配给每个个体,构造了一个动态学习权重的群组重要性估计器,通过门控机制将群组语义与不同的图内显著性特征结合起来。
群组一致性保持解码器(GCPD):分层特征提取产生低分辨率的深度特征,这些特征应该被放大以生成全分辨率预测。然而,最常见的基于上采样或反卷积的特征解码器不适用于协同显著性目标检测任务,因为它们忽略了图像间的约束关系,并且在预测过程中可能会削弱图像之间的一致性。因此,本文提出了一种组间一致性保持解码器来一致地预测全分辨率协同显著性图。该部分包含了三个级联的特征解码(FD)单元,在每个单元中,生成紧凑的组特征向量 。通过堆叠三个级联特征解码单元,可以获得空间分辨率最精细的 个解码特征,并进一步馈送到共享的协同显著性头部件以生成全分辨率的图。
损失函数:在一个多任务学习框架中联合优化了协同显著性预测和单图显著性预测。给定 个协同显著性图和真图,以及 个辅助显著性预测和真图,通过两个二值交叉熵损失函数来构成整个协同显著性目标检测网络的联合目标函数 。
3 实验
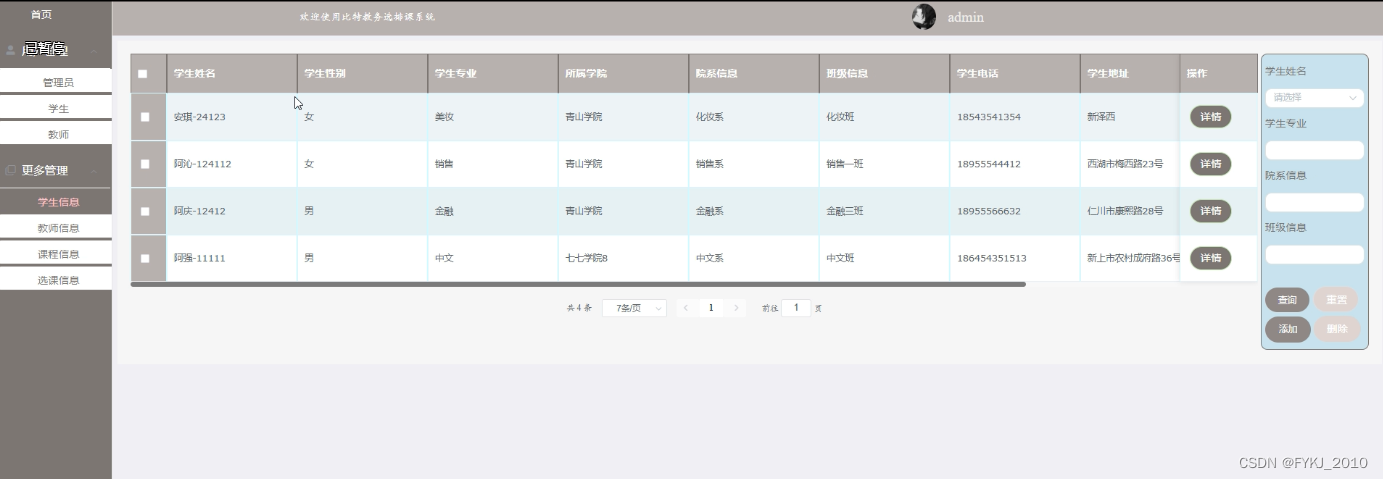
本文在COCO-SEG数据集上进行网络训练,并在CoSOD3k、Cosal2015、MSRC和 iCoseg数据集上进行测试,通过PR曲线、F值、MAE值和S值进行定量评测。
从可视化结果可以看出,本文方法能够完整、准确的提取协同显著性目标,而且能够很好的抑制干扰,如第一组图像中的苹果,它是单图显著性目标但却不是协同显著性目标,本文方法可以较好的进行抑制。
从定量指标上看,本文提供了三种不同骨架网络(即VGG16、ResNet50、DilatedResNet-50)下检测结果,相比于最新的对比算法,本文模型达到了最佳性能。
从消融实验结果中可以看出,本文设计的各个模块都对性能增益起到了正面作用,也证明了模型设计的有效性。
现有的基于深度学习的协同显著性检测方法大都利用样本数量较多的COCO-SEG数据集进行训练,但是COCO-SEG数据集中很多数据并不存在明显的显著性特性,因此直接利用该数据集进行协同显著性模型训练尚有不妥。因此,本文也在呼吁采用更加合适的数据集来进行CoSOD任务的训练。
4 总结
本文提出了一种端到端的协同显著性检测网络,重点考虑了协同显著性检测任务中图间关系建模、图内显著性与图间关系的协同、协同显著性目标的一致性保持等问题,所提模型在多个数据集上都取得了较好的检测效果。
本期编辑:丛润民、张琦坚
责任编辑:张禹墨、杨 宁
下载:CVPR / ECCV 2020开源代码
后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加微信群
▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!











![[dhtmlxGantt(甘特图)开发手册]第三篇——语言设置、导出PDF/PNG、导出Excel/iCal等](https://img-blog.csdn.net/20160510165910414)


