一、说明
在机器学习中,性能测量是一项基本任务。因此,当涉及到分类问题时,我们可以依靠AUC - ROC曲线。当我们需要检查或可视化多类分类问题的性能时,我们使用AUC(曲线下面积)ROC(接收器工作特性)曲线。它是检查任何分类模型性能的最重要评估指标之一。
本博客旨在回答以下问题:
- 1. 什么是 AUC - ROC 曲线?
- 2. 定义 AUC 和 ROC 曲线中使用的术语。
- 3. 如何推测模型的性能?
- 4. 敏感性、特异性、FPR 和阈值之间的关系。
- 5. 如何在多类模型中使用 AUC - ROC 曲线?
二、什么是 AUC - ROC 曲线?
AUC - ROC 曲线是各种阈值设置下分类问题的性能度量。ROC 是一条概率曲线,AUC 表示可分离性的程度或度量。它告诉模型能够区分类的程度。AUC 越高,模型在将 0 个类预测为 0 和将 1 个类预测为 1 方面越好。以此类推,AUC越高,模型在区分有疾病和无疾病患者方面就越好。
ROC 曲线使用 TPR 与 FPR 绘制,其中 TPR 在 y 轴上,FPR 在 x 轴上。

三、定义 AUC 和 ROC 曲线中使用的术语。
3.1 TPR(真阳性率)/召回率/灵敏度

3.2 特异性

3.3 FPR

四、如何推测模型的性能?
优秀的模型的 AUC 接近 1,这意味着它具有良好的可分离性。较差的模型的 AUC 接近 0,这意味着它的可分离性度量最差。事实上,这意味着它正在回报结果。它将 0 预测为 1,将 1 预测为 0。当 AUC 为 0.5 时,意味着模型没有任何类别分离能力。 我们来解读一下上面的说法。 众所周知,ROC是一条概率曲线。那么让我们绘制这些概率的分布: 注:红色分布曲线为正类(患病患者),绿色分布曲线为负类(无疾病患者)。

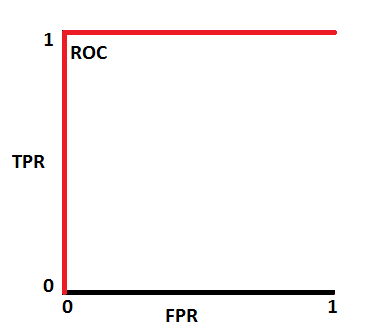
这是一个理想的情况。当两条曲线完全不重叠时,意味着模型具有理想的可分离性度量。它完全能够区分正类和负类。


当两个分布重叠时,我们引入类型 1 和类型 2 错误。根据阈值,我们可以最小化或最大化它们。当 AUC 为 0.7 时,这意味着模型有 70% 的机会能够区分正类和负类。


这是最糟糕的情况。当AUC约为0.5时,模型没有区分正类和负类的判别能力。
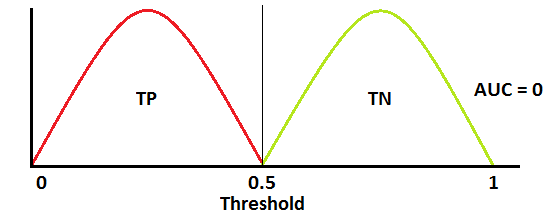
当 AUC 大约为 0 时,模型实际上是在往复类。这意味着模型将负类预测为正类,反之亦然。
五、灵敏度、特异性、FPR 和阈值之间的关系。
敏感性和特异性成反比。因此,当我们增加灵敏度时,特异性会降低,反之亦然。
敏感性,特异性和敏感性⬆️⬇️,特异性⬇️⬆️
当我们降低阈值时,我们得到更多的正值,从而增加敏感性并降低特异性。
同样,当我们增加阈值时,我们会得到更多的负值,从而获得更高的特异性和更低的灵敏度。
众所周知,FPR 是 1 - 特异性。因此,当我们增加TPR时,FPR也会增加,反之亦然。
TPR,FPR和TPR,FPR⬆️⬆️⬇️⬇️
六、如何在多类模型中使用 AUC ROC 曲线?
在多类模型中,我们可以使用 One vs ALL 方法绘制 N 个类的 N 个 AUC ROC 曲线。例如,如果您有名为 X、Y 和 Z 的三个类,则将有一个针对 Y 和 Z 分类的 X 的 ROC,另一个针对 Y 分类的 Y 的 ROC,以及针对 Y 和 X 分类的第三个 Z。