「作者主页」:士别三日wyx
「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者
「推荐专栏」:零基础快速入门人工智能《机器学习入门到精通》
K-近邻算法
- 1、什么是K-近邻算法?
- 2、K-近邻算法API
- 3、K-近邻算法实际应用
- 3.1、获取数据集
- 3.2、划分数据集
- 3.3、特征标准化
- 3.4、KNN处理并评估
1、什么是K-近邻算法?
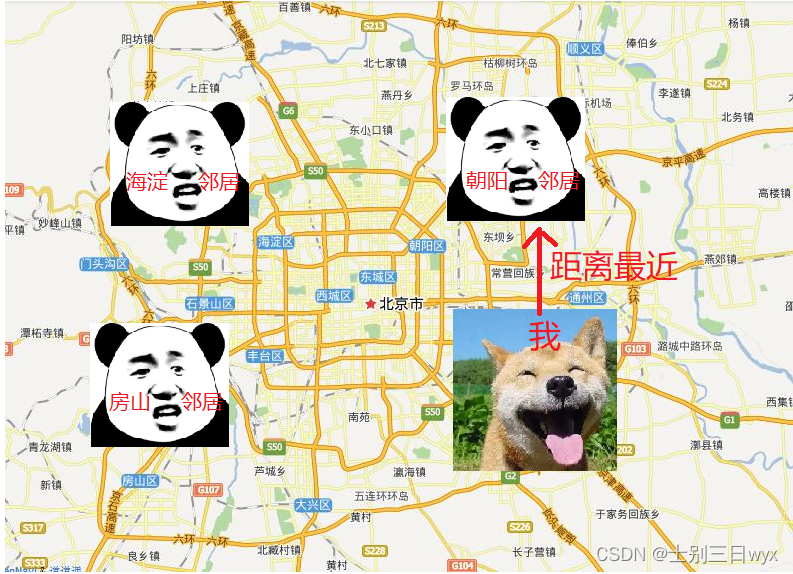
K-近邻算法的核心思想是根据「邻居」来「推断」你的类别。
K-近邻算法的思路其实很简单,比如我在北京市,想知道自己在北京的哪个区。K-近邻算法就会找到和我距离最近的‘邻居’,邻居在朝阳区,就认为我大概率也在朝阳区。
其中 K 是邻居个数的意思
- 邻居个数「太少」,容易受到异常值的影响
- 邻居个数「太多」,容易受到样本不均衡的影响。
2、K-近邻算法API
sklearn.neighbors.KNeighborsClassifier( n_neighbors=5, algorithm=‘auto’ ) 是实现K-近邻算法的API
- n_neighbors:(可选,int)指定邻居(K)数量,默认值 5
- algorithm:(可选,{ ‘auto’,‘ball_tree’,‘kd_tree’,‘brute’})计算最近邻居的算法,默认值 ‘auto’。
算法解析
- brute:蛮力搜索,也就是线性扫描,训练集越大,消耗的时间越多。
- kd_tree:构造kd树(也就是二叉树)存储数据以便对其进行快速检索,以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高
- ball_tree:用来解决kd树高维失效的问题,以质心C和半径r分割样本空间,每个节点是一个超球体。
- auto:自动决定最合适的算法
函数
- KNeighborsClassifier.fit( x_train, y_train):接收训练集特征 和 训练集目标
- KNeighborsClassifier.predict(x_test):接收测试集特征,返回数据的类标签。
- KNeighborsClassifier.score(x_test, y_test):接收测试集特征 和 测试集目标,返回准确率。
- KNeighborsClassifier.get_params():获取接收的参数(就是 n_neighbors 和 algorithm 这种参数)
- KNeighborsClassifier.set_params():设置参数
- KNeighborsClassifier.kneighbors():返回每个相邻点的索引和距离
- KNeighborsClassifier.kneighbors_graph():返回每个相邻点的权重
3、K-近邻算法实际应用
3.1、获取数据集
这里使用sklearn自带的鸢尾花「数据集」,它是分类最常用的分类试验数据集。
from sklearn import datasets# 1、获取数据集(实例化)
iris = datasets.load_iris()print(iris.data)
输出:
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2]
从打印的数据集可以看到,鸢尾花数据集有4个「属性」,这里解释一下属性的含义
- sepal length:萼片长度(厘米)
- sepal width:萼片宽度(厘米)
- petal length:花瓣长度(厘米)
- petal width:花瓣宽度(厘米)
3.2、划分数据集
接下来对鸢尾花的特征值(iris.data)和目标值(iris.target)进行「划分」,测试集为60%,训练集为40%。
from sklearn import datasets
from sklearn import model_selection# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
print('训练集特征值:', len(x_train))
print('测试集特征值:',len(x_test))
print('训练集目标值:',len(y_train))
print('测试集目标值:',len(y_test))
输出:
训练集特征值: 112
测试集特征值: 38
训练集目标值: 112
测试集目标值: 38
从打印结果可以看到,测试集的样本数是38,训练集的样本数是112,划分比例符合预期。
3.3、特征标准化
接下来,对训练集和测试集的特征值进行「标准化」处理(训练集和测试集所做的处理必须完全「相同」)。
from sklearn import datasets
from sklearn import model_selection
from sklearn import preprocessing# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
# x_train:训练集特征,x_test:测试集特征,y_train:训练集目标,y_test:测试集目标
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
# 3、特征标准化
ss = preprocessing.StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.fit_transform(x_test)
print(x_train)
输出:
[[-0.18295405 -0.192639 0.25280554 -0.00578113][-1.02176094 0.51091214 -1.32647368 -1.30075363][-0.90193138 0.97994624 -1.32647368 -1.17125638]
从打印结果可以看到,特征值发生了相应的变化。
3.4、KNN处理并评估
接下来,将训练集特征 和 训练集目标 传给 KNN,然后评估处理结果的「准确率」。
from sklearn import datasets
from sklearn import model_selection
from sklearn import preprocessing
from sklearn import neighbors# 1、获取数据集
iris = datasets.load_iris()
# 2、划分数据集
# x_train:训练集特征,x_test:测试集特征,y_train:训练集目标,y_test:测试集目标
x_train, x_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, random_state=6)
# 3、特征标准化
ss = preprocessing.StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.fit_transform(x_test)
# 4、KNN算法处理
knn = neighbors.KNeighborsClassifier(n_neighbors=2)
knn.fit(x_train, y_train)
# 5、评估结果
y_predict = knn.predict(x_test)
print('真实值和预测值对比:', y_predict == y_test)
score = knn.score(x_test, y_test)
print('准确率:', score)
输出:
真实值和预测值对比: [ True True True True True True False True True True False TrueTrue True True False True True True True True True True TrueTrue True True True True True True True True True False TrueTrue True]
准确率: 0.8947368421052632
从输出结果可以很容易看出,准确率是89%;真实值和预测值对比的结果中,True越多,表示准确率越高。

![[JavaScript游戏开发] 2D二维地图绘制、人物移动、障碍检测](https://img-blog.csdnimg.cn/086495efd69c4446a328ac88a51238bd.png)