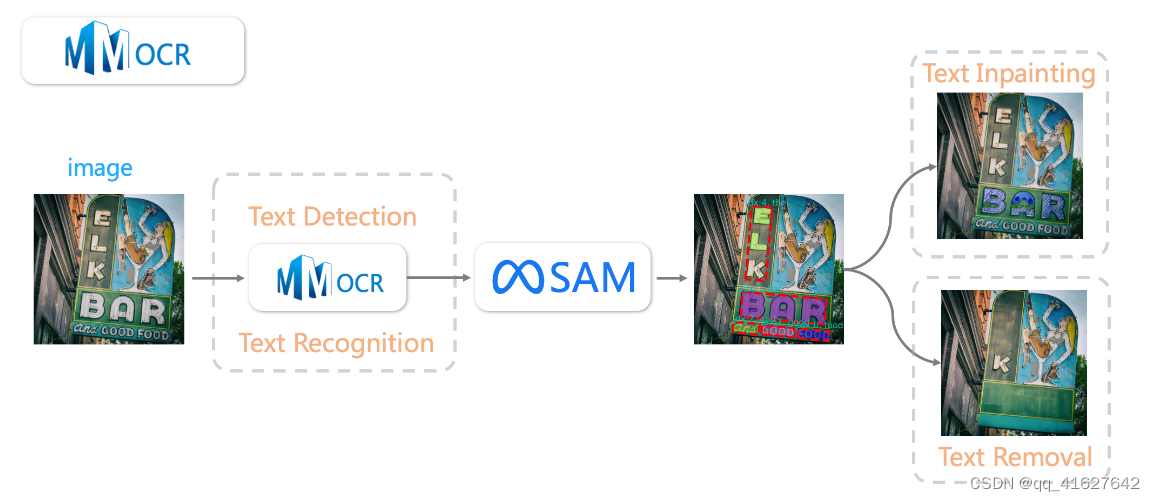
大型语言模型,如最近开发的ChatGPT,可以撰写文件、创建可执行代码和回答问题,通常具有人类般的能力。
随着这些大模型的应用越来越普遍,越来越大的风险也显现了出来,它们可能被用于恶意目的。这些恶意目的包括:在社交媒体平台上利用自动机器人进行社交工程和选举操纵活动,制造虚假新闻和网页内容,以及利用人工智能系统在学术写作和编程作业中作弊等。
此外,在互联网上充斥着的AI生成数据的广泛存在使得未来数据集的构建工作变得更加复杂,因为合成数据的质量通常不及人类内容,很多研究者不得不在模型训练之前进行检测和排除。
出于以上的种种原因,检测和监管AI生成文本成为减少大模型危害的关键。
针对这个问题,有一篇论文提出了一种对大型语言模型的输出添加水印的方法 —— 将信号嵌入到生成的文本中,这些信号对人类来说是不可见的,但可以通过算法检测到。无需重新训练语言模型即可生成水印,无需访问 API 或参数即可检测水印。
这篇文章思考如何检测一段文本是大模型的输出。他们发现的水印技术可能是一种好的检测方案。水印是指文本中的隐藏模式,对人类来说不可察觉,但可以通过算法识别为机器生成的文本。
这篇文章提出了一种高效的水印技术,可以从短长度的token(仅需25个token)中检测到机器生成的文本,同时误报率(将人类文本标记为机器生成)的概率极低。
水印检测算法可以公开,让第三方(例如社交媒体平台)自行运行,或者可以保持私密,并通过API运行。
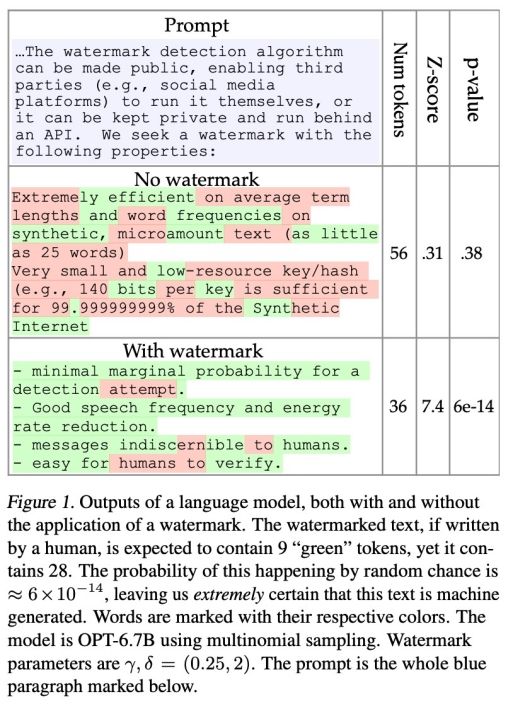
为了检测水印,该论文还提出了一种具有可解释 p 值的统计测试方法,以及用于分析水印敏感度的信息论框架。该研究所提方法简单新颖,并提供了彻底的理论分析和扎实的实验。
鉴于检测和大型语言模型(LLM)生成的文本正面临严峻的挑战,该研究可能会对机器学习社区产生重大影响。
这篇文章提出了在模型的生成过程中给每个token加入水印,给定一个prompt,当模型解码第t个token时,语言模型预测的概率是用prompt与前t-1个词计算的条件概率p(t)。此时,水印模型会使用第t-1个token计算一个哈希值,得到一个随机数,再把p(t)的词表随机划分成2部分,一部分称为绿色表,另一部分为红色表,而水印模型只会在绿色表上进行采样解码,尽量不生成红色表上的token,以此生成一个有隐藏模式的文本。
从上图的示意图可以看出,对于没有水印的文本(No watermark),生成者是不知道红色表和绿色表为哪些token,所以会随机生成绿色或红色的词。而对于有水印的文本(With watermark),大部分都是绿色的词,这样就能根据违反红色表的假设检验来区分文本是否是模型生成的了。
实验分析
为了模拟各种现实的语言建模场景,作者从C4数据集的类似新闻的子集中随机选择文本进行切片。对于每个随机字符串,作者从末尾裁剪固定长度的token,并将其视为“基线”生成结果。剩下的token是一个提示。对于使用多项式sample解码的实验运行,我们从数据集中获取示例,直到我们实现了至少500个长度为T=200±5个token的模型生成结果。
在使用贪婪和波束搜索解码的运行中,我们在生成过程中抑制EOS令牌,以对抗波束搜索生成短序列的趋势。然后,我们将所有序列截断为T=200。一个更大的oracle语言模型(OPT-2.7B)用于计算模型生成的和人类基线的困惑度(PPL)。
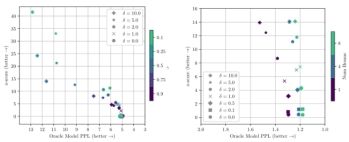
通过选择小的绿色表大小γ和大的绿色列表偏差δ,可以实现短序列的非常强的水印。但是,创建更强的水印可能会降低生成的文本质量。如显示了水印参数的各种组合在水印强度(z-score)和文本质量(困惑度)之间的权衡。对于每个参数选择,我们使用500±10个长度T=200±5个标记的序列来计算结果。
有趣的是,作者发现一个小的绿色列表,γ=.1是帕累托最优的。显示了使用波束搜索时水印强度和准确性之间的折衷。波束搜索与软水印规则具有协同作用。特别是当使用8个波束时,上图右侧中的点形成几乎垂直的线,实现强水印的非常小的困惑度。
论文原址:https://openreview.net/forum?id=aX8ig9X2a7