一、首先我们先看要求
1.写一个爬虫程序
2、爬取目标网站数据,关键项不能少于5项。
3、存储数据到数据库,可以进行增删改查操作。
4、扩展:将库中数据进行可视化展示。
二、操作步骤:
首先我们根据要求找到一个适合自己的网站,我找的网站如下所示:
电影 / 精品电影_电影天堂-迅雷电影下载 (dygod.net)
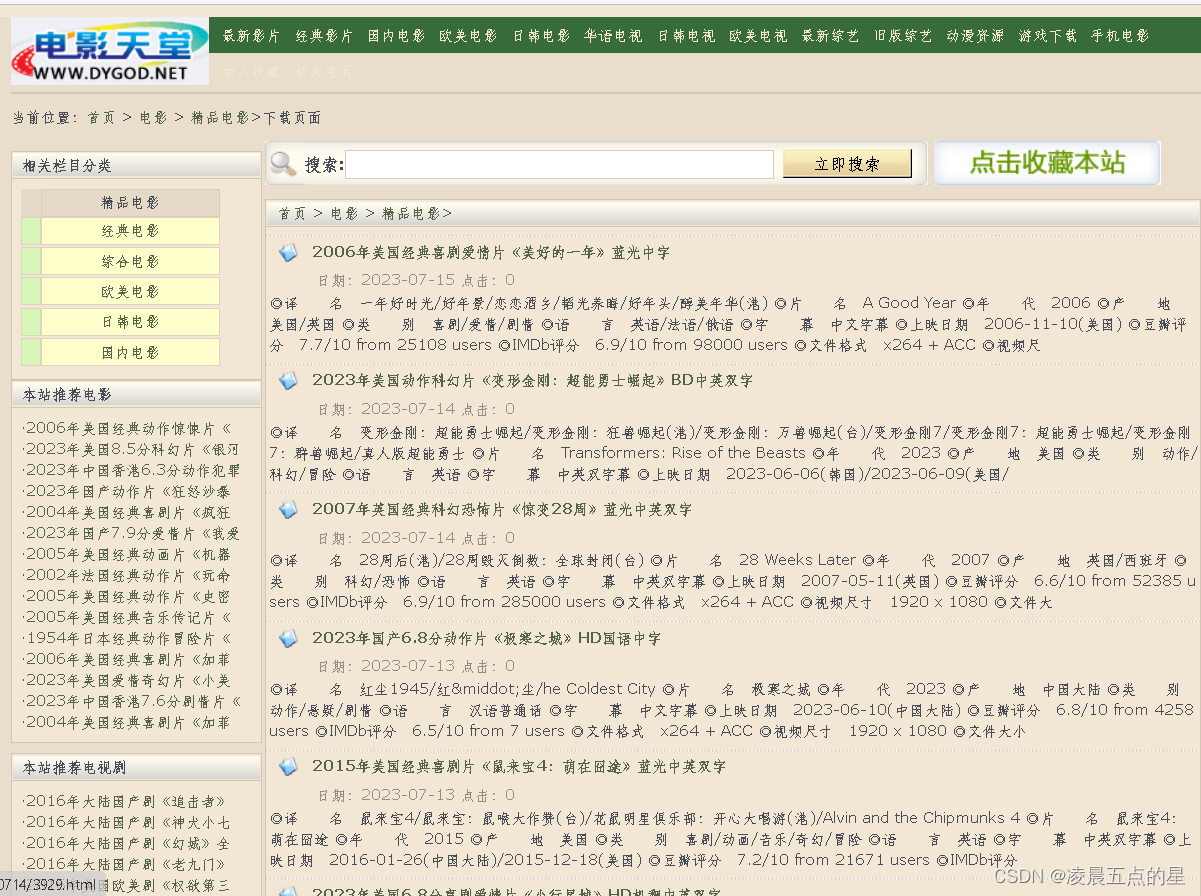
1、根据要求我们导入爬取网页所需要的板块:
import requests #扒取页面
import re #正则
import xlwt #Excel库用于读取和写入
from bs4 import BeautifulSoup #从网页提取信息2、设置url为我们所需要爬的网站,并为其增加ua报头
url = "https://www.dygod.net/html/gndy/dyzz/"
# url1 = "https://movie.douban.com/top250?start=0&filter="hd = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'
}3.我们记录爬取的电影,以及创建自己的工作表
count = 0 #记录爬取的电影数量
total = []
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet('sheet1') #创建工作表
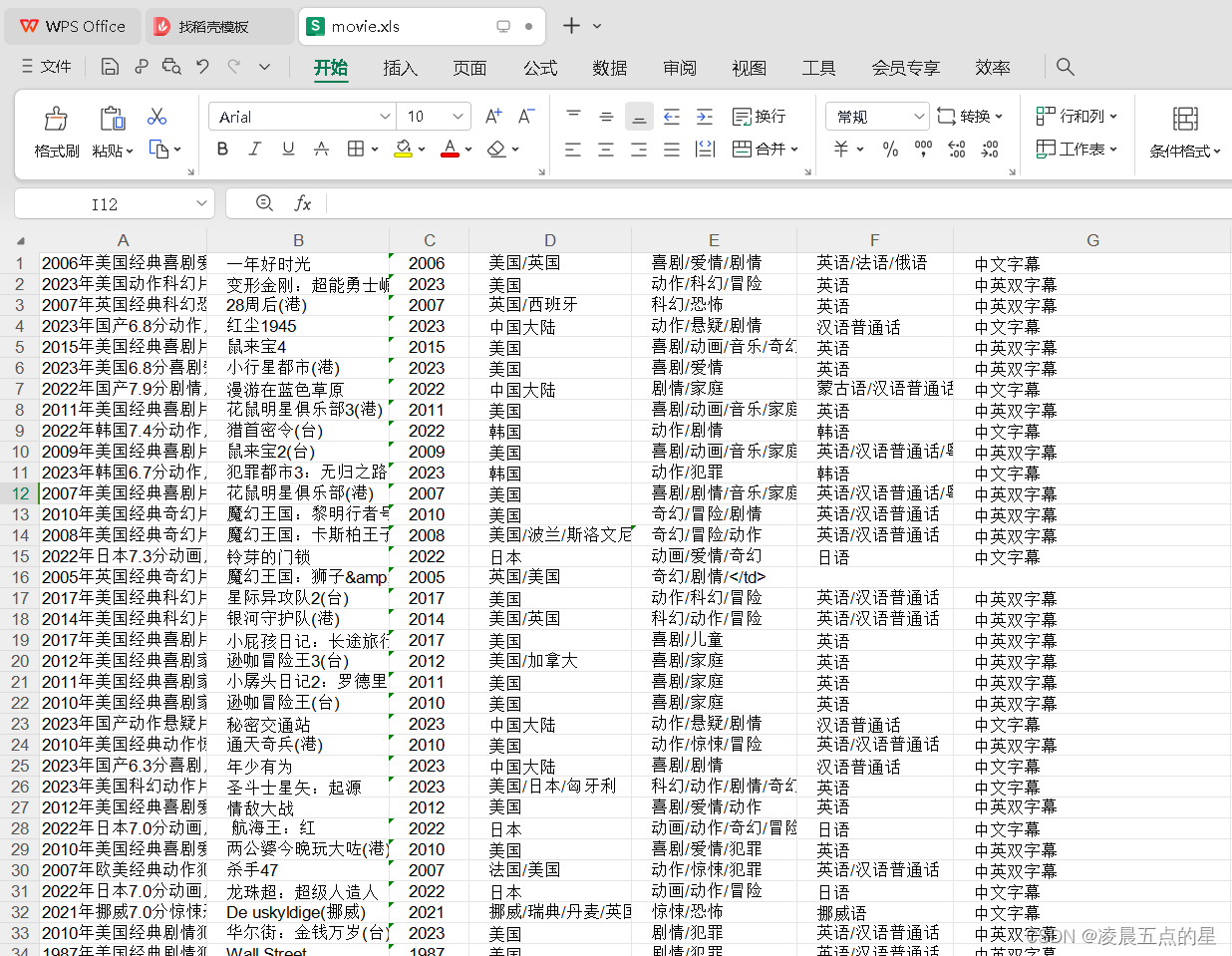
4.我们基于网站上的数据通过F12进入调试模式,找寻自己需要爬取的数据,进行封装和继承,最终保存在movie.xls表格中导进去
def saveExcel(worksheet, count, lst):for i, value in enumerate(lst):worksheet.write(count, i, value)for i in range(2, 10): # 爬取电影的页面数量,范围从第2页到第10页(包含第10页)url = "https://www.dygod.net/html/gndy/dyzz/index_"+str(i)+".html"# print(url)res = requests.get(url,headers=hd)res.encoding = res.apparent_encoding# print(res.text)soup = BeautifulSoup(res.text,"html.parser")# print(soup.title,type(soup.title))ret = soup.find_all(class_="tbspan",style="margin-top:6px") #找到所有电影的表格for x in ret: #遍历每一个电影表格info = []print(x.find("a").string) #电影名称info.append(x.find("a").string)pat = re.compile(r"◎译 名(.*)\n")ret_translated_name = re.findall(pat, str(x))for n in ret_translated_name:n = n.replace(u'/u3000', u'')print("◎译 名:", n)info.append(str(n).split("/")[0])pat = re.compile(r"◎年 代(.*)\n")ret_year = re.findall(pat, str(x))for n in ret_year:n = n.replace(u'/u3000', u'')print("◎年 代:", n)info.append(str(n))pat = re.compile(r"◎产 地(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎产 地:", n)info.append(str(n))pat = re.compile(r"◎类 别(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎类 别:", n)info.append(str(n))pat = re.compile(r"◎语 言(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎语 言:", n)info.append(str(n))pat = re.compile(r"◎字 幕(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎字 幕:", n)info.append(str(n))#print(count,info)saveExcel(worksheet,count,info)count += 1print("="*100)
workbook.save("movie.xls")
print(count)5.如此就做到了爬取我们所需要的数据是不是很简单,最后的汇总源码如下:
# -*- coding:utf-8 -*-
'''
@Author: lingchenwudiandexing
@contact: 3131579667@qq.com
@Time: 2023/8/2 10:24
@version: 1.0
'''
from urllib import responseimport requests #扒取页面
import re #正则
import xlwt #Excel库用于读取和写入
from bs4 import BeautifulSoup #从网页提取信息url = "https://www.dygod.net/html/gndy/dyzz/"
# url1 = "https://movie.douban.com/top250?start=0&filter="hd = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188'
}#正式代码开始
count = 0 #记录爬取的电影数量
total = []
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet('sheet1') #创建工作表def saveExcel(worksheet, count, lst):for i, value in enumerate(lst):worksheet.write(count, i, value)for i in range(2, 10): # 爬取电影的页面数量,范围从第2页到第10页(包含第10页)url = "https://www.dygod.net/html/gndy/dyzz/index_"+str(i)+".html"# print(url)res = requests.get(url,headers=hd)res.encoding = res.apparent_encoding# print(res.text)soup = BeautifulSoup(res.text,"html.parser")# print(soup.title,type(soup.title))ret = soup.find_all(class_="tbspan",style="margin-top:6px") #找到所有电影的表格for x in ret: #遍历每一个电影表格info = []print(x.find("a").string) #电影名称info.append(x.find("a").string)pat = re.compile(r"◎译 名(.*)\n")ret_translated_name = re.findall(pat, str(x))for n in ret_translated_name:n = n.replace(u'/u3000', u'')print("◎译 名:", n)info.append(str(n).split("/")[0])pat = re.compile(r"◎年 代(.*)\n")ret_year = re.findall(pat, str(x))for n in ret_year:n = n.replace(u'/u3000', u'')print("◎年 代:", n)info.append(str(n))pat = re.compile(r"◎产 地(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎产 地:", n)info.append(str(n))pat = re.compile(r"◎类 别(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎类 别:", n)info.append(str(n))pat = re.compile(r"◎语 言(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎语 言:", n)info.append(str(n))pat = re.compile(r"◎字 幕(.*)\n")ret_production_country = re.findall(pat, str(x))for n in ret_production_country:n = n.replace(u'/u3000', u'')print("◎字 幕:", n)info.append(str(n))#print(count,info)saveExcel(worksheet,count,info)count += 1print("="*100)
workbook.save("movie.xls")
print(count)
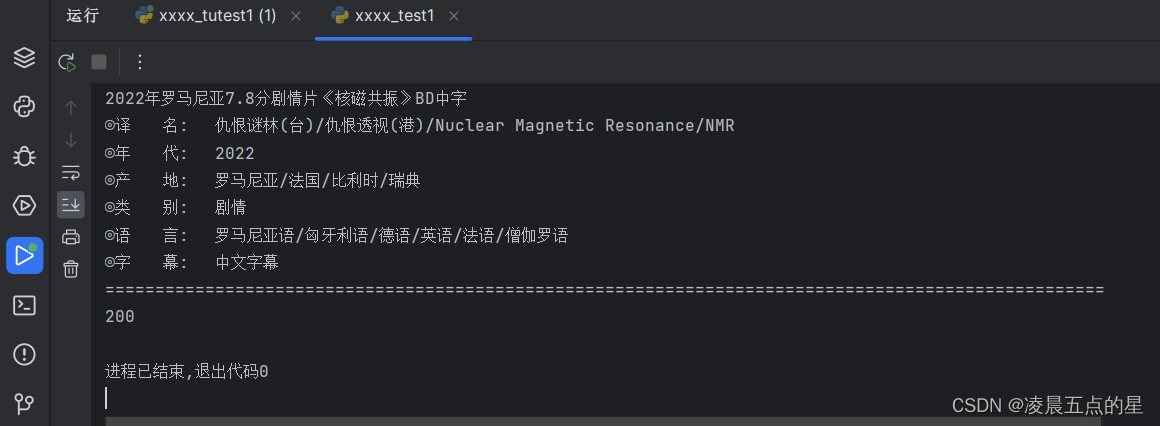
三、基础部分实现结果截屏
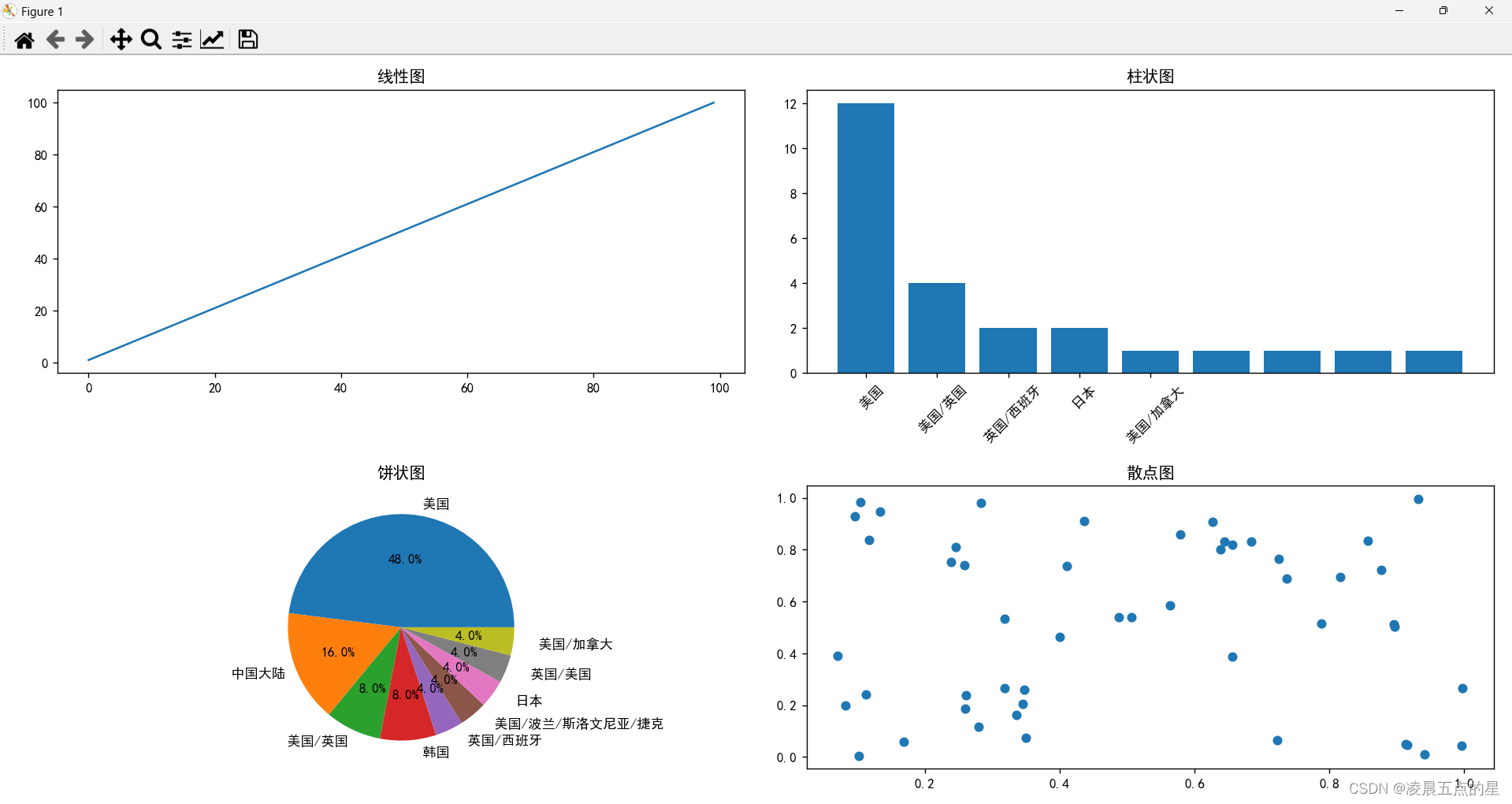
四、实验Plus升级版,增加数据汇总为图形化界面,面向对象
1.导入图像化界面的板块
import matplotlib.pyplot as plt
import numpy as np
from bs4 import BeautifulSoup2.实现自己想要实现的图形:(其中几行几列标注清楚)
①:初步:创建自己的画布,以及想要实现展现的语言
# 将数据保存到Pandas DataFrame对象中
columns = ["电影名称", "译名", "年代", "产地", "类别", "语言","字幕"]
df = pd.DataFrame(data, columns=columns)# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']# 创建一个包含4个子图的画布
figure = plt.figure(figsize=(12, 8))②:创建线形图:
# 创建线性图
subplot_line = figure.add_subplot(2, 2, 1)
x_data = np.arange(0, 100)
y_data = np.arange(1, 101)
subplot_line.plot(x_data, y_data)
subplot_line.set_title('线性图')③:创建饼状图:
subplot_pie = figure.add_subplot(2, 2, 3)
subplot_pie.pie(genre_counts.values, labels=genre_counts.index, autopct='%1.1f%%')
subplot_pie.set_title('饼状图')④:创建散点图:(设置好断点,不然会出现字符重叠的情况)
# 创建散点图
subplot_scatter = figure.add_subplot(2, 2, 4)
x_scatter = np.random.rand(50)
y_scatter = np.random.rand(50)
subplot_scatter.scatter(x_scatter, y_scatter)
subplot_scatter.set_title('散点图')
import warnings
warnings.filterwarnings("ignore")
plt.tight_layout()
plt.show()⑤:到此我们整个爬虫以及数据记录便结束了,附上Plus实现截图: