摘要
- 本文工作聚焦于从领域泛化的视角提升AES模型的泛化能力,在该情况下,目标主题的数据在训练时不能被获得。
- 本文提出了一个主题感知的神经AES模型(PANN)来抽取用于作文评分的综合的表示,包括主题无关(prompt-invariant)和主题相关(prompt-specific)的特征。
- 为了提升表示的泛化能力,我们进一步提出了一个新的解缠绕表示学习框架(disentangled representation learning)。在这个框架中,设计了一个对比的模长-角度对齐策略(norm-angular alignment)和一个反事实自训练策略(counterfactual self-training)用于解开表示中主题无关和主题相关的特征信息。
引言
- 本文提出一个主题感知的神经AES模型,它能够基于一篇作文的编码器(比如说预训练的BERT)来抽取作文的质量特征,并且基于一个文本匹配模块来抽取主题遵循度特征。
- 存在两个问题:
- 从编码器中抽取到的作文质量特征,比如BERT,可能编码了质量和内容信息,并且它们在特征中是相互缠绕的。怎样从特征中解开独立的质量信息是第一个问题;
- 主题关联特征和作文质量特征都是基于作文抽取得到的。因此,从因果的角度看,作文是两种特征的混淆因素,导致主题关联度和作文质量间的有误导性的关联。比如,一篇作文可能有不同的主题关联性但是一样的质量,在不同的主题下。所以,怎样解开这种误导性的关联,使得这两种特征独立得贡献于最终的分数是第二个问题。
方法
- 解缠绕表示学习框架(DRL)是基于预训练和微调的范式进行设计的。
- 在预训练阶段,设计了一个对比的norm-angular对齐策略来预训练文章质量特征,目的是解绑特征中的质量和内容信息。
- 在微调阶段,应用了一个反事实自训练策略来微调整个PANN模型,目的是解绑文章质量特征和主题相关特征之间的误导性的关联。
- 最后,使用完全训练好的PANN来评分目标主题的作文。
PANN的模型架构
-
三个主要组成:
- 作文质量网络(EQ-net):只把作文作为输入,抽取主题无关的作文质量特征。
- 主题关联网络(PA-net):把作文和主题都作为输入,抽取主题特定的主题遵循度特征。因为这样的基于交互的文本匹配模型能够只关注作文和主题的词级的相似度,它能够避免编码到和作文质量相关的信息,比如句法和内聚力,从而使得特征只特定于主题遵循度。
- 作文评分预测器(ESP):结合两种特征来预测整体分数。
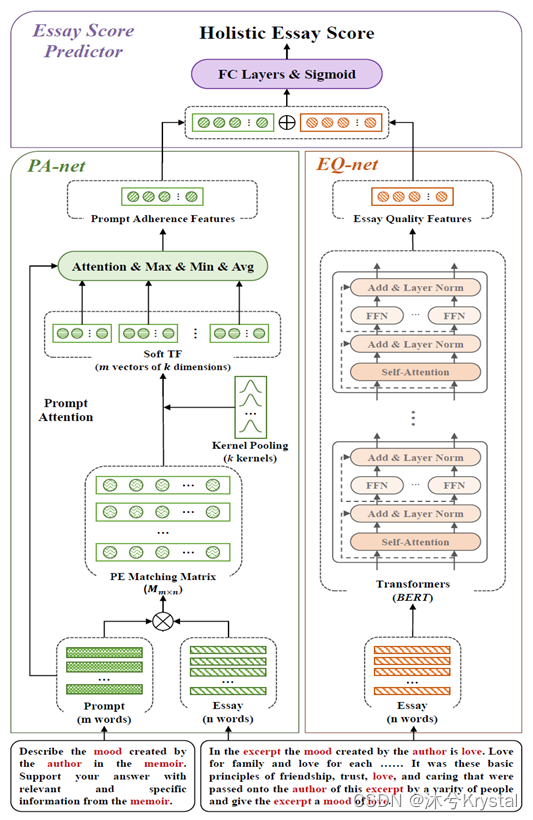
解缠绕表示学习DRL
- EQ-net可能会编码主题无关的质量信息和主题相关的内容信息,并且内容信息会在不同主题间切换,它会阻止EQ-net的泛化能力。
- 并且,PA-net和EQ-net都把作文作为输入,这使得作文变成主题关联度特征和作文质量特征的混淆因素,导致他们之间具有误导性的关联。
质量-内容解缠(Quality-Content Disentanglement)
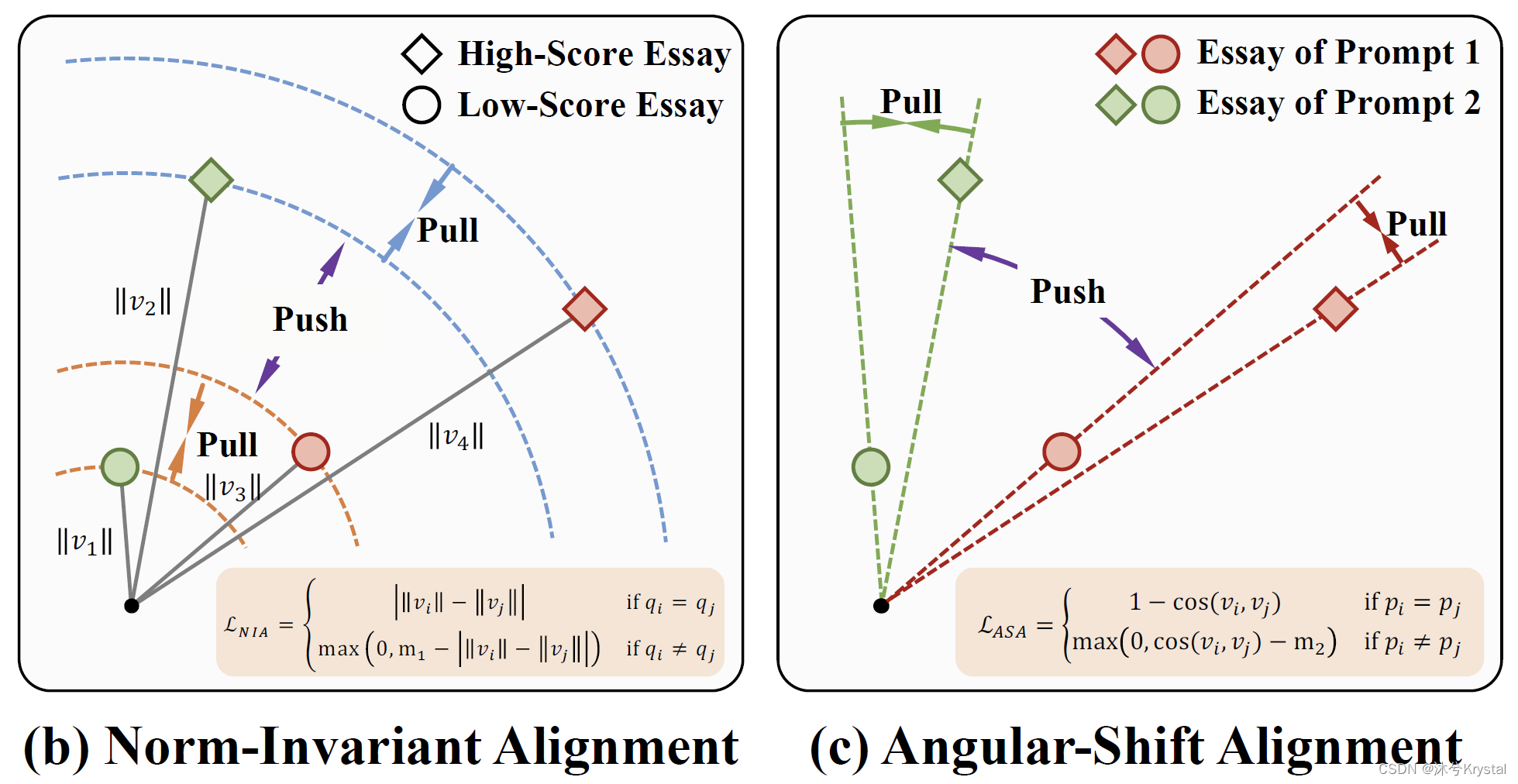
- 我们提出了一个对比的模长-角度对齐策略(Contrastive Norm-Angular Alignment,CNAA)来在作文质量特征中的质量和内容信息。
- 这个策略的设计是基于模长不变性(norm invariant)和角度切换(angular shift)的假设,它假设质量和内容信息能够通过分别对齐就模长和角度而言的特征来被解绑。
- 对于模长不变性,我们假设相似质量的作文能够本分布具有相似的模长,并且这些模长可能是各个主题都不变的。
- 对于角度切换,我们假设具有相似内容的作文(i.e.,主题)能够被分布具有相似的角度,但是这些角度应该在不同的主题上切换。
数据增强
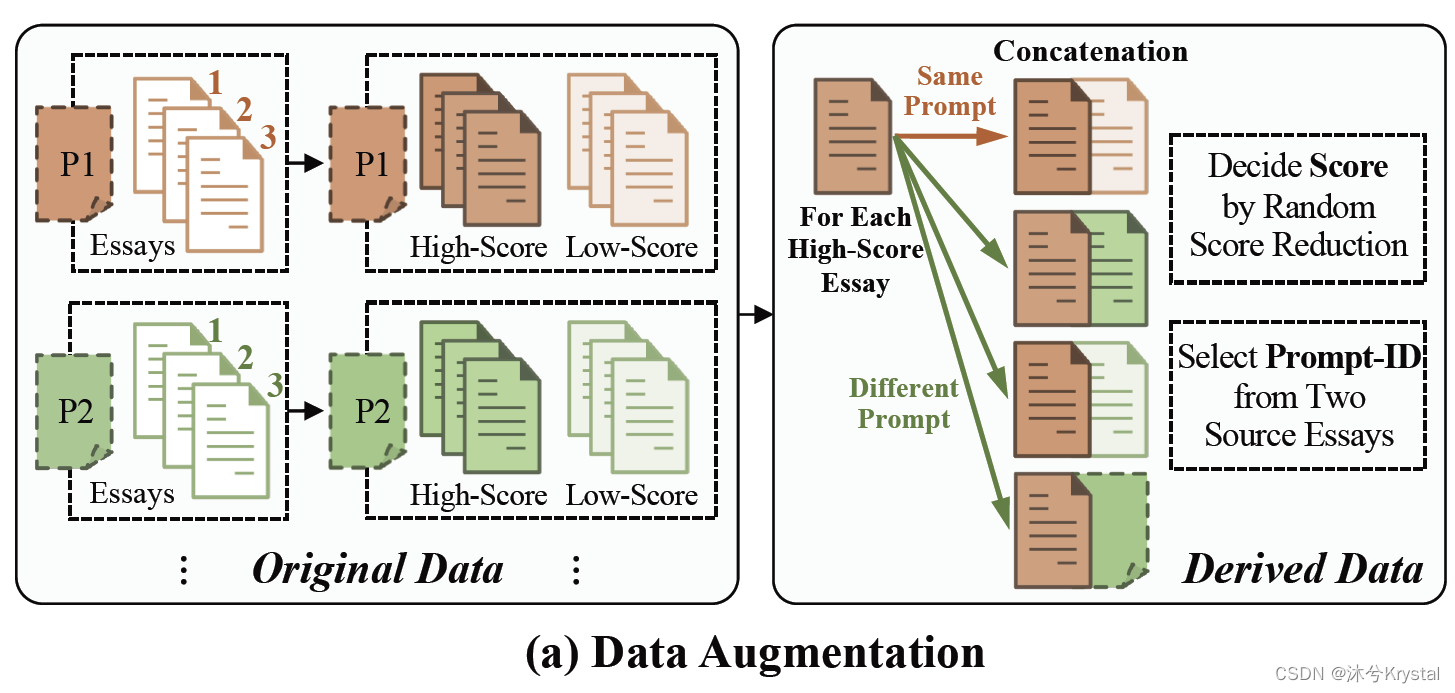
- 为了准备数据用于对比的模长-角度对齐,我们首先从训练集中抽取所有的高分和低分作文来组成原始数据 D o D_o Do。
- 通过两两拼接这些作文来构建衍生的数据 D d D_d Dd。
- 随机降低分数给拼接后的作文的原因是:
- 拼接两篇文章可能会降低那篇更高分数的作文的质量(比如,内聚力和组织)。
- 拼接来自不同主题的两篇文章可能会降低作文的主题遵循度(对两个主题都是)。
模长不变性&角度切换 对齐
- 基于成对的对比学习,包括模长不变的质量对齐和角度切换的内容对齐。
质量-遵循度解缠(Quality-Content Disentanglement)
- 本文尝试提出和回答以下问题:“如果一篇文章的质量保持不变,但它的题目符合度不同,那么最终得分会是多少?”
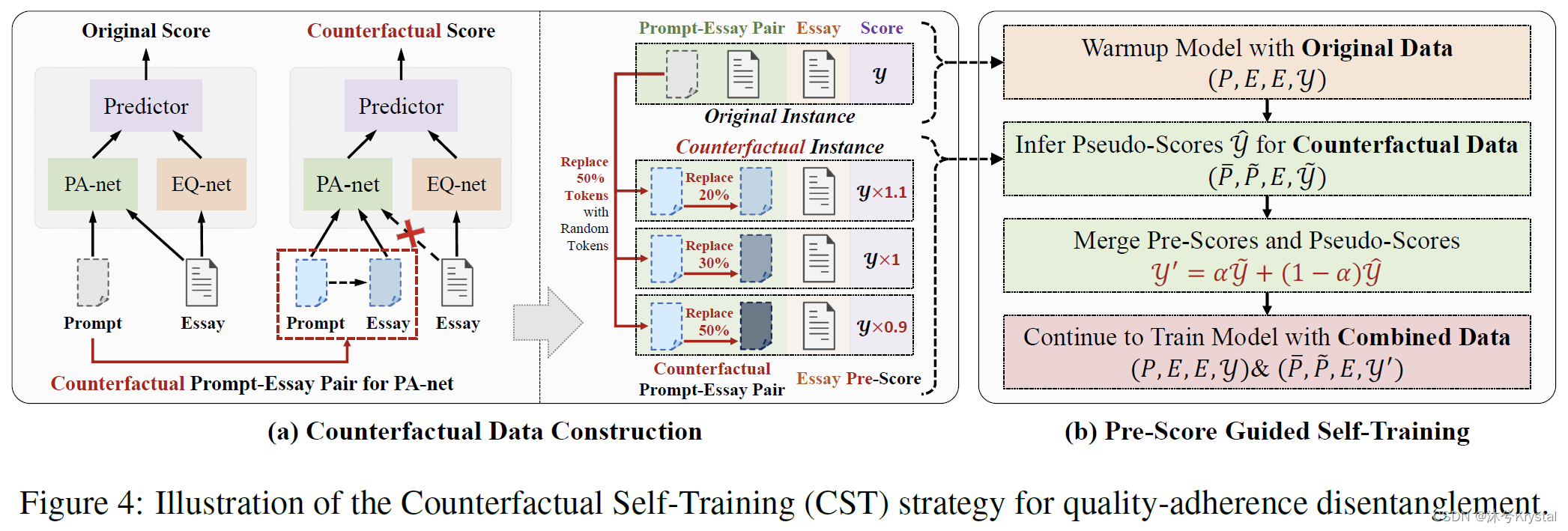
预评分指导的自训练
- 本文把每个反事实实例的预打好的预分数和模型预测的伪分数结合作为它的最终分数。以这种方式,在预分数中提供的先验知识和编码在伪分数中的模型知识能够被很好得融合。
实验
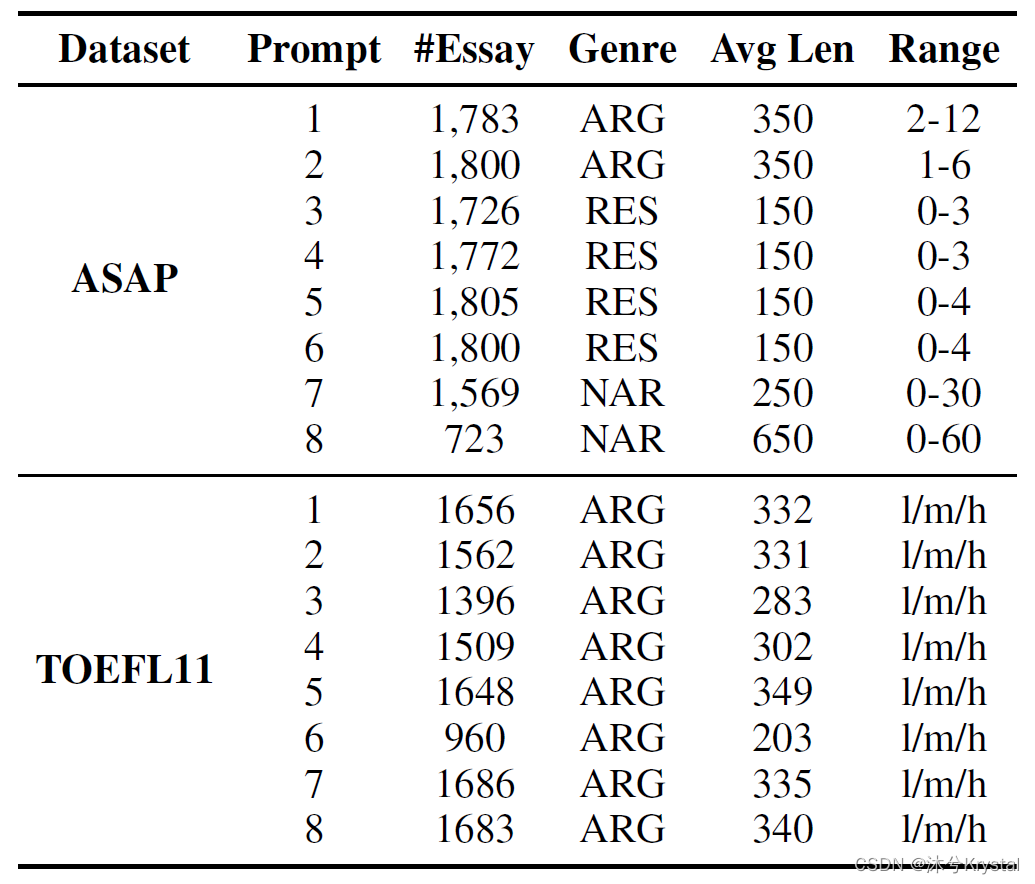
- ASAP数据集和TOEFL11数据集
实验结果
-
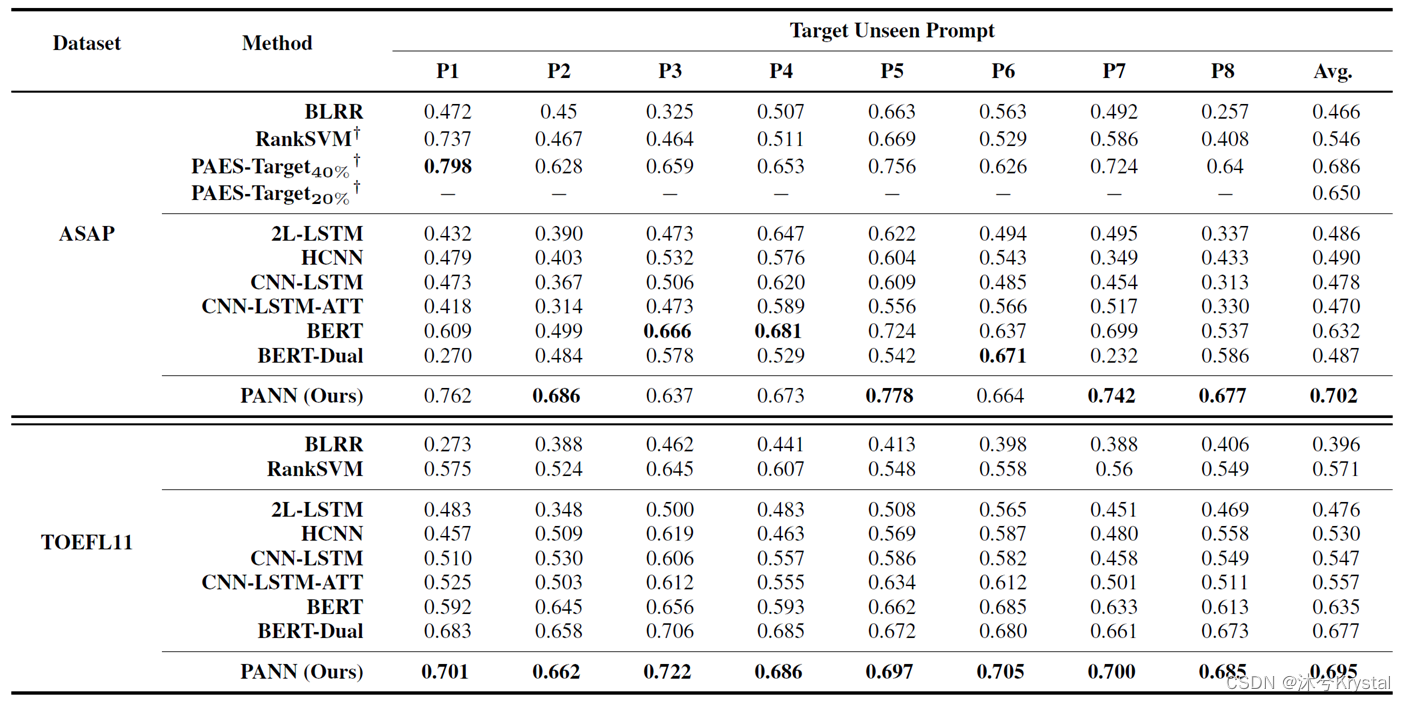
我们和主题泛化设置的方法进行比较,包括三类方法:基于手工特征的,基于神经网络的和混合的。
-
可以看到,我们的PANN模型能够超过大多数的基准方法,在两个数据集上都达到最好的整体性能。这表明我们的方法对于主题泛化的作文评分是有用的。
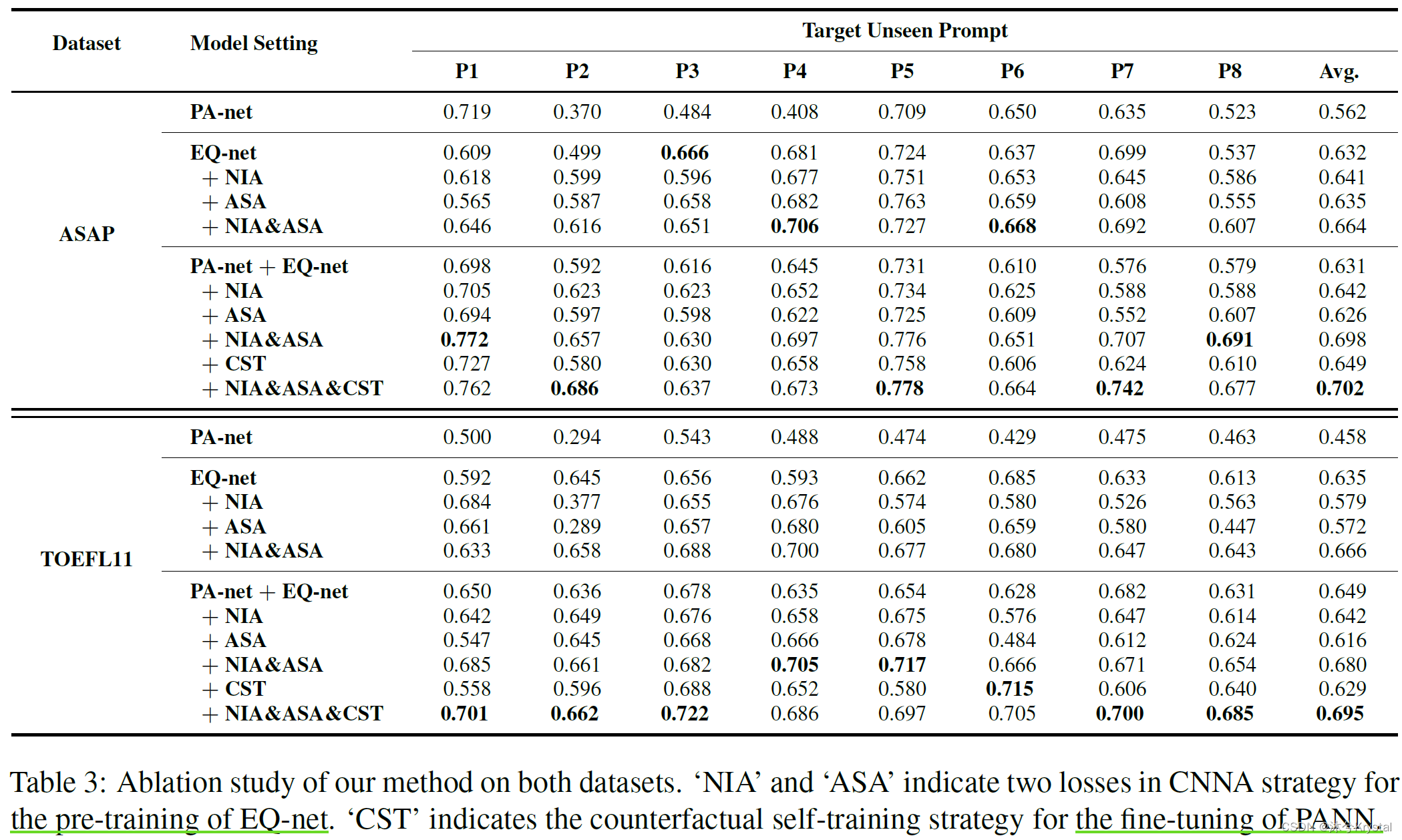
- 结合PA-net和EQ-net两个部分比单独的PA-net或者EQ-net的性能好。这表明PA-net和EQ-net都能够为作文评分提供有用的信息。
- 当EQ-net被用NIA和ASA预训练,EQ-net的性能被提升。但是当EQ-net被只有他们中的一个预训练的时候,在TOEFL11数据集上性能下降了。相似的现象也可以在PA-net+EQ-net上观察到。这可能是由于两个损失需要被同时使用来解开质量和内容信息的缠绕。
- 并且,CTS也需要和CNAA策略一起使用来获得更好的性能。
进一步分析
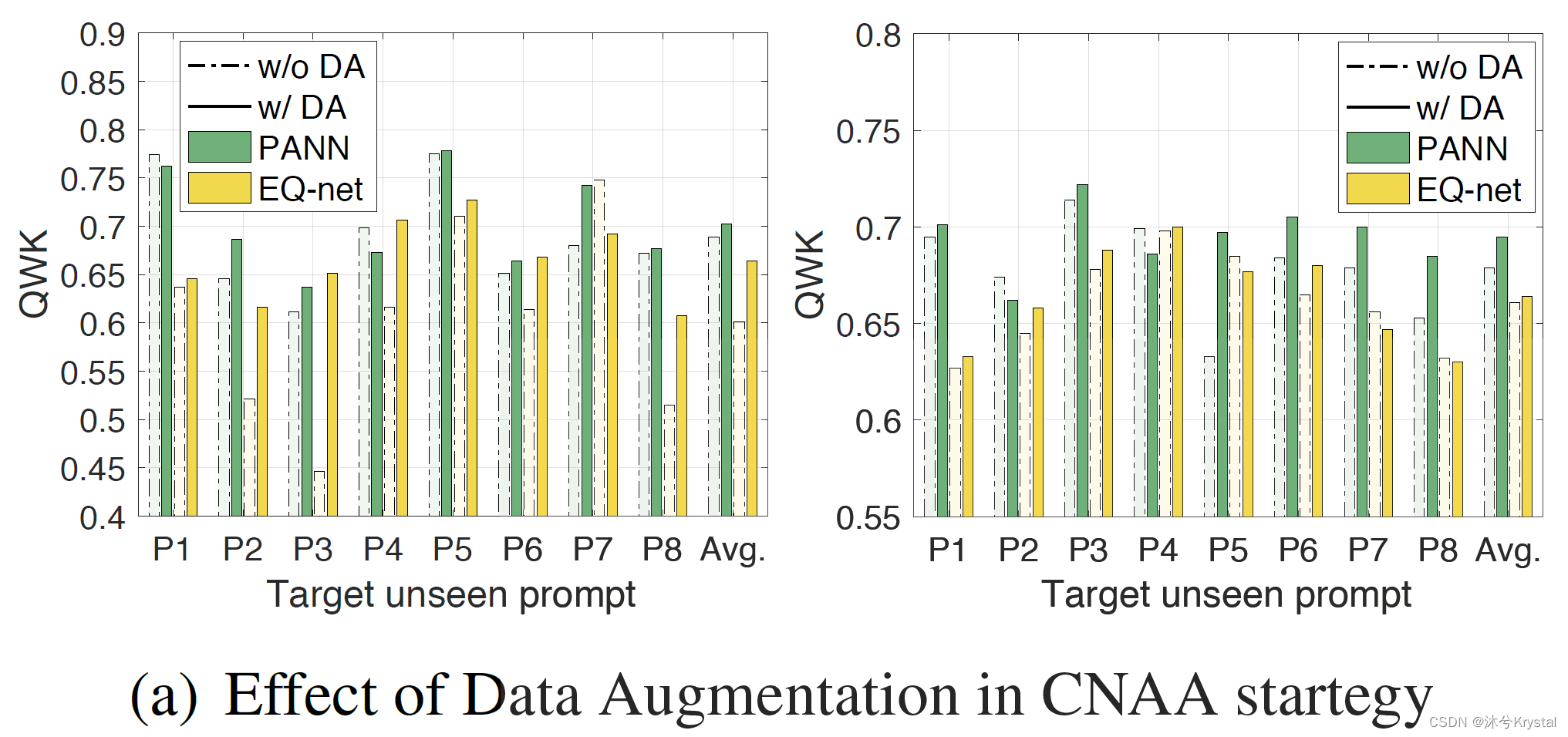
- 数据增强的影响:可以发现PANN和EQ-net能够从数据增强中受益,特别是在ASAP的P3上,和TOEFL11数据集的P5上。
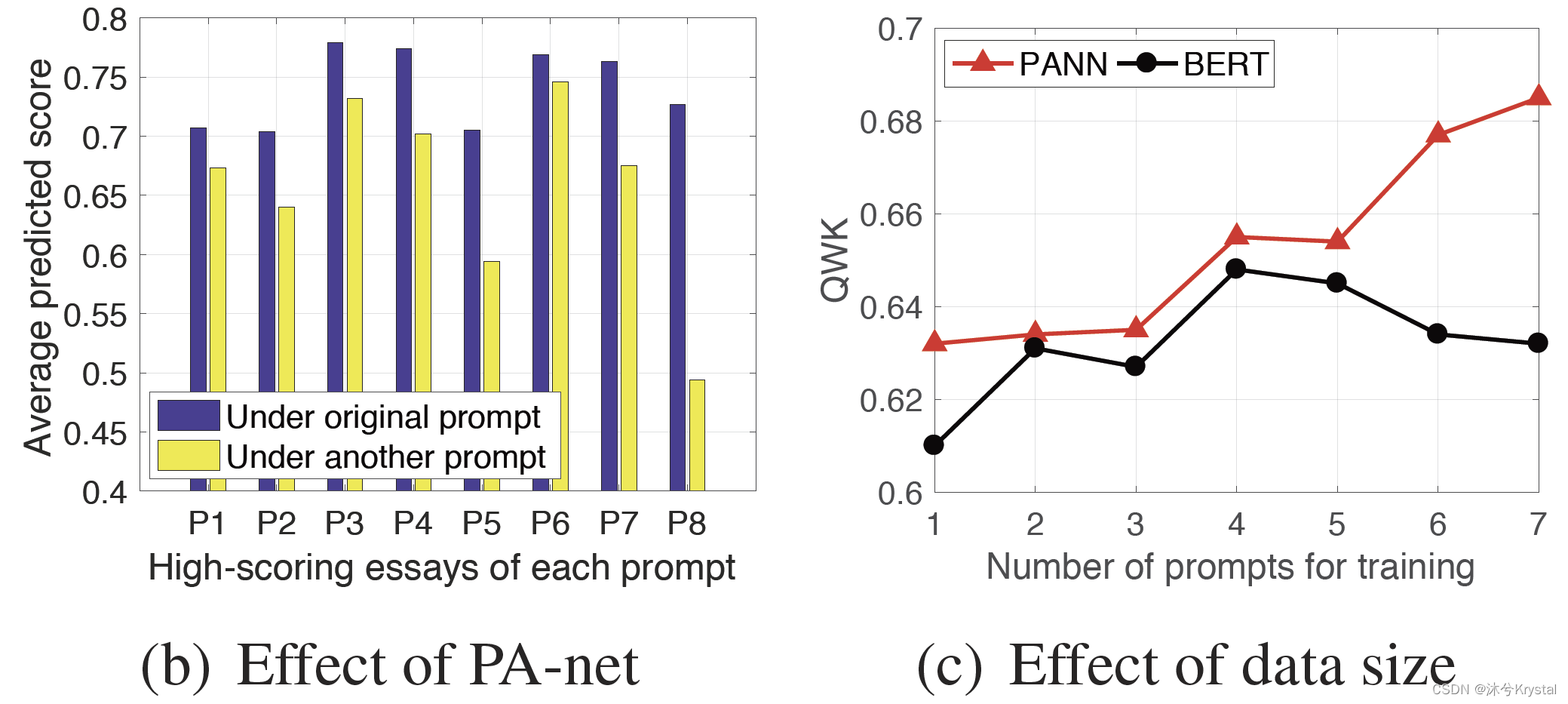
- PA-net的影响:是否PA-net能够独立的影响最终的分数预测。可以看到,PANN为在不匹配的主题下的高分作文预测了平均更低的分数;由于EQ-net在两种设置下输出的特征是不变的,所以PA-net能够感知主题上的变化,能够独立影响分数预测。
- 数据大小的影响:在数据大小增大时,我们的PANN的预测性能相应提升,但是BERT的性能先上升后下降。这表明我们的表示解缠绕策略能够处理主题个数增长时带来的缠绕的信息的问题,所以模型能够从数据增长中获益。
特征可视化
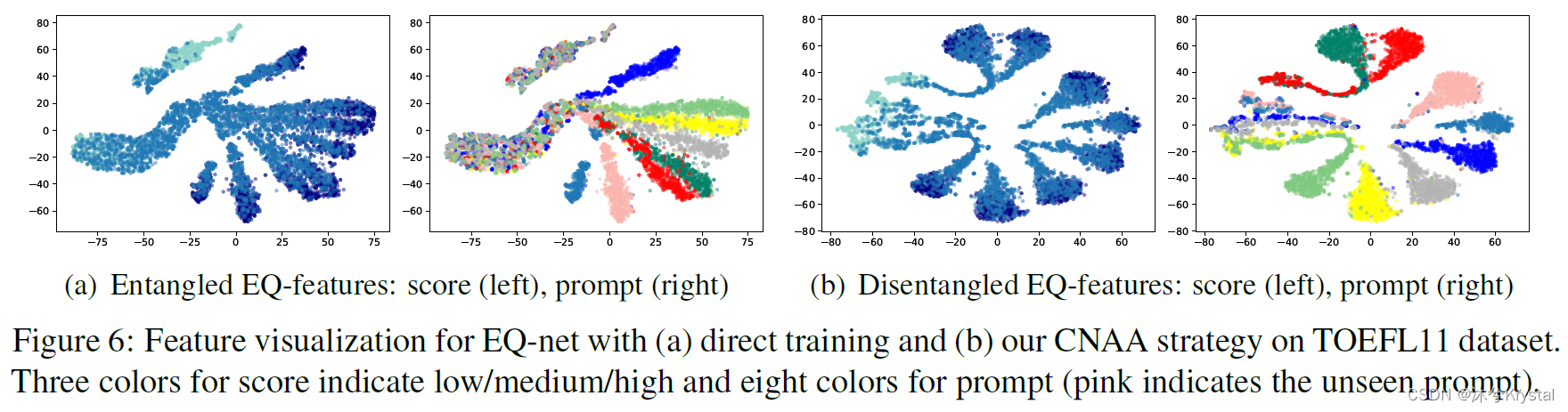
- 展示了EQ-net有和没有CNAA策略时的特征分布。
- (a)图三个等级的分数相对很好的分开了(left),但是不同主题的作文没有完全分开,特别时低分和中等分数的作文。
- (b)图中使用了本文的CNAA策略,分数能够很好的分开根据不同的模长,主题能够很好的分开根据不同的角的方向。