当进行一定程度的微调后,要评价模型输出的语句的准确性。由于衡量的对象是一个个的自然语言文本,所以通常会选择自然语言处理领域的相关评价指标。这些指标原先都是用来度量机器翻译结果质量的,并且被证明可以很好的反映待评测语句的准确性,主要包含4种:BLEU,METEOR,ROUGE,CIDEr。
本文只介绍BLEU,ROUGE两个指标,其他待补充。
1、BLEU
- BLEU(Bilingual Evaluation understudy,双语互译质量评估)是一种流行的机器翻译评价指标,一种基于精确度的相似度量方法,用于分析候选译文中有多少 n 元词组出现在参考译文中(就是在判断两个句子的相似程度)
- BLEU有许多变种,根据n-gram可以划分成多种评价指标,常见的评价指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为 n,BLEU-1衡量的是单词级别的准确性,更高阶的BLEU可以衡量句子的流畅性。
假设, c i c_i ci表示候选译文【也就是机器译文(candidate)】,该候选译文对应的一组参考译文【也就是人工译文(reference)】可以表示为 S i = { s i 1 , s i 2 , … , s i m } \mathrm{S_{i}=\{s_{i1},s_{i2},\ldots,s_{im}\}} Si={si1,si2,…,sim};将候选译文 c i c_i ci中所有相邻的 n 个单词提取出来组成一个集合 n − g r a m n-gram n−gram,一般取 n = 1 , 2 , 3 , 4 n=1,2,3,4 n=1,2,3,4;用 ω k \omega_k ωk表示 n − g r a m n-gram n−gram中的第 k k k 个词组, h k ( c i ) h_k(c_i) hk(ci)表示第k个词组 ω k \omega_k ωk在候选译文 c i c_i ci中出现的次数, h k ( s i j ) h_k(s_{ij}) hk(sij)表示第 k k k 个词组 ω k \omega_k ωk,在参考译文 s i j s_{ij} sij中出现的次数。此时,在n-gram下,参考译文和候选译文 c i c_i ci的匹配度计算公式可以表示为:
p n ( c i , S ) = ∑ k min ( h k ( c i ) , max j ∈ m h k ( s i j ) ) ∑ k h k ( c i ) \mathrm{p_n}\left(\mathrm{c_i},\mathrm{S}\right)=\frac{\sum_{\mathrm{k}}\min\left(\mathrm{h_k}\left(\mathrm{c_i}\right),\max_{\mathrm{j}\in\mathrm{m}}\mathrm{h_k}\left(\mathrm{s_{ij}}\right)\right)}{\sum_{\mathrm{k}}\mathrm{h_k}\left(\mathrm{c_i}\right)} pn(ci,S)=∑khk(ci)∑kmin(hk(ci),maxj∈mhk(sij))
举例说明:
candidate:The cat sat on the mat.
reference:The cat is on the mat
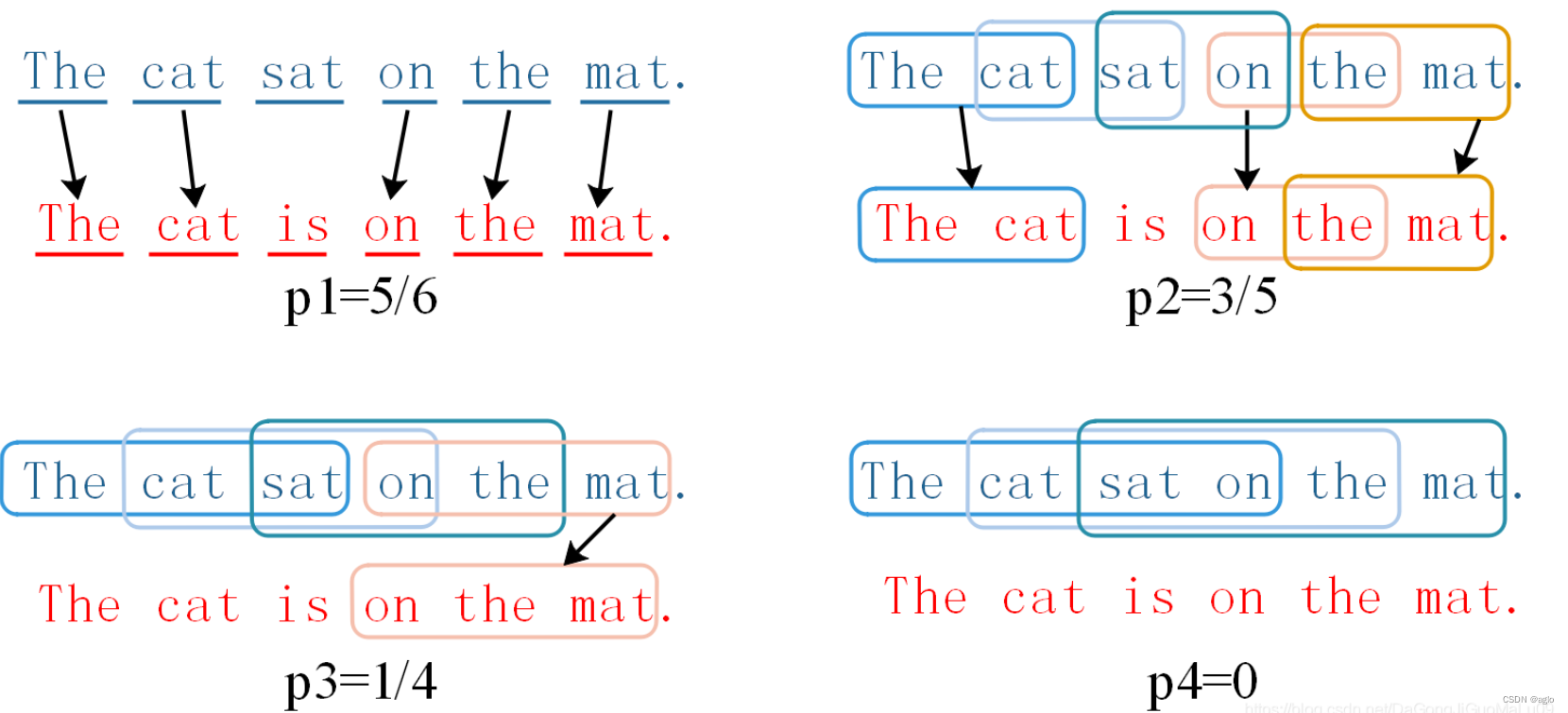
( c a n d i d a t e 和 r e f e r e n c e 中匹配的 n − g r a m 的个数 ) / c a n d i d a t e 中 n − g r a m 的个数 (candidate\text{和}reference\text{中匹配的}n-gram\text{的个数})/candidate\text{中}n-gram\text{的个数} (candidate和reference中匹配的n−gram的个数)/candidate中n−gram的个数
一般来说, n 取值越大,参考译文就越难匹配上,匹配度就会越低. 1 − g r a m 1-gram 1−gram能够反映候选译文中有多少单词被单独翻译出来,也就代表了参考译文的充分性; 2 − g r a m 2-gram 2−gram、 3 − g r a m 3-gram 3−gram、 4 − g r a m 4-gram 4−gram 值越高说明参考译文的可读性越好,也就代表了参考译文的流畅性。
当参考译文比候选译文长(单词更多)时,这种匹配机制可能并不准确,例如上面的参考译文如果是The cat,匹配度就会变成1,这显然是不准确的;为此我们引入一个惩罚因子。
B P ( c i , s i j ) = { 1 , l c i > l s i j e l − l s i j l c i , l c i ≤ l s i j BP(c_i,s_{ij}) = \left\{\begin{matrix} 1\quad ,\quad l_{ci}>l_{s_{ij}} \\ {e^{l-\frac{l_{s_{ij}}}{l_{c_i}}},\quad l_{ci}~\leq l_{sij}} \end{matrix}\right. BP(ci,sij)={1,lci>lsijel−lcilsij,lci ≤lsij
l l l 表示各自的长度。最终,BLEU的计算公式就是
B L E U = B P ⋅ exp ( ∑ n = 1 N w n log p n ) BLEU=BP \cdot \exp \left(\sum_{n=1}^Nw_n \log p_n \right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
w n w_n wn代表每一个 n-gram 的权重,一般 n n n 最大取4,所以 w n = 0.25 w_n = 0.25 wn=0.25 。
BLEU 更偏向于较短的翻译结果,它看重准确率而不注重召回率(n-gram 词组是从候选译文中产生的,参考译文中出现、候选译文中没有的词组并不关心);原论文提议数据集多设置几条候选译文,4条比较好,但是一般的数据集只有一条。
2、ROUGE
BLEU 是统计机器翻译时代的产物,因为机器翻译出来的结果往往不通顺,所以BLEU更关注翻译结果的准确性和流畅度;到了神经网络翻译时代,神经网络很擅长脑补,自己就把语句梳理得很流畅了,这个时候人们更关心的是召回率,也就是参考译文中有多少词组在候选译文中出现了。
关于ROUGE(recall-oriented understanding for gisting evaluation),就是一种基于召回率的相似性度量方法,主要考察参考译文的充分性和忠实性,无法评价参考译文的流畅度,它跟BLEU的计算方式几乎一模一样,但是 n-gram 词组是从参考译文中产生的。分为4种类型:
| ROUGE | 解释 |
|---|---|
| ROUGE-N | 基于 N-gram 的共现(共同出现)统计 |
| ROUGE-L | 基于最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-W | 带权重的最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-S | 不连续二元组共现性精度和召回率 Fmeasure 统计 |
Rouge-1、Rouge-2、Rouge-N
论文[3]中对Rouge-N的定义是这样的:
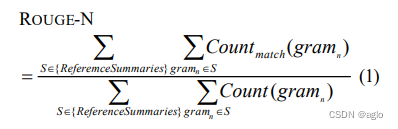
分母是n-gram的个数,分子是参考摘要和自动摘要共有的n-gram的个数。直接借用文章[2]中的例子说明一下:
自动摘要 Y Y Y(一般是自动生成的):
the cat was found under the bed
参考摘要, X 1 X1 X1(gold standard ,人工生成的):
the cat was under the bed
summary的1-gram、2-gram如下,N-gram以此类推:
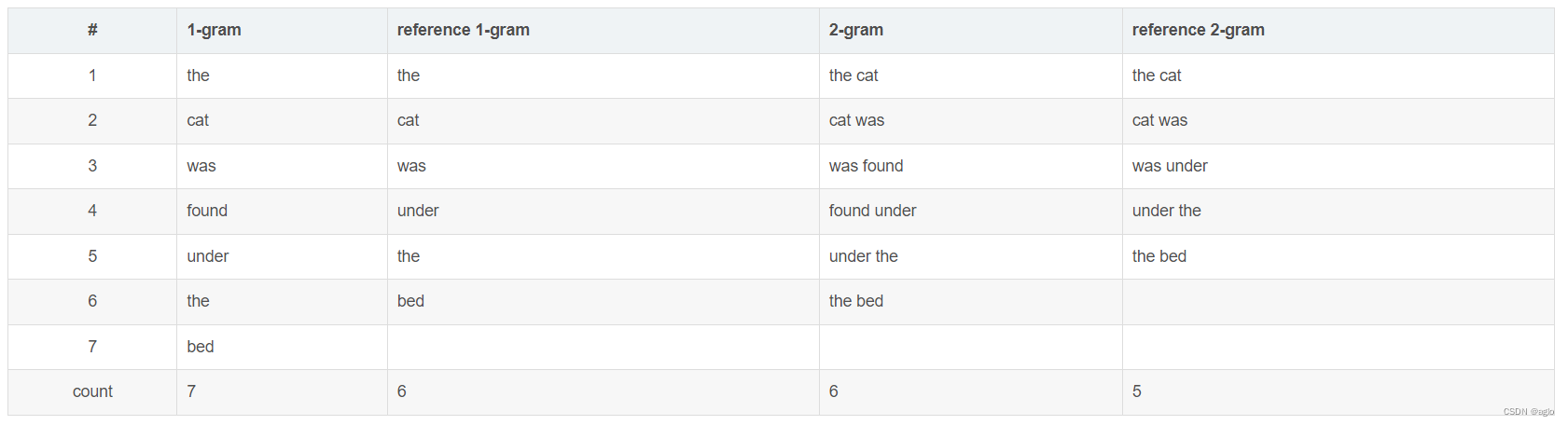
R o u g e _ 1 ( X 1 , Y ) = 6 6 = 1.0 Rouge\_1(X1,Y)=\dfrac66=1.0 Rouge_1(X1,Y)=66=1.0,分子是待评测摘要和参考摘要都出现的1-gram的个数,分子是参考摘要的1-gram个数。(其实分母也可以是待评测摘要的,但是在精确率和召回率之间,我们更关心的是召回率Recall,同时这也和上面ROUGN-N的公式相同)
同样, R o u g e _ 2 ( X 1 , Y ) = 4 5 = 0.8 Rouge\_2(X1,Y)=\dfrac{4}{5}=0.8 Rouge_2(X1,Y)=54=0.8
Rouge-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。Rouge-L计算方式如下:
R l c s = L C S ( X , Y ) m ( 2 ) R_{lcs}=\frac{LCS(X,Y)}m\quad(2) Rlcs=mLCS(X,Y)(2)
P l c s = L C S ( X , Y ) n ( 3 ) P_{lcs}=\frac{LCS(X,Y)}{n}\quad(3) Plcs=nLCS(X,Y)(3)
F l c s = ( 1 + β 2 ) R l c s P l c s R l c s + β 2 P l c s ( 4 ) F_{lcs}=\frac{(1+\beta^2)R_{lcs}P_{lcs}}{R_{lcs}+\beta^2P_{lcs}}\quad(4) Flcs=Rlcs+β2Plcs(1+β2)RlcsPlcs(4)
其中 L C S ( X , Y ) LCS(X,Y) LCS(X,Y)是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度(一般就是所含词的个数), R l c s R_{lcs} Rlcs, P l c s P_{lcs} Plcs分别表示召回率和准确率。最后的 F l c s F_{lcs} Flcs即是我们所说的Rouge-L。在DUC中, β \beta β被设置为一个很大的数,所以 R o u g e _ L Rouge\_L Rouge_L几乎只考虑了 R l c s R_{lcs} Rlcs,与上文所说的一般只考虑召回率对应。
参考文章:
[1].自动文摘评测方法:Rouge-1、Rouge-2、Rouge-L、Rouge-S
[2].What is ROUGE and how it works for evaluation of summaries?
[3].ROUGE:A Package for Automatic Evaluation of Summaries
[4].BLEU评估指标
[5].评价度量指标之BLEU,METEOR,ROUGE,CIDEr