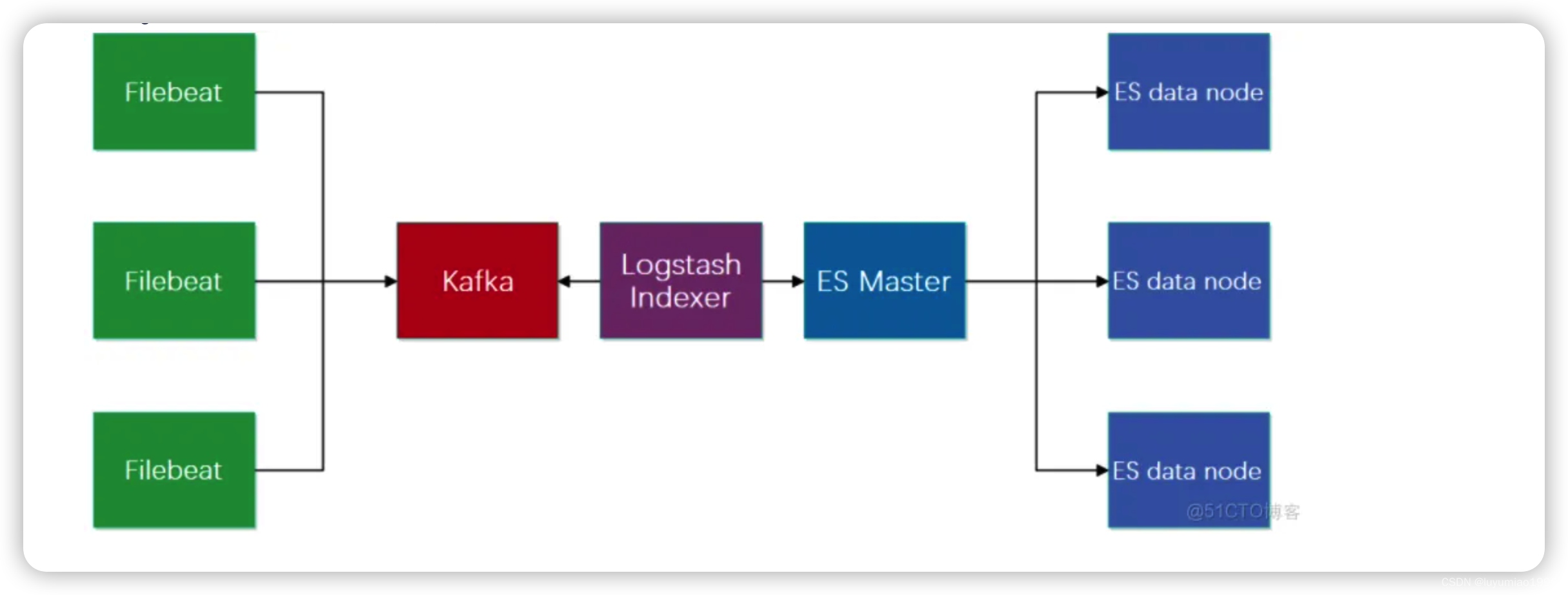
我们非常兴奋地宣布,Amazon Aurora Serverless v2 现已面向 Aurora PostgreSQL 和 MySQL 正式发布。Aurora Serverless 是一种面向 Amazon Aurora 的按需自动扩展配置,可让您的数据库根据应用程序的需求扩展或缩减容量。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
Amazon Aurora 是兼容 MySQL 和 PostgreSQL 且专为云构建的关系数据库。它由 Amazon Relationship Database Service (RDS) 完全托管,该服务可自动执行耗时的管理任务,例如硬件预置、数据库设置、补丁安装和备份。
Amazon Aurora 的主要功能之一是计算和存储的分离。因此,它们可以独立扩展。Amazon Aurora 存储空间会随着数据库中数据量的增加而自动扩展。例如,可以存储大量数据,如果有一天决定删除大部分数据,则会自动调整预置的存储空间。
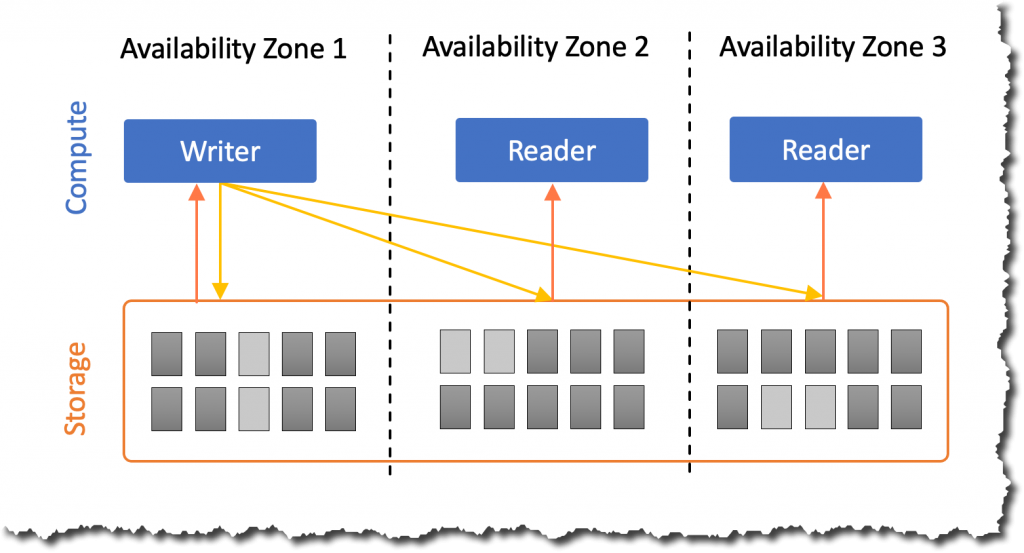
但是,许多客户表示,他们需要在 Amazon Aurora 的计算层中获得同样的灵活性,因为大多数数据库工作负载不需要恒定的计算量。工作负载可以处于尖峰、不频繁的状态,或者在一段时间内出现可预测的峰值。
要为此类工作负载提供服务,您需要预置数据库所需的峰值容量。但是,这种方法的成本很高,因为数据库工作负载很少以峰值容量运行。要预置适当的计算量,您需要持续监控数据库容量消耗情况,并在消耗量较高时扩展资源。但是,这需要具备专业知识,并且经常引发停机。
为了解决此问题,我们于 2018 年推出了第一个版本的 Amazon Aurora Serverless。自推出以来,已有成千上万的客户将 Amazon Aurora Serverless 用作面向不频繁、间歇性和不可预测工作负载的经济高效选择。
今天,我们将正式推出下一版的 Amazon Aurora Serverless,它可让客户借助即时和无中断的扩展、精细的容量调整以及其他功能,包括只读副本、多可用区部署和 Amazon Aurora Global Database,在无服务器上运行要求最苛刻的工作负载。
Aurora Serverless v2 即将推出,其中包含 Amazon Aurora 上提供的最新主要版本。支持的版本:带 PostgreSQL 13 的 Aurora PostgreSQL 兼容版本以及带 MySQL 8.0 的 Aurora MySQL 兼容版本。
Aurora Serverless v2 的主要功能
Aurora Serverless v2 可让将数据库扩展到每秒处理数十万个事务,并经济高效地管理要求最苛刻的工作负载。它以精细的增量扩展数据库容量,以密切满足工作负载的需求,而不会中断连接或事务。此外,您只需按实际使用的容量付费,与针对峰值负载预置相比,最多可节省 90% 的费用。
如果您具备现有的 Amazon Aurora 集群,则可以在同一集群中创建 Aurora Serverless v2 实例。这样,您将拥有一个混合配置集群,其中预置实例和 Aurora Serverless v2 实例可以在同一个集群中共存。
它支持 Amazon Aurora 的全部功能。例如,您可以创建跨多个可用区部署的最多 15 个 Amazon Aurora 只读副本。其中任意数量的只读副本都可以是 Aurora Serverless v2 实例,并且可以用作实现高可用性或扩展读取操作的故障转移目标。
同样,使用 Global Database,您可以将任何实例分配给 Aurora Serverless v2,并且在空闲时仅需支付最低容量费用。辅助区域中的这些实例还可以独立扩展,以支持不同区域之间的不同工作负载。请查看 Amazon Aurora 用户指南,了解完整的功能列表。
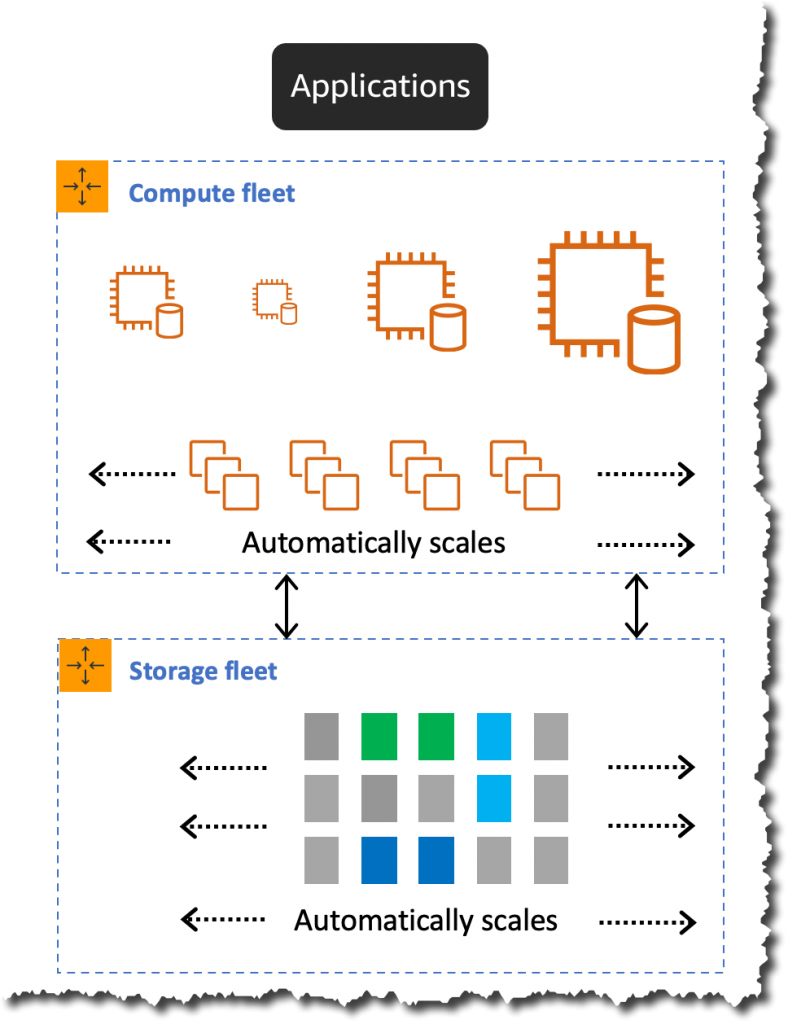
Aurora Serverless v2 扩展的工作原理
Aurora Serverless v2 通过添加更多 CPU 和内存资源来增加现有底层实例的容量,从而实现即时、无中断的扩展。此技术可实现底层实例的增加和现有容量的降低,而无需故障转移到新实例进行扩展。
对于容量缩减,Aurora Serveless v2 采用了更为保守的方法。它会逐步缩减,直到达到工作负载所需的容量。缩减速度过快会过早地移出缓存的页面并减少缓冲区池,这可能会影响性能。
Aurora Serverless 容量以 Aurora 容量单位 (ACU) 来衡量。每个 ACU 由大约 2 吉字节 (GiB) 的内存、相应的 CPU 和网络组成。使用 Aurora Serverless v2,您的起始容量可以小至 0.5 ACU,而支持的最大容量为 128 ACU。此外,它还支持小至 0.5 ACU 的精细增量,让您的数据库容量与工作负载需求紧密相符。
Aurora Serverless v2 扩展的实际应用
为了展示 Aurora Serverless v2 的实际应用,我们将模拟一次限时抢购。设想一下,您经营一家电子商务网站。您开展营销活动,客户可以在有限的时间内以 50% 的折扣价格购买商品。您预计在销售期间网站的流量将会激增。
使用传统数据库时,如果定期开展这些营销活动,则需要为预期的峰值负载进行预置。或者,如果不时开展营销活动,则需要重新配置数据库,以应对销售期间的预期流量峰值。在这两种情况下,您都只能假设所需的容量。如果销售量超出预期,会发生什么情况? 如果您的数据库无法应对不断增长的需求,就可能会导致服务降级。或者,如果营销活动没有产生预期的销售量,又会发生什么情况? 您为不需要的容量支付不必要的付费。
在本演示中,我们使用 Aurora Serverless v2 作为事务数据库。Amazon Lambda 函数用于在电子商务网站的销售活动期间调用数据库和处理订单。此 Lambda 函数和数据库位于同一 Amazon Virtual Private Cloud (VPC) 中,并且该函数直接连接到数据库以执行所有操作。
为了模拟限时抢购的流量,我们将使用名为 Artillery 的开源负载测试框架。借助该框架,我们可通过调用多个 Lambda 函数来生成不同的负载。例如,我们可以从小规模负载开始,然后快速增加负载,以观察数据库容量如何根据工作负载进行调整。此 Artillery 负载测试在同一 VPC 内的 Amazon Elastic Compute Cloud (Amazon EC2) 实例上运行。
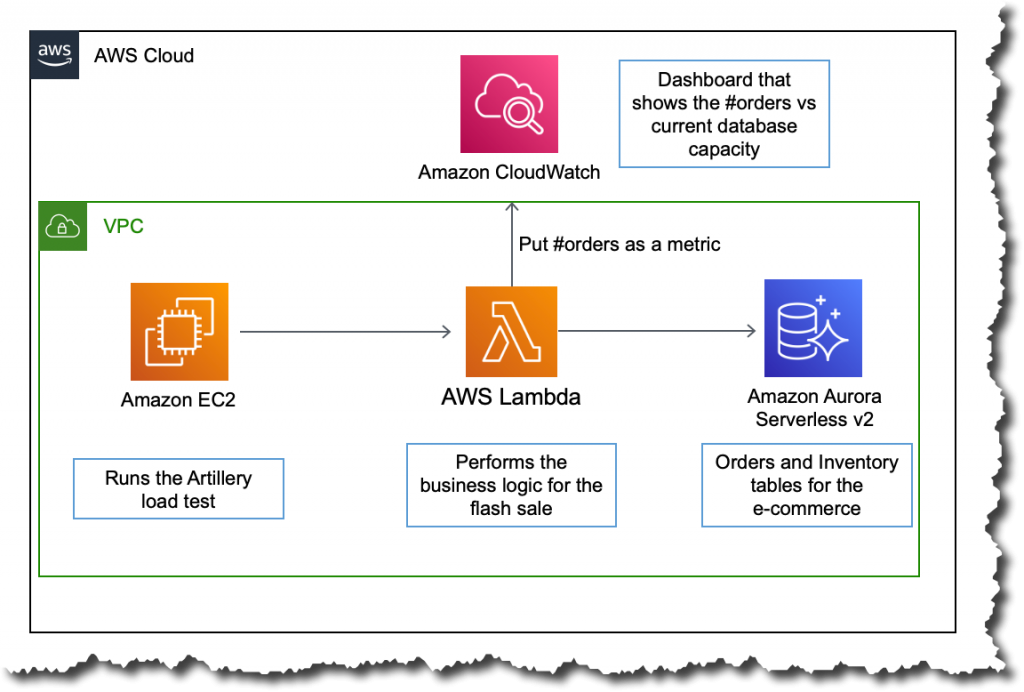
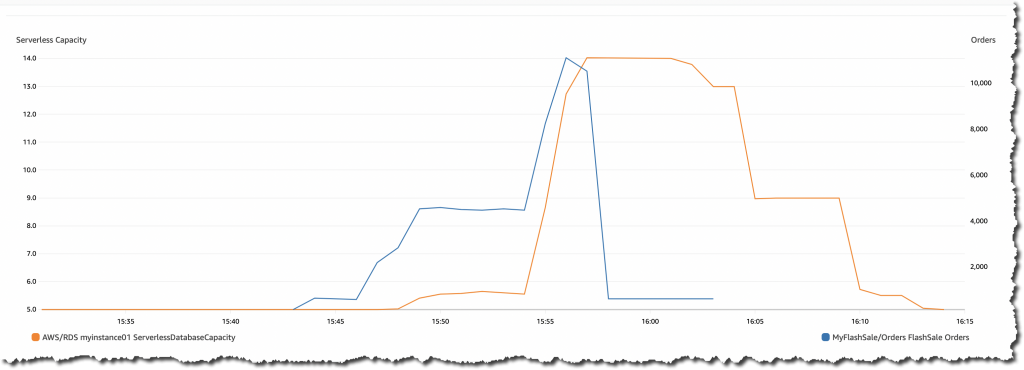
以下 Amazon CloudWatch 控制面板显示订单数量增加时数据库容量的行为。该控制面板以蓝色显示所下订单,以橙色显示当前数据库容量。
在销售开始时,Aurora Serverless v2 数据库的起始容量为 5 个 ACU,这是配置的最低数据库容量。在最初的几分钟内,订单量会增加,但数据库容量不会立即增加。数据库可以使用起始预置容量来处理负载。
但是,大约在 15:55 左右,订单量激增至 12,000 份。因此,数据库将容量增加到 14 个 ACU。数据库容量在几毫秒内快速增加,完全根据负载进行调整。
大量的订单保持了几秒钟,然后在 15:58 之前急剧下降。但是,数据库容量并非完全根据流量的下降进行调整。相反,它会逐步减小,直到达到 5 个 ACU。容量缩减更为保守,以避免过早移出缓存的页面并影响性能。这样做是为了防止峰值工作负载出现任何不必要的处理延迟,并且不会主动清除缓存和缓冲区池。
借助现有 Amazon Aurora 集群开始使用 Aurora Serverless v2
如果您已拥有 Amazon Aurora 集群,并且想要试用 Aurora Serverless v2,则最快的入门方法是使用同时包含无服务器实例和预置实例的混合配置集群。首先在现有集群中添加新的读取器。将该读取器实例配置为 Serverless v2 类型。
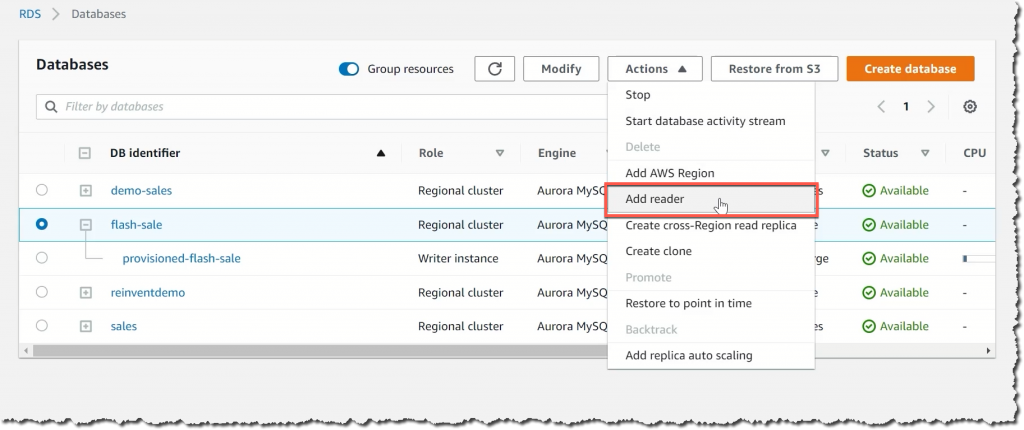
使用工作负载测试新的无服务器实例。确认无服务器实例按预期工作后,就可以开始故障转移到无服务器实例,仅需花费不到 30 秒的时间即可完成操作。此选项为开始使用 Aurora Serverless v2 提供了最短的停机时间。
如何新建 Aurora Serverless v2 数据库
要开始使用 Aurora Serverless v2,请从 RDS 控制台新建数据库。第一步是选择引擎类型:Amazon Aurora。 然后,选择希望与哪个数据库引擎兼容:MySQL 或 PostgreSQL。打开“引擎”版本下的筛选条件,然后选择筛选条件显示支持 Serverless v2 的版本。然后,您会看到可用版本下拉列表仅显示 Aurora Serverless v2 支持的选项。
接下来,您需要设置数据库。 使用数据库管理员的用户名和密码指定凭证设置。
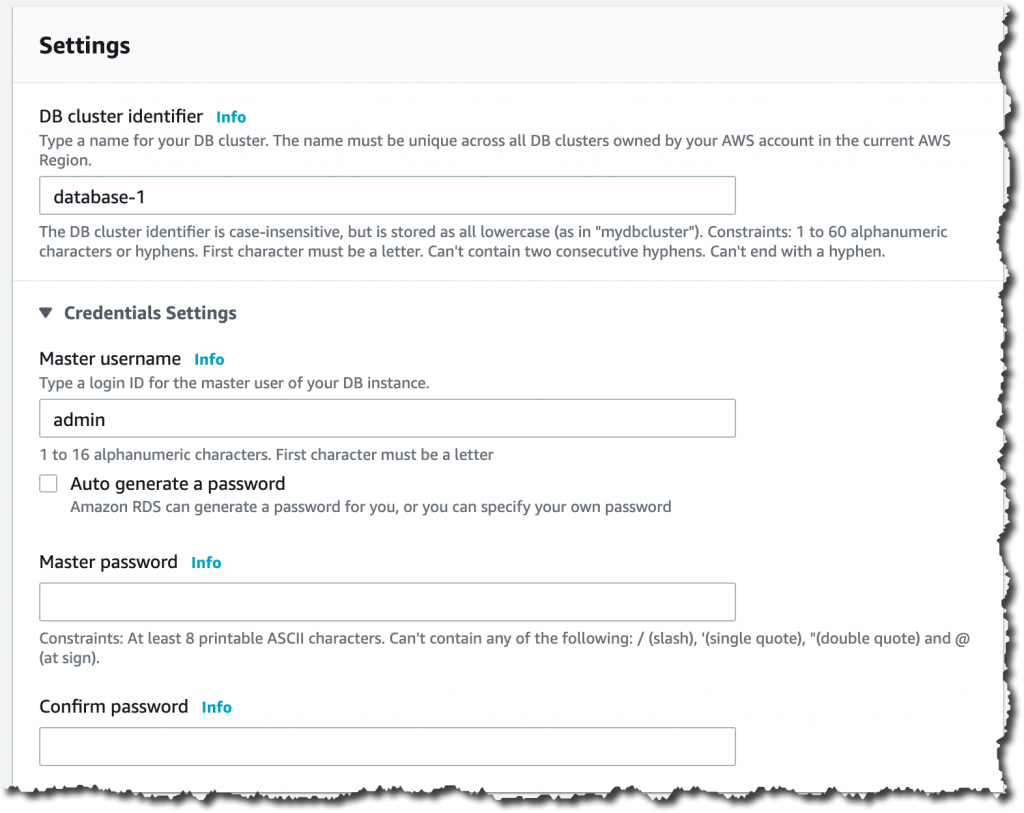
然后,为数据库配置实例。您需要选择所需的实例类别。这将为数据库实例分配计算、网络和内存容量。选择无服务器。
然后,您需要定义容量范围。Aurora Serverless v2 容量可在最小和最大配置范围内扩展与缩减。可以在此处指定适用于工作负载的最小和最大数据库容量。可以指定的最小容量为 0.5 个 ACU,最大容量为 128 个 ACU。有关 Aurora Serverless v2 容量单位的更多信息,请参阅即时自动扩展文档。
接下来,通过新建 VPC 和安全组或使用默认值来配置连接。最后,选择创建数据库。
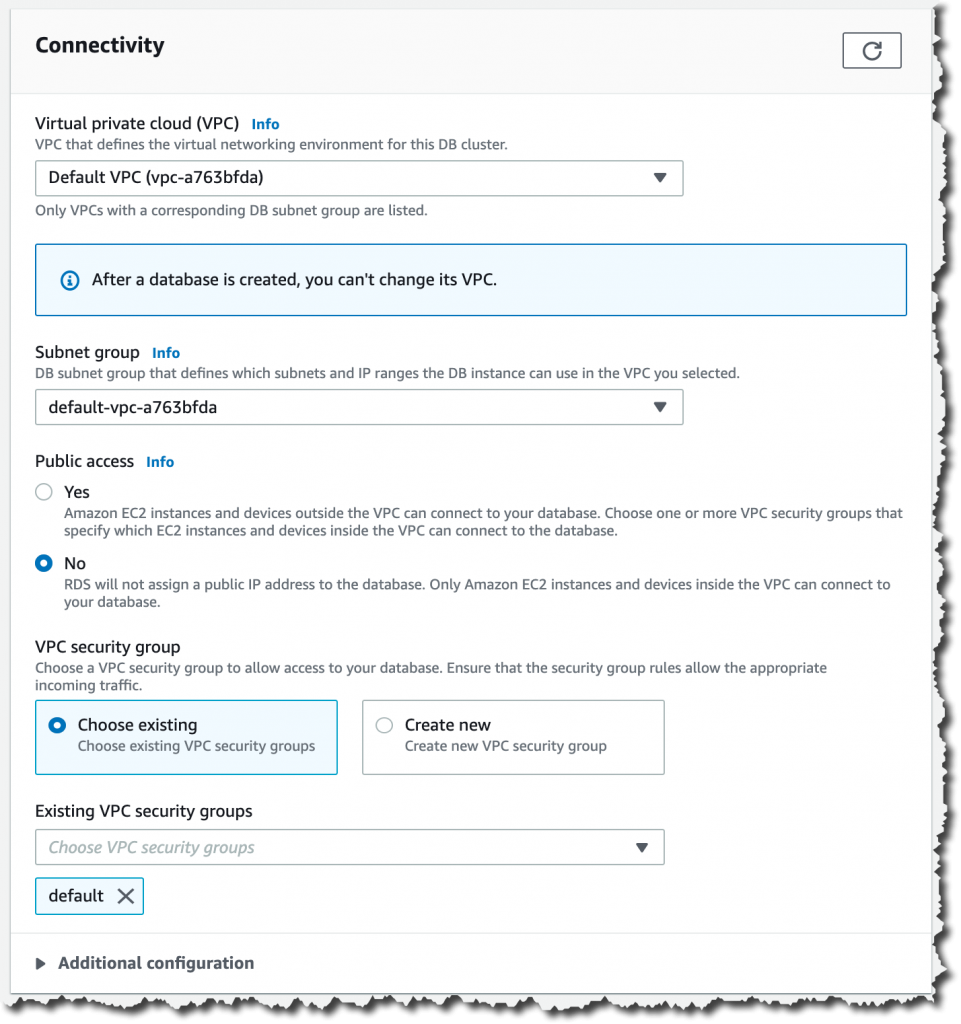
创建数据库需要几分钟的时间。当状态切换为可用时,就可知道数据库已准备就绪。

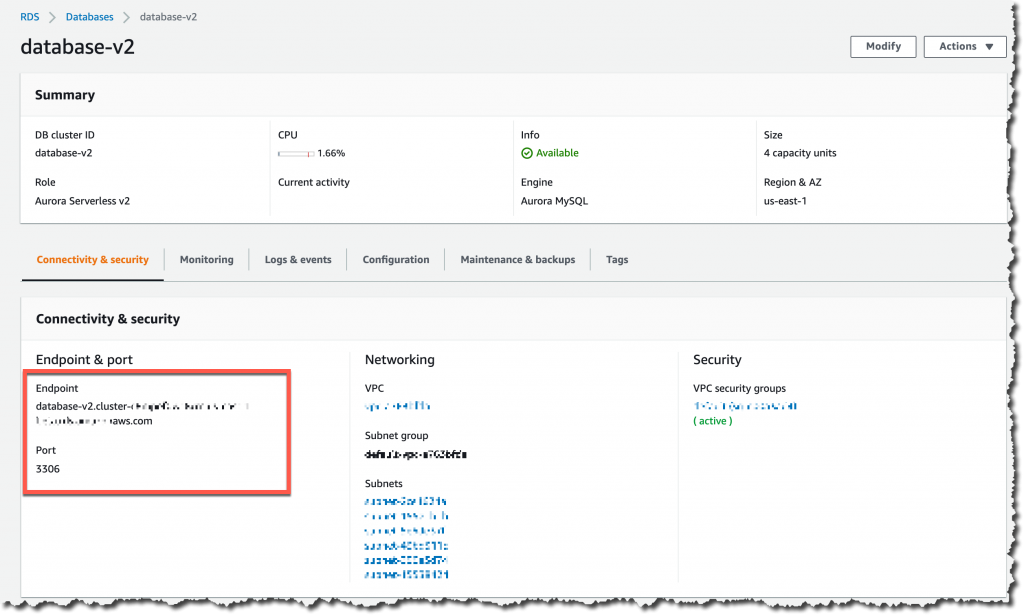
您可以在数据库页面上找到数据库的连接详细信息。要连接到新的 Aurora Serverless v2 数据库,唯一需要的是端点和端口以及管理员的用户名和密码。
现已推出!
Aurora Serverless v2 现已在以下区域推出:美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(加利福尼亚北部)、美国西部(俄勒冈)、亚太地区(香港)、亚太地区(孟买)、亚太地区(首尔)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、加拿大(中部)、欧洲(法兰克福)、欧洲(爱尔兰)、欧洲(伦敦)、欧洲(巴黎)、欧洲(斯德哥尔摩)和南非(圣保罗)。
有关此次发布的更多信息,请访问 Amazon Aurora Serverless v2 页面。
– Marcia
文章来源:https://dev.amazoncloud.cn/column/article/6309dadde0f88a79bcfae806?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN