1 PostgreSQL并行参数
系统参数
- 系统总worker限制:max_worker_processes
- 默认8
- 系统总并发限制:max_parallel_workers
- 默认8
- 单Query限制:max_parallel_workers_per_gather
- 默认2
- 表参数限制:parallel_workers
alter table tbl set (parallel_workers=32);- 默认系统自动按大小配置:“If not set, the system will determine a value based on the relation size.”
代价
- parallel_tuple_cost
- 默认0.1
- parallel_setup_cost
- 默认1000
最低启动标准
- min_parallel_table_scan_size
- 默认8MB
- min_parallel_index_scan_size
- 默认512KB
强制启动并行
- force_parallel_mode
- 默认off
2 PostgreSQL并行实例
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student select t.a, substring(md5(random()::text), 1, 5), t.a % 2 from generate_series(1, 10000000) t(a);
analyze student;postgres=# show max_worker_processes;max_worker_processes
----------------------8
(1 row)postgres=# show max_parallel_workers;max_parallel_workers
----------------------8
(1 row)postgres=# show max_parallel_workers_per_gather;max_parallel_workers_per_gather
---------------------------------2
(1 row)postgres=# set parallel_tuple_cost =0;
SETpostgres=# explain analyze select * from student;QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..96721.08 rows=9999860 width=14) (actual time=1.139..2835.438 rows=10000000 loops=1)Workers Planned: 2Workers Launched: 2-> Parallel Seq Scan on student (cost=0.00..95721.08 rows=4166608 width=14) (actual time=0.023..1023.705 rows=3333333 loops=3)Planning Time: 0.053 msExecution Time: 4075.993 ms
4并发
postgres=# set parallel_tuple_cost = 0;
SET
postgres=# set max_parallel_workers_per_gather = 4;
SET
postgres=# alter table student set (parallel_workers=4);
ALTER TABLE
postgres=# explain analyze select * from student;QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------Gather (cost=1000.00..80054.65 rows=9999860 width=14) (actual time=0.171..2767.117 rows=10000000 loops=1)Workers Planned: 4Workers Launched: 4-> Parallel Seq Scan on student (cost=0.00..79054.65 rows=2499965 width=14) (actual time=0.251..580.363 rows=2000000 loops=5)Planning Time: 0.084 msExecution Time: 4009.665 ms
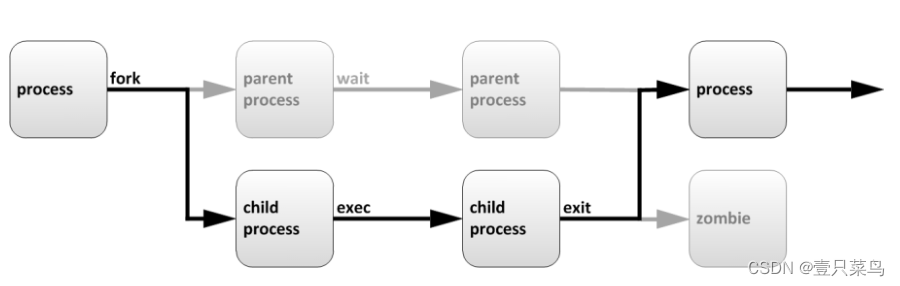
3 PostgreSQL并行执行过程分析
(以4并发算子为例)
执行器位置:ExecutePlan
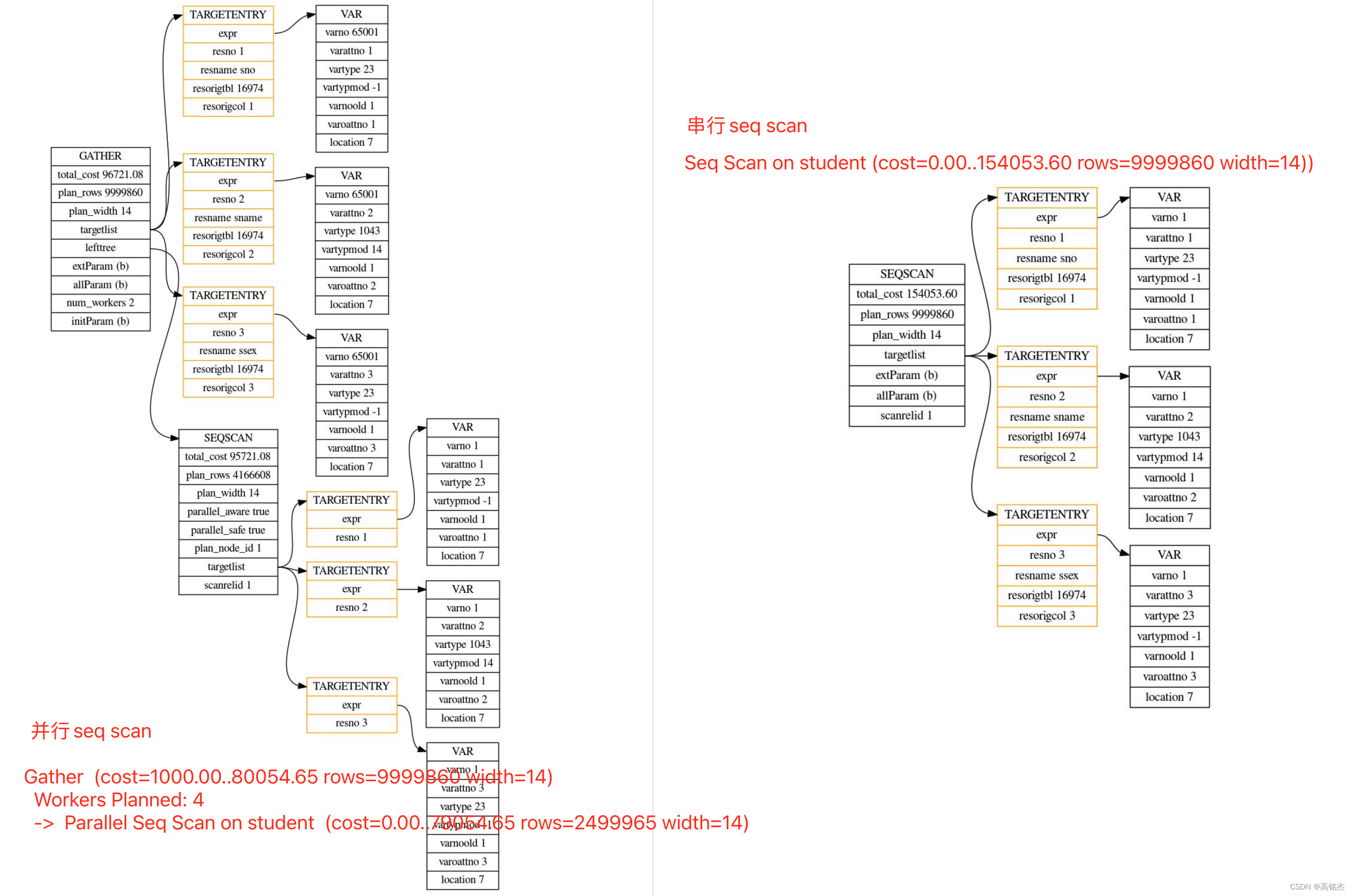
进入ExecutePlan时执行计划有什么区别?
并行计划
postgres=# explain select * from student;QUERY PLAN
---------------------------------------------------------------------------------Gather (cost=1000.00..80054.65 rows=9999860 width=14)Workers Planned: 4-> Parallel Seq Scan on student (cost=0.00..79054.65 rows=2499965 width=14)
串行计划
postgres=# explain select * from student;QUERY PLAN
-------------------------------------------------------------------Seq Scan on student (cost=0.00..154053.60 rows=9999860 width=14)
并行计划没有什么特殊的地方,并行逻辑基本都在ExecGather函数中实现的:
并行框架API的使用位置,核心流程:在第三步到第四步之间,即启动并行work,从并行结果中取到tuple并返回。
ExecutePlan...EnterParallelMode(); -- 第一步...for (;;)...slot = ExecProcNode(planstate);...ExecGather...ExecInitParallelPlan...InitializeParallelDSM -- 第二步...LaunchParallelWorkers -- 第三步...ExecParallelCreateReaders...gather_getnextgather_readnextif (readerdone)ExecShutdownGatherWorkersWaitForParallelWorkersToFinish -- 第四步......ExecShutdownNodeExecShutdownNode_walkerExecShutdownGatherExecParallelCleanupDestroyParallelContext -- 第五步ExitParallelModeExitParallelMode -- 第六步
4 README.parallel in PG11
Overview
========PostgreSQL provides some simple facilities to make writing parallel algorithms
easier. Using a data structure called a ParallelContext, you can arrange to
launch background worker processes, initialize their state to match that of
the backend which initiated parallelism, communicate with them via dynamic
shared memory, and write reasonably complex code that can run either in the
user backend or in one of the parallel workers without needing to be aware of
where it's running.The backend which starts a parallel operation (hereafter, the initiating
backend) starts by creating a dynamic shared memory segment which will last
for the lifetime of the parallel operation. This dynamic shared memory segment
will contain (1) a shm_mq that can be used to transport errors (and other
messages reported via elog/ereport) from the worker back to the initiating
backend; (2) serialized representations of the initiating backend's private
state, so that the worker can synchronize its state with of the initiating
backend; and (3) any other data structures which a particular user of the
ParallelContext data structure may wish to add for its own purposes. Once
the initiating backend has initialized the dynamic shared memory segment, it
asks the postmaster to launch the appropriate number of parallel workers.
These workers then connect to the dynamic shared memory segment, initiate
their state, and then invoke the appropriate entrypoint, as further detailed
below.
PostgreSQL提供了一些简单的工具,使编写并行算法更加容易。使用称为ParallelContext的数据结构,您可以安排启动后台工作进程,将它们的状态初始化为与启动并行性的后端相匹配,通过动态共享内存与它们进行通信,并编写可以在用户后端或其中一个并行工作进程中运行的相当复杂的代码,而无需知道它在哪里运行。
启动并行操作的后端(以下简称为启动后端)首先创建一个动态共享内存段,该段将在并行操作的生命周期内持续存在。该动态共享内存段将包含(1)一个shm_mq,可用于将错误(以及通过elog/ereport报告的其他消息)从工作进程传输回启动后端;(2)启动后端的私有状态的序列化表示,以便工作进程可以将其状态与启动后端的状态同步;以及(3)ParallelContext数据结构的特定用户可能希望添加的任何其他数据结构,以满足其自身的目的。一旦启动后端初始化了动态共享内存段,它会要求postmaster启动适当数量的并行工作进程。然后,这些工作进程连接到动态共享内存段,初始化其状态,然后调用适当的入口点,如下面的详细信息所述。
Error Reporting
===============When started, each parallel worker begins by attaching the dynamic shared
memory segment and locating the shm_mq to be used for error reporting; it
redirects all of its protocol messages to this shm_mq. Prior to this point,
any failure of the background worker will not be reported to the initiating
backend; from the point of view of the initiating backend, the worker simply
failed to start. The initiating backend must anyway be prepared to cope
with fewer parallel workers than it originally requested, so catering to
this case imposes no additional burden.Whenever a new message (or partial message; very large messages may wrap) is
sent to the error-reporting queue, PROCSIG_PARALLEL_MESSAGE is sent to the
initiating backend. This causes the next CHECK_FOR_INTERRUPTS() in the
initiating backend to read and rethrow the message. For the most part, this
makes error reporting in parallel mode "just work". Of course, to work
properly, it is important that the code the initiating backend is executing
CHECK_FOR_INTERRUPTS() regularly and avoid blocking interrupt processing for
long periods of time, but those are good things to do anyway.(A currently-unsolved problem is that some messages may get written to the
system log twice, once in the backend where the report was originally
generated, and again when the initiating backend rethrows the message. If
we decide to suppress one of these reports, it should probably be second one;
otherwise, if the worker is for some reason unable to propagate the message
back to the initiating backend, the message will be lost altogether.)每个并行工作者在启动时,都会附加动态共享内存段,并定位用于错误报告的 shm_mq;它会将所有的协议消息重定向到这个 shm_mq。在此之前,后台工作者的任何失败都不会报告给启动的后端;从启动的后端的角度来看,工作者只是未能启动。启动的后端必须始终准备好应对比它最初请求的并行工作者少的情况,因此为这种情况提供支持并不会增加额外的负担。
每当有新的消息(或部分消息;非常大的消息可能会换行)发送到错误报告队列时,会向启动的后端发送 PROCSIG_PARALLEL_MESSAGE 信号。这会导致启动的后端在下一个 CHECK_FOR_INTERRUPTS() 中读取并重新抛出消息。大部分情况下,这使得并行模式下的错误报告“正常工作”。当然,为了正常工作,重要的是启动的后端的代码定期执行 CHECK_FOR_INTERRUPTS(),并避免长时间阻塞中断处理,但这些都是好的做法。
(目前尚未解决的问题是,有些消息可能会在系统日志中写入两次,一次是在生成报告的后端,一次是在启动的后端重新抛出消息时。如果我们决定抑制其中一个报告,应该是第二个报告;否则,如果由于某种原因工作者无法将消息传播回启动的后端,消息将会完全丢失。)
State Sharing
=============It's possible to write C code which works correctly without parallelism, but
which fails when parallelism is used. No parallel infrastructure can
completely eliminate this problem, because any global variable is a risk.
There's no general mechanism for ensuring that every global variable in the
worker will have the same value that it does in the initiating backend; even
if we could ensure that, some function we're calling could update the variable
after each call, and only the backend where that update is performed will see
the new value. Similar problems can arise with any more-complex data
structure we might choose to use. For example, a pseudo-random number
generator should, given a particular seed value, produce the same predictable
series of values every time. But it does this by relying on some private
state which won't automatically be shared between cooperating backends. A
parallel-safe PRNG would need to store its state in dynamic shared memory, and
would require locking. The parallelism infrastructure has no way of knowing
whether the user intends to call code that has this sort of problem, and can't
do anything about it anyway.
在没有并行性的情况下,编写的C代码可能可以正常工作,但在使用并行性时可能会失败。没有并行基础设施可以完全消除这个问题,因为任何全局变量都存在风险。没有通用机制可以确保每个工作进程中的全局变量与启动后端中的值相同;即使我们可以确保这一点,我们调用的某些函数在每次调用后可能会更新变量,并且只有执行更新的后端才会看到新值。我们选择使用的任何更复杂的数据结构都可能出现类似的问题。例如,伪随机数生成器应该在给定特定种子值的情况下,每次都产生相同可预测的数列。但它依赖于一些私有状态,这些状态不会自动在协作后端之间共享。一个并行安全的伪随机数生成器需要将其状态存储在动态共享内存中,并需要锁定。并行性基础设施无法知道用户是否打算调用具有此类问题的代码,也无法对此采取任何措施。
Instead, we take a more pragmatic approach. First, we try to make as many of
the operations that are safe outside of parallel mode work correctly in
parallel mode as well. Second, we try to prohibit common unsafe operations
via suitable error checks. These checks are intended to catch 100% of
unsafe things that a user might do from the SQL interface, but code written
in C can do unsafe things that won't trigger these checks. The error checks
are engaged via EnterParallelMode(), which should be called before creating
a parallel context, and disarmed via ExitParallelMode(), which should be
called after all parallel contexts have been destroyed. The most
significant restriction imposed by parallel mode is that all operations must
be strictly read-only; we allow no writes to the database and no DDL. We
might try to relax these restrictions in the future.
相反,我们采取更实用的方法。首先,我们尝试使尽可能多的在没有并行模式的情况下安全的操作在并行模式下也能正常工作。其次,我们通过适当的错误检查来禁止常见的不安全操作。这些检查旨在捕获用户可能通过SQL接口执行的100%不安全操作,但使用C编写的代码可能会执行不会触发这些检查的不安全操作。错误检查通过EnterParallelMode()函数启用,在创建并行上下文之前应调用该函数,并通过ExitParallelMode()函数解除,应在销毁所有并行上下文之后调用该函数。并行模式强加的最重要的限制是所有操作必须严格为只读;我们不允许对数据库进行写操作,也不允许进行DDL操作。我们可能会在将来尝试放宽这些限制。
To make as many operations as possible safe in parallel mode, we try to copy
the most important pieces of state from the initiating backend to each parallel
worker. This includes:- The set of libraries dynamically loaded by dfmgr.c.- The authenticated user ID and current database. Each parallel workerwill connect to the same database as the initiating backend, using thesame user ID.- The values of all GUCs. Accordingly, permanent changes to the value ofany GUC are forbidden while in parallel mode; but temporary changes,such as entering a function with non-NULL proconfig, are OK.- The current subtransaction's XID, the top-level transaction's XID, andthe list of XIDs considered current (that is, they are in-progress orsubcommitted). This information is needed to ensure that tuple visibilitychecks return the same results in the worker as they do in theinitiating backend. See also the section Transaction Integration, below.- The combo CID mappings. This is needed to ensure consistent answers totuple visibility checks. The need to synchronize this data structure isa major reason why we can't support writes in parallel mode: such writesmight create new combo CIDs, and we have no way to let other workers(or the initiating backend) know about them.- The transaction snapshot.- The active snapshot, which might be different from the transactionsnapshot.- The currently active user ID and security context. Note that this isthe fourth user ID we restore: the initial step of binding to the correctdatabase also involves restoring the authenticated user ID. When GUCvalues are restored, this incidentally sets SessionUserId and OuterUserIdto the correct values. This final step restores CurrentUserId.- State related to pending REINDEX operations, which prevents access toan index that is currently being rebuilt.To prevent unprincipled deadlocks when running in parallel mode, this code
also arranges for the leader and all workers to participate in group
locking. See src/backend/storage/lmgr/README for more details.
为了在并行模式下使尽可能多的操作安全,我们尝试从启动后端复制最重要的状态片段到每个并行工作进程中。这包括:
-
dfmgr.c动态加载的库集合。
-
已认证的用户ID和当前数据库。每个并行工作进程将使用与发起后端相同的用户ID连接到同一个数据库。
-
所有GUC变量的值。因此,在并行模式下禁止对任何GUC变量的永久更改;但是临时更改,如使用非NULL proconfig进入函数,是可以的。
-
当前子事务的XID、顶层事务的XID以及被视为当前的XID列表(即正在进行中或子提交)。这些信息需要确保元组的可见性检查在工作进程中返回的结果与在发起后端中返回的结果相同。更多信息请参考下面的“事务集成”部分。
-
combo CID映射。这是为确保元组可见性检查的一致答案所需的。同步此数据结构的需求是我们无法在并行模式下支持写操作的一个重要原因:这样的写操作可能会创建新的combo CID,而我们无法让其他工作进程(或者发起后端)知道它们。
-
事务快照。
-
活跃快照,可能与事务快照不同。
-
当前活跃的用户ID和安全上下文。请注意,这是我们恢复的第四个用户ID:绑定到正确的数据库的初始步骤还涉及恢复已认证的用户ID。当恢复GUC值时,这无意中将SessionUserId和OuterUserId设置为正确的值。最后一步是还原CurrentUserId。
-
与待处理REINDEX操作相关的状态,这会阻止访问当前正在重建的索引。
为了防止并行模式下的非原则性死锁,此代码还安排领导者和所有工作进程参与组锁定。有关更多详细信息,请参阅src/backend/storage/lmgr/README文件。
Transaction Integration
=======================Regardless of what the TransactionState stack looks like in the parallel
leader, each parallel worker ends up with a stack of depth 1. This stack
entry is marked with the special transaction block state
TBLOCK_PARALLEL_INPROGRESS so that it's not confused with an ordinary
toplevel transaction. The XID of this TransactionState is set to the XID of
the innermost currently-active subtransaction in the initiating backend. The
initiating backend's toplevel XID, and the XIDs of all current (in-progress
or subcommitted) XIDs are stored separately from the TransactionState stack,
but in such a way that GetTopTransactionId(), GetTopTransactionIdIfAny(), and
TransactionIdIsCurrentTransactionId() return the same values that they would
in the initiating backend. We could copy the entire transaction state stack,
but most of it would be useless: for example, you can't roll back to a
savepoint from within a parallel worker, and there are no resources to
associated with the memory contexts or resource owners of intermediate
subtransactions.
无论并行leader的TransactionState堆栈看起来如何,每个并行worker最终都会拥有一个深度为1的堆栈。此堆栈条目使用特殊的事务块状态TBLOCK_PARALLEL_INPROGRESS标记,以避免与普通的顶层事务混淆。这个TransactionState的XID被设置为启动后台进程中当前活动子事务的最内层XID。启动后台进程的顶层XID以及所有当前(正在进行或已提交)的XID被单独存储在TransactionState堆栈之外,但是以一种使得GetTopTransactionId()、GetTopTransactionIdIfAny()和TransactionIdIsCurrentTransactionId()返回与启动后台进程中相同值的方式存储。我们可以复制整个事务状态堆栈,但其中大部分是无用的:例如,在并行worker中无法回滚到保存点,并且不存在与中间子事务的内存上下文或资源所有者相关联的资源。
No meaningful change to the transaction state can be made while in parallel
mode. No XIDs can be assigned, and no subtransactions can start or end,
because we have no way of communicating these state changes to cooperating
backends, or of synchronizing them. It's clearly unworkable for the initiating
backend to exit any transaction or subtransaction that was in progress when
parallelism was started before all parallel workers have exited; and it's even
more clearly crazy for a parallel worker to try to subcommit or subabort the
current subtransaction and execute in some other transaction context than was
present in the initiating backend. It might be practical to allow internal
sub-transactions (e.g. to implement a PL/pgSQL EXCEPTION block) to be used in
parallel mode, provided that they are XID-less, because other backends
wouldn't really need to know about those transactions or do anything
differently because of them. Right now, we don't even allow that.
在并行模式下,不能对事务状态进行任何有意义的更改。不能分配任何XID,也不能启动或结束子事务,因为我们无法将这些状态更改通知给协作后端,也无法进行同步。很明显,在所有并行工作者退出之前,启动后端无法退出正在进行中的任何事务或子事务;而对于并行工作者来说,尝试在当前子事务中提交或中止,并以与启动后端不同的事务上下文执行,显然是荒谬的。允许在并行模式中使用内部子事务(例如,实现PL/pgSQL的异常块)可能是可行的,只要它们没有XID,因为其他后端对于这些事务的存在并不需要了解或做出任何不同的操作。但是目前,我们甚至都不允许这样做。
At the end of a parallel operation, which can happen either because it
completed successfully or because it was interrupted by an error, parallel
workers associated with that operation exit. In the error case, transaction
abort processing in the parallel leader kills of any remaining workers, and
the parallel leader then waits for them to die. In the case of a successful
parallel operation, the parallel leader does not send any signals, but must
wait for workers to complete and exit of their own volition. In either
case, it is very important that all workers actually exit before the
parallel leader cleans up the (sub)transaction in which they were created;
otherwise, chaos can ensue. For example, if the leader is rolling back the
transaction that created the relation being scanned by a worker, the
relation could disappear while the worker is still busy scanning it. That's
not safe.
在并行操作结束时,可能是因为操作成功完成,也可能是因为被错误中断,与该操作相关联的并行工作者退出。在出现错误的情况下,主导并行事务中的事务中止处理会终止剩余的工作者,并等待它们退出。在成功进行并行操作的情况下,主导并行事务不发送任何信号,但必须等待工作者自行完成并退出。无论哪种情况,都非常重要的是,在并行主导清理创建它们的(子)事务之前,所有工作者都要确实退出;否则,可能会引发混乱。例如,如果主导正在回滚创建由工作者扫描的关系的事务,则在工作者仍忙于扫描时,该关系可能会消失。这是不安全的。
Generally, the cleanup performed by each worker at this point is similar to
top-level commit or abort. Each backend has its own resource owners: buffer
pins, catcache or relcache reference counts, tuple descriptors, and so on
are managed separately by each backend, and must free them before exiting.
There are, however, some important differences between parallel worker
commit or abort and a real top-level transaction commit or abort. Most
importantly:- No commit or abort record is written; the initiating backend isresponsible for this.- Cleanup of pg_temp namespaces is not done. Parallel workers cannotsafely access the initiating backend's pg_temp namespace, and shouldnot create one of their own.
通常,每个工作者在此时进行的清理操作类似于顶层的提交或中止。每个后台进程都有自己的资源所有者:缓冲区引用、catcache或relcache引用计数、元组描述符等由每个后台进程分别管理,并且在退出前必须释放它们。
然而,并行工作者的提交/中止和真正的顶层事务提交/中止之间存在一些重要的区别。最重要的是:
-
不会写入提交或中止记录;这由发起的后台进程负责。
-
不会清理pg_temp命名空间。并行工作者不能安全地访问发起后台进程的pg_temp命名空间,并且不应创建自己的pg_temp命名空间。
Coding Conventions
===================Before beginning any parallel operation, call EnterParallelMode(); after all
parallel operations are completed, call ExitParallelMode(). To actually
parallelize a particular operation, use a ParallelContext. The basic coding
pattern looks like this:EnterParallelMode(); /* prohibit unsafe state changes */pcxt = CreateParallelContext("library_name", "function_name", nworkers);/* Allow space for application-specific data here. */shm_toc_estimate_chunk(&pcxt->estimator, size);shm_toc_estimate_keys(&pcxt->estimator, keys);InitializeParallelDSM(pcxt); /* create DSM and copy state to it *//* Store the data for which we reserved space. */space = shm_toc_allocate(pcxt->toc, size);shm_toc_insert(pcxt->toc, key, space);LaunchParallelWorkers(pcxt);/* do parallel stuff */WaitForParallelWorkersToFinish(pcxt);/* read any final results from dynamic shared memory */DestroyParallelContext(pcxt);ExitParallelMode();If desired, after WaitForParallelWorkersToFinish() has been called, the
context can be reset so that workers can be launched anew using the same
parallel context. To do this, first call ReinitializeParallelDSM() to
reinitialize state managed by the parallel context machinery itself; then,
perform any other necessary resetting of state; after that, you can again
call LaunchParallelWorkers.