ThreeJS示例教程200+【目录】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/7527.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

opengrok_使用技巧
Searchhttps://xrefandroid.com/android-15.0.0_r1/https://xrefandroid.com/android-15.0.0_r1/
选择搜索的目录(工程) 手动在下拉框中选择,或者 使用下面三个快捷按钮进行选择或者取消选择。
输入搜索的条件
搜索域说明
域 fullSearc…

无人机如何自主侦察?UEAVAD:基于视觉的无人机主动目标探测与导航数据集
作者:Xinhua Jiang, Tianpeng Liu, Li Liu, Zhen Liu, and Yongxiang Liu 单位:国防科技大学电子科学学院 论文标题:UEVAVD: A Dataset for Developing UAV’s Eye View Active Object Detection 论文链接:https://arxiv.org/p…

【图文详解】lnmp架构搭建Discuz论坛
安装部署LNMP
系统及软件版本信息 软件名称版本nginx1.24.0mysql5.7.41php5.6.27安装nginx
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客: 关闭防火墙 systemctl stop firewalld &&a…

Ansible入门学习之基础元素介绍
一、Ansible目录结构介绍 1.通过rpm -ql ansible获取ansible所有文件存放的目录 有配置文件目录 /etc/ansible/ 执行文件目录 /usr/bin/ 其中 /etc/ansible/ 该文件目录的主要功能是 inventory主机信息配置,ansible工具功能配置。 ansible自身的配置文件…
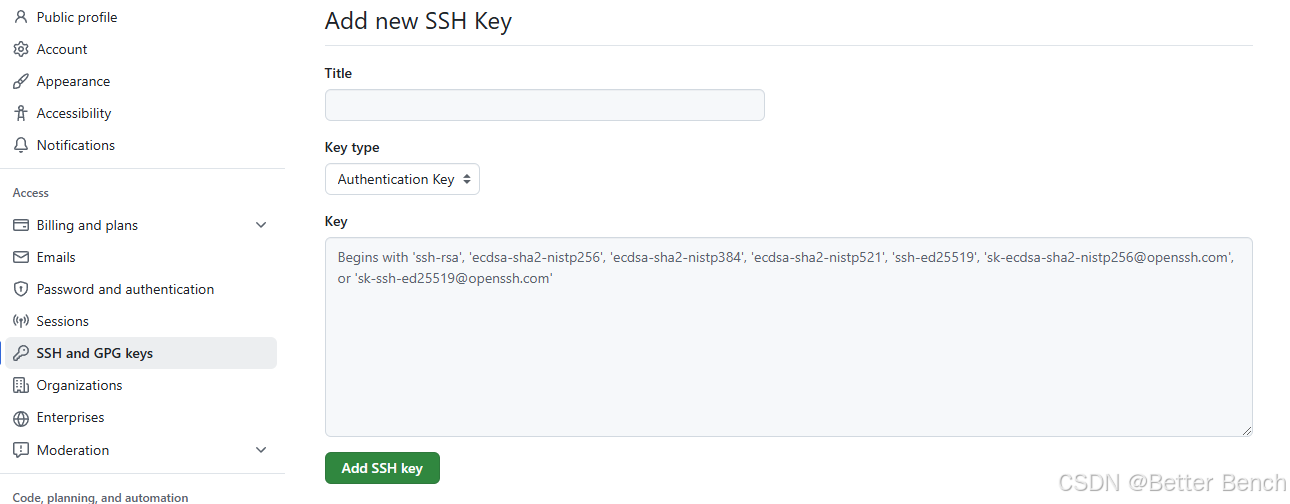
git Bash通过SSH key 登录github的详细步骤
1 问题
通过在windows 终端中的通过git登录github 不再是通过密码登录了,需要本地生成一个密钥,配置到gihub中才能使用
2 步骤
(1)首先配置用户名和邮箱 git config --global user.name "用户名"git config --global…

矩阵的秩在机器学习中具有广泛的应用
矩阵的秩在机器学习中具有广泛的应用,主要体现在以下几个方面:
一、数据降维与特征提取
主成分分析(PCA): PCA是一种常用的数据降维技术,它通过寻找数据中的主成分(即最大方差方向)…

Windows Defender添加排除项无权限的解决方法
目录 起因Windows Defender添加排除项无权限通过管理员终端添加排除项管理员身份运行打开PowerShell添加/移除排除项的命令 起因
博主在打软件补丁时,遇到 Windows Defender 一直拦截并删除文件,而在 Windows Defender 中无权限访问排除项。尝试通过管理…
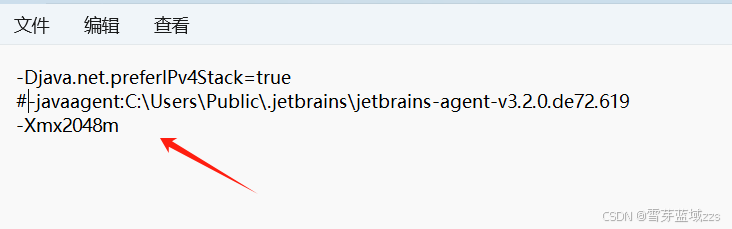
IDEA工具下载、配置和Tomcat配置
1. IDEA工具下载、配置
1.1. IDEA工具下载
1.1.1. 下载方式一 官方地址下载
1.1.2. 下载方式二 官方地址下载:https://www.jetbrains.com/idea/
1.1.3. 注册账户 官网地址:https://account.jetbrains.com/login
1.1.4. JetBrains官方账号注册…


微信小程序date picker的一些说明
微信小程序的picker是一个功能强大的组件,它可以是一个普通选择器,也可以是多项选择器,也可以是时间、日期、省市区选择器。
官方文档在这里
这里讲一下date picker的用法。
<view class"section"><view class"se…

Pyecharts图表交互功能提升
在数据可视化中,交互功能可以极大地提升用户体验,让用户能够更加深入地探索数据。Pyecharts 提供了多种强大的交互功能,本篇将重点介绍如何使用缩略轴组件、配置图例交互,让我们的数据可视化作品更加生动有趣。
一、缩略轴组件使…

奇怪的单词(快速扩张200个单词)
这是一些非常奇怪的单词:
screw n.螺丝;螺丝钉 screwdriver n.起子,螺丝刀,改锥 copulation n.连接 copulate a.配合的 bonk n.撞击;猛击 v.轻击;碰撞ebony n.黑檀couple n.夫妇blonde n.金发女郎intimacy…

Ubuntu20.04 深度学习环境配置(持续完善)
文章目录 常用的一些命令安装 Anaconda创建conda虚拟环境查看虚拟环境大小 安装显卡驱动安装CUDA安装cuDNN官方仓库安装 cuDNN安装 cuDNN 库验证 cuDNN 安装确认 CUDA 和 cuDNN 是否匹配: TensorRT下载 TensorRT安装 TensorRT 本地仓库配置 GPG 签名密钥安装 Tensor…
Android多语言开发自动化生成工具
在做 Android 开发的过程中,经常会遇到多语言开发的场景,尤其在车载项目中,多语言开发更为常见。对应多语言开发,通常都是在中文版本的基础上开发其他国家语言,这里我们会拿到中-外语言对照表,这里的工作难…

数据结构——堆(C语言)
基本概念:
1、完全二叉树:若二叉树的深度为h,则除第h层外,其他层的结点全部达到最大值,且第h层的所有结点都集中在左子树。
2、满二叉树:满二叉树是一种特殊的的完全二叉树,所有层的结点都是最…


机器学习-线性回归(参数估计之经验风险最小化)
给定一组包含 𝑁 个训练样本的训练集 我们希望能够 学习一个最优的线性回归的模型参数 𝒘
现在我们来介绍线性回归的一种模型参数估计方法:经验风险最小化。
我们前面说过,对于标签 𝑦 和模型输出都为连续的实数值&…

appium自动化环境搭建
一、appium介绍
appium介绍
appium是一个开源工具、支持跨平台、用于自动化ios、安卓手机和windows桌面平台上面的原生、移动web和混合应用,支持多种编程语言(python,java,Ruby,Javascript、PHP等)
原生应用和混合应用…

视频多模态模型——视频版ViT
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文《ViViT: A Video Vision Transformer》,2021由google 提出用于视频处理的视觉 Transformer 模型,在视频多模态领域有…

使用Cline+deepseek实现VsCode自动化编程
不知道大家有没有听说过cursor这个工具,类似于AIVsCode的结合体,只要绑定chatgpt、claude等大模型API,就可以实现对话式自助编程,简单闲聊几句便可开发一个软件应用。
但cursor受限于外网,国内用户玩不了,…
推荐文章
- #渗透测试#批量漏洞挖掘#致远互联AnalyticsCloud 分析云 任意文件读取
- (学习总结29)Linux 进程概念和进程状态
- [7] 游戏机项目说明
- [Computer Vision]实验四:相机标定
- [JVM篇]分代垃圾回收
- [python]基于yolov12实现热力图可视化支持图像视频和摄像头检测
- [程序设计]—代理模式
- [极客大挑战 2019]BabySQL—3.20BUUCTF练习day4(3)
- 《C++11 基于CAS无锁操作的atomic原子类型》
- 《STL 六大组件之容器探秘:深入剖析 vector》
- 《论语别裁》第01章 学而(28) 上帝的外婆是谁
- 《掌握基础DOM操作:从零开始的前端入门指南》