论文:https://arxiv.org/abs/2307.03942, Miccai 2023
代码:GitHub - Junelin2333/LanGuideMedSeg-MICCAI2023: Pytorch code of MICCAI 2023 Paper-Ariadne’s Thread : Using Text Prompts to Improve Segmentation of Infected Areas from Chest X-ray images
其实这篇完全就是VLiT的网络结构优化,改动也不是很大,我寻思这个比较新的方向比较好发文章喔。这里背景就不多介绍了,可以直接去参考我之前博文VLiT。感觉这个名字起的蛮好玩的,Ariadne’s Thread,是这个名字来自古希腊神话,讲述了忒修斯在阿里阿德涅的金线的帮助下走出迷宫的故事。后面的拓展学习也挺有意思的。
摘要
肺部感染区域的分割对于量化肺部感染等肺部疾病的严重程度至关重要。现有的医学图像分割方法几乎都是基于图像的单模方法。然而,除非使用大量带注释的数据进行训练,否则这些仅图像的方法往往会产生不准确的结果。为了克服这一挑战,我们提出了一种语言驱动的分割方法,该方法使用文本提示来改进切分结果。在QaTa-COV19数据集上的实验表明,与单模态方法相比,我们的方法至少提高了6.09%的Dice得分。此外,我们的扩展研究揭示了多模态方法在文本信息粒度方面的灵活性,并表明多模态方法在所需训练数据的大小方面比仅图像方法具有显着优势。
背景
直接参考LViT:语言与视觉Transformer在医学图像分割_Scabbards_的博客-CSDN博客,
本篇是LViT的一个后续工作,对模型结构进行优化
主要贡献
1) 我们提出了一种语言驱动的分割方法,用于从肺部x射线图像中分割感染区域。
2) 该方法设计的导视解码器能够自适应地将文本提示足够的语义信息传播到像素级视觉特征中,促进了两种模式的一致性。
3)清理了QaTa-COV19[17]文本注释中包含的错误,并联系LViT作者发布新版本。
4)扩展研究揭示了文本提示信息粒度对我们方法分割性能的影响,并证明了多模态方法在所需训练数据大小方面优于仅图像方法的显著优势。
模型结构
我们提出的方法采用模块化设计,其中模型主要由一个图像编码器、一个文本编码器和几个guidedecoder组成。GuideDecoder用于自适应地将语义信息从文本特征传播到视觉特征,并输出解码后的视觉特征

与LViT的早期融合相比,我们提出的模块化设计方法更加灵活。例如,当我们的方法用于脑MRI图像时,由于模块化的设计,我们可以首先加载在相应数据上训练的预训练权值来分离视觉和文本编码器,然后只需要训练GuideDecoders。
Image Encoder
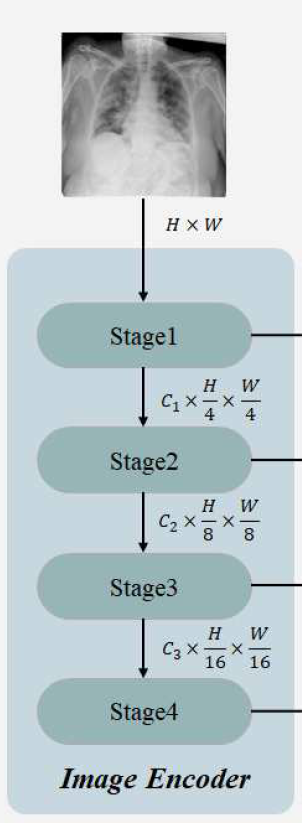
ConvNeXt-Tiny
输入![]()
四个stage分别是
C为特征维度,H和W为原始图像的高度和宽度
Text Encoder

CXR-BERT
输入![]()
获得文本特征![]()
C是特征维度,L是文本提示符的长度。
GuideDecoder
输入:![]() ,
,![]()
输出:![]()

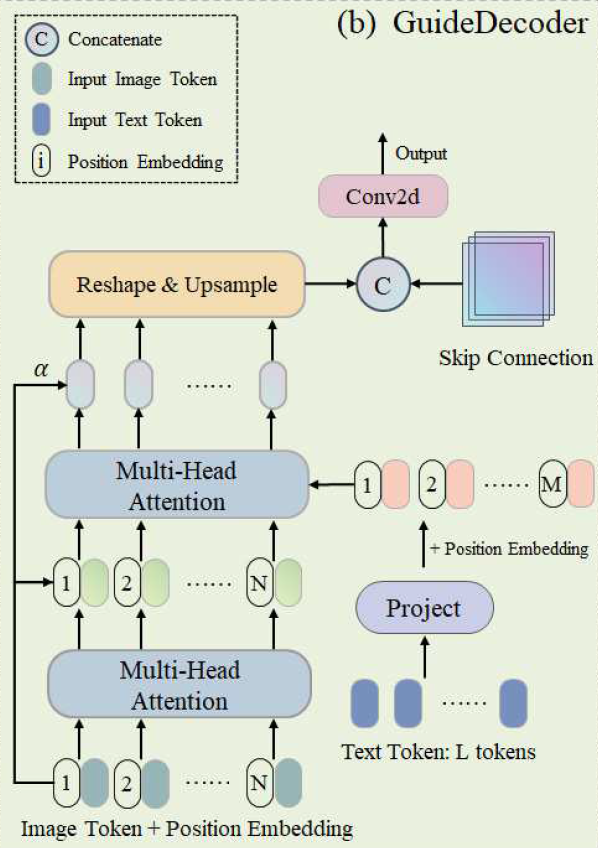
在执行多模态交互之前,GuideDecoder首先处理输入的文本特征和视觉特征。
step1
Text
输入:![]()
输出:![]()
输入文本特征首先通过投影模块(即图中的Project),该模块将文本标记的维度与图像标记的维度对齐,并减少文本标记的数量。
![]()
WT是一个可学习的矩阵
Conv(·)是 1 X 1 卷积
(·)是 ReLU激活函数
step2
Image
输入:
![]()
输出:
![]() ,以及残差链接产物
,以及残差链接产物
在加入位置编码后,利用自注意增强图像中的视觉信息去获得视觉特征
![]()
MHSA(·) 是 Multi-Head Self-Attention层
LN(·) 是 Layer Normalization
Step3
输入:![]() ,
,![]()
输出:多模态特征![]()
采用多头交叉注意层,将细粒度(fine-grained)的语义信息传播到进化的图像特征中

MHCA(·)是multi-head cross-attention
α是可学习的参数,控制剩余连接的权值
step4
输入:![]()
输出:![]()
重塑和上采样
![]()
Step5
输入:![]() ,
,![]()
![]() ,其中fs是通过跳过连接从视觉编码器获得的低级视觉特征
,其中fs是通过跳过连接从视觉编码器获得的低级视觉特征
输出:![]()
通过卷积层和ReLU激活函数进行处理
![]()
其中[·,·]表示通道维度上的连接操作。
实验
数据集
QaTa-COV19
我们发现在扩展文本注释中存在一些明显的错误(如拼错单词、语法错误、所指不清)。我们已经修复了这些已识别的错误,并联系了LViT的作者,发布了数据集的新版本。
它由9258张带有感染肺区域像素级手动注释的COVID-19胸片组成,其中7145张在训练集,2113张在测试集。
实验设置
数据处理
80% and 20%.因此,训练集共有5716个样本,验证集有1429个样本,测试集有2113个样本。所有图像裁剪为224 × 224,数据使用10%概率的随机缩放进行增强。
硬件
我们使用PyTorch Lightning作为最终的训练和推理包装器。所有的方法都在一个NVIDIA Tesla V100 SXM3 32GB VRAM GPU上进行训练。
训练细节
我们使用Dice loss + Cross-entropy loss作为损失函数,并使用批大小为32的AdamW优化来训练网络。我们利用余弦退火学习率策略,初始学习率设为3e-4,最小学习率设为1e-6。
评价指标
Accuracy、Dice Loss 和Jaccard系数。Dice系数和Jaccard系数都计算给定的预测掩模和地面真值的联合区域上的相交区域,其中Dice系数更能反映小目标的分割性能。
Dice系数和Jaccard系数都计算给定的预测Mask和Ground Truth的联合区域上的相交区域,其中Dice系数更能反映小目标的分割性能。
(所以个人感觉Jaccard这个不是很必要)
实验结果

定性实验结果如图2所示。仅图像的单模态方法容易产生一些过度分割
多模态方法是指通过文本提示对感染区域的具体位置进行分割,使分割结果更加准确。

消融实验

由表2可以看出,随着模型中使用的guidedecoder数量的增加,模型的分割性能也随之提高。这些结果可以证明导解码器的有效性。
拓展学习
不同粒度的文本提示对分割性能的影响
将每个样本扩展为包含不同粒度位置信息的三个部分的文本注释,如图所示

图表展示了不同粒度的文本以及分割表现
表中的结果表明,我们的方法由文本提示符中包含的位置信息的粒度驱动。
我们提出的方法在给出包含更详细位置信息的文本提示符时获得了更好的分割性能。
同时,我们观察到,当使用两种类型的文本提示时,即Stage3单独和Stage1 + Stage2 + Stage3性能几乎相同。这意味着文本提示中最详细的位置信息对提高分割性能起着最重要的作用。但这并不意味着文本提示符中其他粒度的位置信息对分割性能的改善没有贡献。即使输入文本提示只包含最粗略的位置信息(Stage1 +)在表3中的Stage2项中,我们提出的方法比没有文本提示的方法获得的Dice分数高1.43%
训练数据大小对分割性能的影响
我们提出的方法即使在减少训练数据量的情况下也显示出高度的竞争性能。
仅使用四分之一的训练数据,我们提出的方法比UNet++的Dice得分高2.69%,UNet++是在完整数据集上训练的表现最好的单模态模型。这为多模态方法的优越性提供了充分的证据,合适的文本提示可以显著提高分割性能。

我们观察到,当训练数据减少到10%时,我们的方法才开始表现出比UNet++更差的性能,UNet++是用所有可用数据训练的。类似的实验也可以在LViT论文中找到。因此,可以认为,多模态方法只需要少量的数据(在我们的方法中少于15%)就可以达到与单模态方法相当的性能。