堆内存与栈内存一般分别 有多少
ChatGPT
堆内存和栈内存的大小取决于操作系统和编译器的限制以及程序的运行环境。以下是一些常见的默认大小范围,但请注意这些值可以因环境而异:
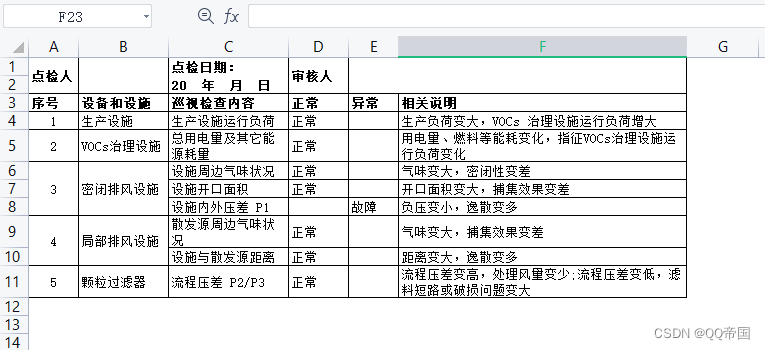
栈内存大小:
Windows平台:默认情况下,栈大小为1MB。可以使用编译器选项或操作系统设置更改栈的大小。
Linux平台:默认情况下,栈大小为8MB。可以使用ulimit命令或操作系统设置更改栈的大小。
堆内存大小:
操作系统限制:操作系统可以限制进程的总体虚拟内存大小。例如,在32位操作系统中,进程通常受到2GB或3GB的虚拟地址空间限制。在64位操作系统中,进程的虚拟内存限制更高。
编译器和运行时限制:编译器和运行时库可以设置堆内存的默认大小限制。这些限制可以通过调整编译器选项或使用特定的库函数进行修改。
需要注意的是,堆内存的实际可用大小还受到其他因素的影响,例如已经分配的内存量、内存碎片化等。在申请大量内存时,还要考虑操作系统和硬件的可用物理内存大小。
在实际编程中,如果需要分配大量的内存,建议进行合理的内存管理,使用动态内存分配,避免不必要的内存消耗,并确保及时释放不再使用的内存,以优化内存使用。
为什么栈内存这么少,难道内存有64G也不能给它多分配一点
ChatGPT
栈内存相对较小的原因是出于性能和安全考虑。
性能:栈内存是通过硬件栈指针进行快速分配和释放的。栈上的数据结构是按照后进先出(LIFO)的顺序分配和释放的。栈的操作非常高效,因为分配和释放内存只涉及移动栈指针的操作,不需要进行复杂的内存管理。较小的栈内存大小有助于提高栈操作的性能。
安全:栈内存的大小在编译时确定,并由编译器和操作系统进行管理。较小的栈内存大小可以帮助防止栈溢出和内存泄漏等问题。如果栈内存过大,递归函数或大量局部变量的使用可能导致栈溢出,使程序崩溃。
虽然栈内存相对较小,但堆内存可以提供更大的内存空间。堆内存的分配和释放相对较慢,需要更复杂的内存管理。堆内存的大小通常受操作系统和硬件的限制,可以根据需要动态调整。
如果您需要分配大量内存,堆内存是更适合的选择。可以使用动态内存分配(如new和delete操作符)或使用类似malloc()和free()的函数来在堆上分配和释放内存。请注意,使用堆内存时需要手动管理内存的分配和释放,以避免内存泄漏和内存碎片化等问题。
如果我只写一个代码,只调用一个简单的函数,其它有很多从来不用的函数,这样会不会使应用内存变大
ChatGPT
如果您的应用程序中包含很多从不使用的函数,并且这些函数在编译后没有被链接到最终的可执行文件中,那么这些未使用的函数不会增加应用程序的内存占用。
编译器在编译时会进行优化,通过静态分析和链接器的工作,仅将被实际使用的函数编译和链接到最终的可执行文件中。未使用的函数和代码段将被优化掉,不会包含在最终的可执行文件中。
因此,单独编写一个只调用一个简单函数的代码并不会导致应用程序的内存变大,只有实际被使用的代码和函数会占用内存。
然而,如果这些未使用的函数被链接到最终的可执行文件中,即使没有显式调用它们,它们可能会增加应用程序的内存占用。因此,在开发应用程序时,建议进行代码审查和优化,确保只包含实际需要的代码,以避免不必要的内存占用。
函数代码会不会占用内存,它们位于内存的什么位置
ChatGPT
函数的代码会被编译为可执行文件中的机器指令,这些指令将在程序运行时被加载到内存中执行。
在典型的执行模型中,函数的代码位于可执行文件的代码段(text segment)或只读数据段(read-only data segment)。这些段通常位于程序的虚拟内存空间中的特定区域。
代码段通常是可执行文件中的一个只读段,它包含程序的指令和函数的机器码。这些指令被加载到内存中,并在程序执行时按需执行。代码段通常具有执行权限,但不允许对其进行写入操作。
在程序加载到内存中时,操作系统将为代码段分配适当的内存空间,并将代码段的内容从可执行文件中复制到该内存空间。当程序执行时,处理器会按照代码的指令顺序执行代码段中的机器指令。
需要注意的是,函数的代码本身不会占用多个副本的内存空间。相同的函数可以被多次调用,但只有一份代码副本在内存中,多个函数调用共享同一段代码。
除了代码段之外,还有其他的内存段用于存储程序的全局变量、静态变量、堆和栈等数据。每个段在内存中都有自己的位置和权限,操作系统和编译器负责管理和分配这些内存段,以确保程序能够正常运行并按照预期使用内存。
C++如何进行代码混淆?
ChatGPT
代码混淆是一种技术,通过修改源代码的结构和逻辑,使其难以理解和逆向工程。以下是一些常见的C++代码混淆技术:
重命名标识符:将函数、变量、类等标识符进行随机化或使用无意义的名称。这使得代码阅读和理解变得困难,增加逆向工程的难度。
代码结构变换:通过改变函数和类的结构、重排代码块的顺序等方式,改变代码的结构。这会使逆向工程师难以追踪代码的执行流程。
添加无用代码:向代码中插入无实际作用的代码片段,如无用的循环、条件语句或函数调用。这会增加代码的复杂性,使逆向工程师难以分析和理解代码的逻辑。
字符串加密和解密:将字符串常量进行加密,并在运行时进行解密。这样可以防止字符串常量在代码中直接暴露,增加逆向工程的难度。
控制流扁平化:通过转换控制流语句(如if-else语句、循环)为等价的跳转语句,使得代码的控制流变得扁平化和难以理解。
常量混淆:将常量值进行变换或加密,使得常量的含义变得模糊,难以理解。
虚假依赖:添加虚假的依赖关系,使逆向工程师产生困惑和误导。
宏和模板滥用:通过大量使用宏和模板,增加代码的复杂性和可读性,使逆向工程变得更困难。
请注意,代码混淆技术并不能完全阻止破解和逆向工程,但可以增加破解的难度。选择适当的代码混淆技术取决于特定的需求和情况,并且需要仔细权衡代码的可读性和性能方面的影响。有一些开源的代码混淆工具可以辅助进行代码混淆,例如:Eazfuscator.NET、ConfuserEx、Veil等。
C++编译后的exe,难不难破解
ChatGPT
编译后的C++可执行文件(exe)可以被破解,但可以采取一些措施来增加破解的难度。以下是一些相关考虑:
反汇编和逆向工程:通过使用反汇编工具,黑客可以将可执行文件还原为汇编代码,甚至尝试还原源代码。逆向工程技术也可以用于分析程序的逻辑和算法。因此,无论编译后的可执行文件多么复杂,都无法完全阻止有意的逆向工程。
代码混淆:通过应用代码混淆技术,可以改变源代码的结构和逻辑,使得反汇编结果更加困难理解。代码混淆可以增加破解的难度,但并不能完全防止破解。
加密关键数据:对于敏感的数据,可以使用加密算法进行保护。这样即使黑客能够破解可执行文件,也难以获取到有效的解密数据。
安全授权机制:使用授权机制,例如许可证验证或硬件绑定等,可以确保只有授权用户才能运行软件。这可以防止非授权用户使用或修改软件。
运行时保护:使用运行时保护技术,例如反调试、代码完整性检查和内存保护等,可以增加破解的难度。这些技术可以防止黑客在运行时对程序进行分析和修改。
尽管可以采取这些措施来增加破解的难度,但完全阻止破解是非常困难的。技术上的挑战和黑客的不断进步意味着总会有人尝试破解软件。因此,在保护软件安全性方面,综合考虑安全措施、加密、许可证管理和法律保护等措施是至关重要的。
软件发布时,使用lib库,会不会导致软件代码泄露
ChatGPT
使用lib库本身不会导致软件代码泄露。lib库是已经编译好的二进制文件,其中包含了函数和符号的实现,但不包含源代码。因此,使用lib库只提供了编译后的代码,而不会泄露源代码。
然而,需要注意的是,即使使用了lib库,如果你将软件发布给他人,他们仍然可以通过反汇编、逆向工程等技术来尝试还原部分或全部的源代码。这并不是lib库的特定问题,而是适用于所有的可执行文件。因此,如果你担心源代码的保密性,即使使用lib库,仍然需要采取额外的保护措施,例如使用代码混淆技术或者对关键部分进行加密处理。
此外,当你使用第三方的lib库时,你需要遵守该库的许可协议和使用规定。某些开源库可能要求你在发布软件时公开你的代码,因此在使用任何库之前,请确保你了解和遵守相关的法律和许可要求。