从心所欲
不逾矩
天大地大
皆可去
一、官方模型的初使用
使用VGG16模型
VGG模型使用代码示例:
import torchvision.models
from torch import nndataset = torchvision.datasets.CIFAR10('/cifar10', False, transform=torchvision.transforms.ToTensor())vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_false)# 改造VGG,增加一层
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)# 改造vgg,修改一层
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
说明:
-
pretrained=True:当设置为True时,模型将加载在大规模图像数据集(如ImageNet)上预训练的权重。这些预训练的权重经过了在大量图像上的训练,可以捕捉到通用的图像特征。通过加载预训练权重,可以将VGG模型初始化为在ImageNet上训练得到的状态,并且这些权重可以作为初始参数用于特定任务的微调或迁移学习。 -
pretrained=False:当设置为False时,模型将使用随机初始化的权重。这意味着模型的权重没有经过预训练,需要从头开始进行训练。在这种情况下,模型将不会具备捕捉通用图像特征的能力,而是需要根据特定任务的数据进行训练。
pretrained=True和pretrained=False的区别在于是否加载预训练的权重。如果你想要在特定任务上使用VGG模型,并且你的任务与图像分类或特征提取相关,那么通常建议使用pretrained=True,以便利用预训练权重的优势。如果你的任务与图像分类或特征提取无关,或者你希望从头开始训练模型以适应特定数据集,那么可以选择pretrained=False。
二、模型的保存与加载
模型的保存:
两种保存模式,官方推荐第二种,只保存参数,不保存模型
import torch
import torchvision.modelsvgg16 = torchvision.models.vgg16(pretrained=False)# 保存方式1: 既保存模型结构,也保存参数
torch.save(vgg16, 'vgg16_model1.pth')# 保存方式2:把参数保存成字典,不保存结构(官方推荐)
torch.save(vgg16.state_dict(), 'vgg16_model2.pth')print("end")模型的加载:
import torch
import torchvision.models# 加载方式1 - 保存方式1
model = torch.load('vgg16_model1.pth')# 加载方式2 - 保存方式2
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load('vgg16_model2.pth'))三、完整的模型训练套路
以CIFAR10数据集来一个完整的模型训练。
代码示例:
model.py
from torch import nn# 搭建神经网络
class Lh(nn.Module):def __init__(self):super(Lh, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x
train.py
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom model import Lh# 准备数据集
train_data = torchvision.datasets.CIFAR10('./cifar10', train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10('./cifar10', train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 搭建神经网络 - 10分类
lh = Lh()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(lh.parameters(), lr=learning_rate)# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练轮数
epoch = 10# 添加tensorboard
writer = SummaryWriter("train_logs")for i in range(epoch):print("-----第{}轮训练开始了-----".format(i + 1))# 训练步骤开始for data in train_dataloader:imgs, tragets = dataoutput = lh(imgs)loss = loss_fn(output, tragets)optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, tragets = dataoutput = lh(imgs)loss = loss_fn(output, tragets)total_test_loss += lossaccuracy = (output.argmax(1) - - tragets).sum()total_accuracy += accuracyprint("整体测试机上误差:{}".format(total_test_loss))print("整体测试机上的正确率:{}".format(total_accuracy / test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy / total_test_step)total_test_step += 1# torch.save(lh, "lhy_{}.pth".format(i))# print("模型已保存")writer.close()
输出结果:
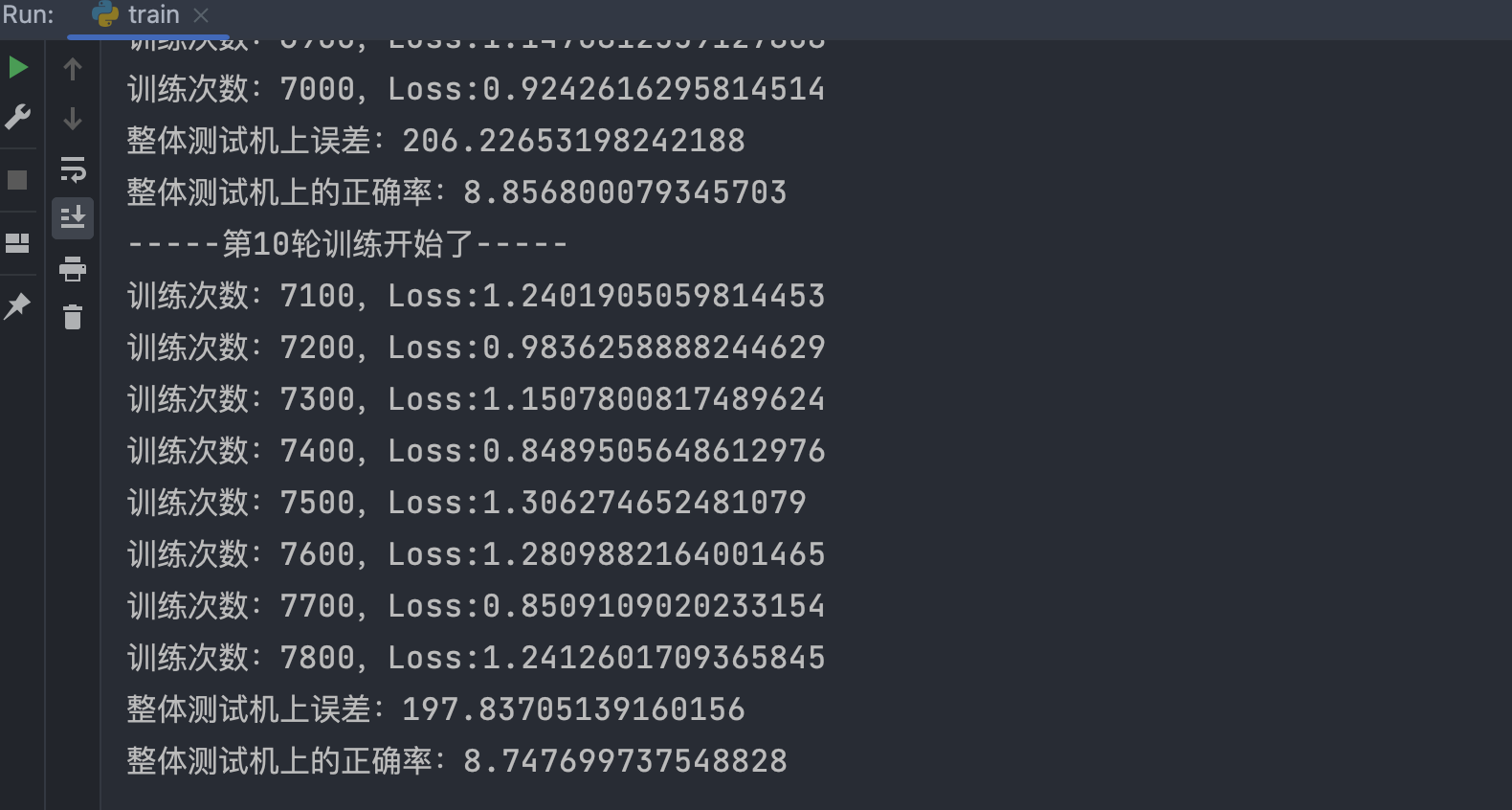
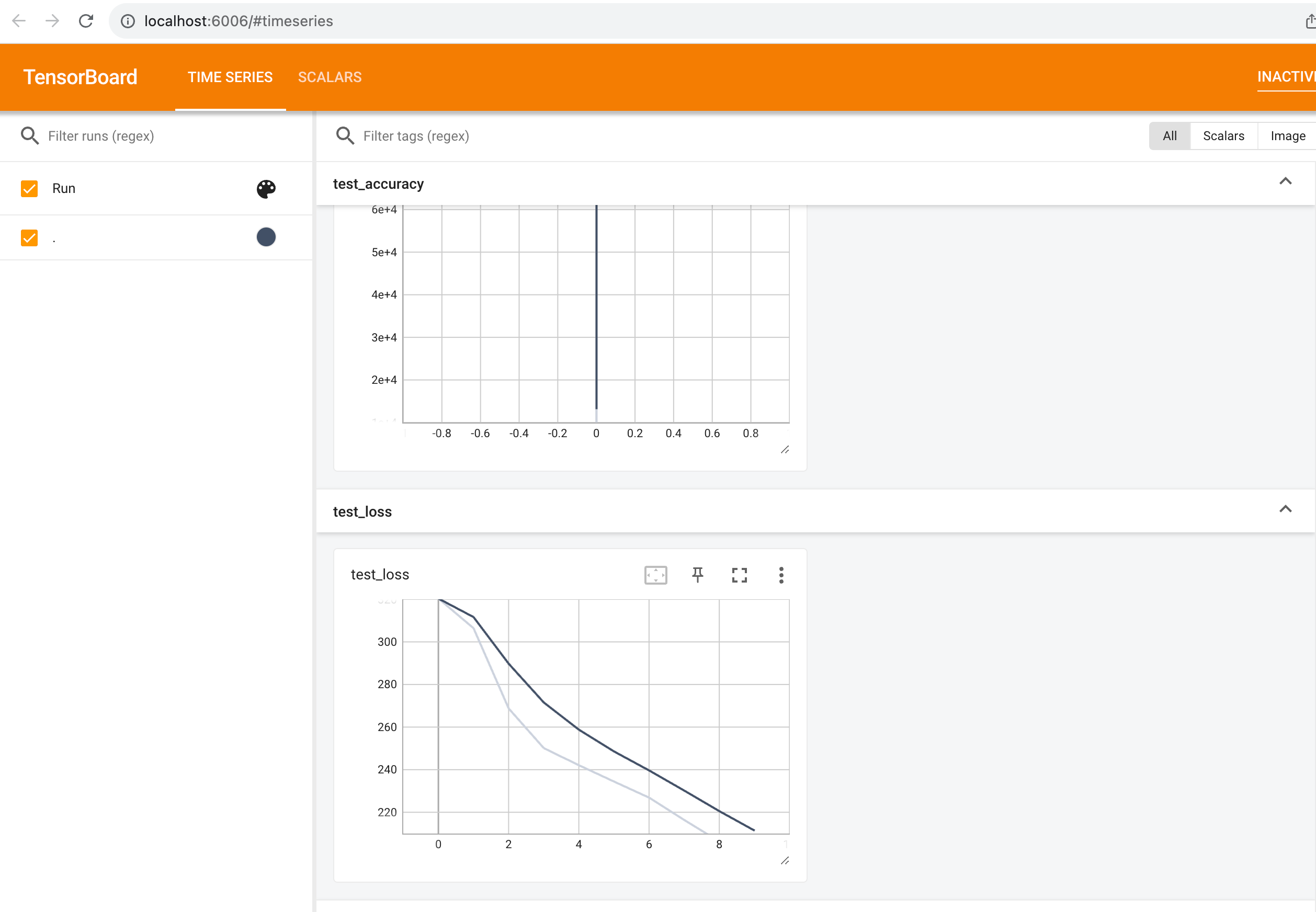
在tensorboard打开
]](https://img-blog.csdnimg.cn/71e802c244ee4701956e8be45e6056e8.png)