即将过去的 2024 年,是 JuiceFS 开源版本推出的第 4 年,企业版的第 8 个年头。回顾过去这一年,JuiceFS 社区版依旧保持着快速成长的势头,GitHub 星标突破 11.1K,各项使用指标增长均超过 100%,其中文件系统总数量较前一年更是增长了 8.5 倍;企业版同样持续保持高速增长,继去年实现盈亏平衡后,商业营收实现了翻倍增长,为未来的社区持续投入和产品优化提供了坚实的保障。
2024年,随着 AI 技术的迅猛发展,AI 正逐渐成为企业发展的新基建,企业的基础架构正朝着 AI 原生化趋势迈进。在这一变革的推动下,JuiceFS 社区也迎来了显著的增长。
今年,AI 场景的用户占比大幅增加,且渗透到教育、制造、风电、生物医药等多个行业。在新兴 AI 行业里,除了基础模型研究的企业,如 MiniMax、智谱、阶跃星辰等,大量中小型 AI 服务软件公司也加入了社区,成为重要的用户群体。
接下来,让我们一起回顾 JuiceFS 的这一年。
01 产品迭代:企业级管理 、多云架构、大规模 AI 场景
JuiceFS 社区版
过去一年,JuiceFS 社区版发布了 9 个版本。持续保持每年一个大版本的发布节奏,v1.2 版本是自 2021 年开源以来的第三个重大版本,此版本大幅提升了 JuiceFS 在企业级权限管理方面的能力,继续提升处理大规模数据的易用性,关键功能包括支持 POSIX ACL 、平滑升级、S3 Gateway 和 JuiceFS Sync 的诸多优化。
JuiceFS CSI Driver
JuiceFS CSI 在过去一年发布了 16 个版本,专注于为 Kubernetes 环境中的用户提供更稳定、易用的操作,主要更新包括平滑升级、统一配置、kubectl 插件和缓存组 Operator。
JuiceFS 企业版
JuiceFS 企业版专为海量文件高性能计算场景设计。过去一年中,针对大规模 AI 场景的需求,企业版在多云架构、AI 生态兼容性、海量文件的性能稳定性等方面进行了深入优化。v5.1 版本新增了可写镜像集群、支持 Python SDK 、分布式缓存副本和 S3 网关账号管理等功能。在下一个版本中,我们还在挑战更多的极限场景,继续推进分布式缓存性能优化、热点分区自动均衡、高性能 FUSE 改进等。
02 AI 助推社区发展:增长与活跃并进
社区版开源的第 4 年,社区用户还在持续壮大。根据用户反馈数据显示,JuiceFS 的各项关键数据上持续呈现出快速增长趋势,2024 年的增长尤为突出:
- JuiceFS 文件系统数量达超 3 万个,增长 8.5 倍
- 活跃客户端数量超 10.7 万个,增长超 2 倍
- 文件数量增至 3,000 亿个,增长 3.3 倍
- 管理的数据量达到 700 PiB,增长 4.2 倍

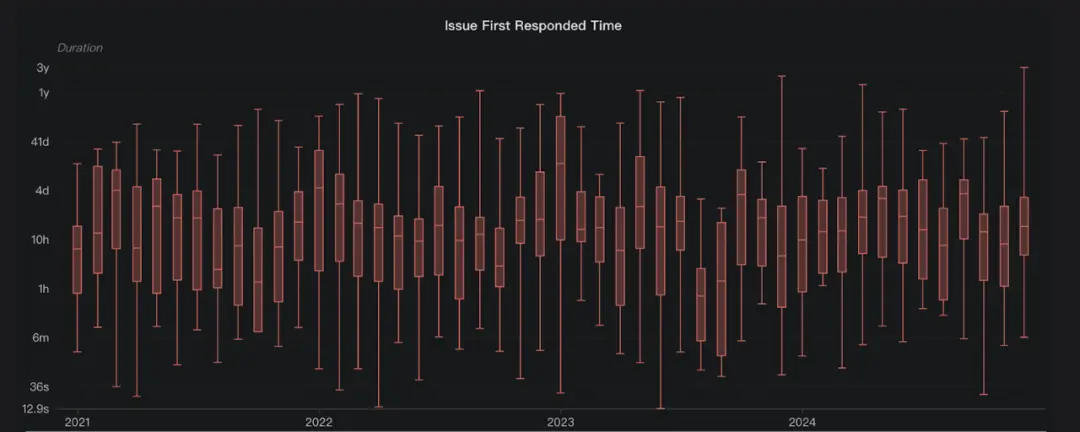
从数据使用规模来看,2024年的增长速度显著加快。加速增长的同时,社区依旧保持高度活跃。 2024 年一共处理了 265个 issue,Issue 的首次回复时间中位值为 22 小时,意味着用户在提出 Issue 后,通常在 1 天内就能得到回复。
全年,我们在多个行业大会分享我们的实践,KubeCon 中国、KCD 上海、QCon、稀土大会等。此外,还举办了 11 场 Office Hours,向用户介绍新功能、解答疑问;举行了 11 场 meetup,展示了 JuiceFS 在各行业和场景中的应用,帮助新用户更有信心地将 JuiceFS 应用于生产环境中,值得一提的是今年的案例多来自于 AI 领域。
分享案例
- 管锡鹏,BentoML:如何使用 JuiceFS 加速大模型加载?
- 鲁蔚征,中国人民大学:从 HPC 到 AI,探索文件系统的发展及性能评估
- 王新,知乎:多云架构下大模型训练,如何保障存储稳定性?
- 马涛,Jerry:稳定、省钱的 ClickHouse 读写分离方案,基于 JuiceFS 的主从架构实践
- 王天庆,贝壳找房: 为 AI 平台打造混合多云的存储加速底座
- 徐国昊,中山大学:基于 JuiceFS 构建高校 AI 存储方案:高并发、系统稳定、运维简单
- Jon Jiang,MemVerge:小文件写入性能 5 倍于 S3FS,JuiceFS 加速生信研究
- Jonnas,Clobotics :计算机视觉场景多云架构、 POSIX 全兼容、低运维的统一存储
- 星龙,MiniMax:混合云环境中大模型训练,基础系统的挑战与实践
- 吴森栋,海柔创新:仿真系统存储实践:混合云架构下实现高可用与极简运维
- 郑亚军,摩尔线程:从 NFS 到 JuiceFS, 低成本提升 AI 训练性能
- 于相洋,vivo: AI 计算平台存储性能优化实践
- 贺龙华,好未来:多云环境下基于 JuiceFS 建设低运维模型仓库
- 位传海,同程旅行:从 CephFS 到 JuiceFS,构建企业级统一存储平台
- 丁聪,Lepton AI:基于 JuiceFS 构建多租户高性能存储平台
除了上述案例提到的场景,JuiceFS 在 AI 领域的应用已非常广泛,用户涵盖多个子领域:
- 生成式 AI:MiniMax、智谱、阶跃星辰、面壁智能等;
- 平台应用类:小红书、WPS、知乎、韩国国民搜索平台 NAVER、LiblibAI 等;
- AI 基础架构:如 Lepton AI、BentoML、硅基流动、Cerebrium 等;
- 自动驾驶:Momenta、地平线、大疆卓驭等。
在应用 AI 技术的其他行业,如金融量化基金、消费电子、生物医药等,JuiceFS 也拥有众多用户。我们深感荣幸能获得这些科技创新者的信任。
海外用户也在持续增长,GitHub 上的星标、官网访问数据均显示,今年有超过 50% 的用户来自海外。此外,JuiceFS Slack 英文频道成员数量较去年增长了 70%,今年将 JuiceFS 应用在生产环境中的用户也逐渐增多,同样大量集中在 AI 领域,如 fal.ai、LeptonAI、BentoML、Cerebrium、Baseten 、 RunComfy 等。JuiceFS 的多篇技术文章被 DZone 等海外媒体收录,并多次登上 Hacker News 首页,同时我们也首次在 The IT Press Tour 和 DataTalksClub 等海外媒体上崭露头角。
在此,我们衷心感谢大家在过去一年里一路相伴与支持,你们每一位的参与与反馈,帮助 JuiceFS 持续进步;特别感谢在各类活动和博文中分享 JuiceFS 使用心得的用户们,让 JuiceFS 被更多人看见。希望新的一年,JuiceFS 能继续让你的工作更轻松、高效。