目录
1.什么是LIME
2.思路
3.LIME在不同任务中的范式(待补充)
1.什么是LIME
简单理解:
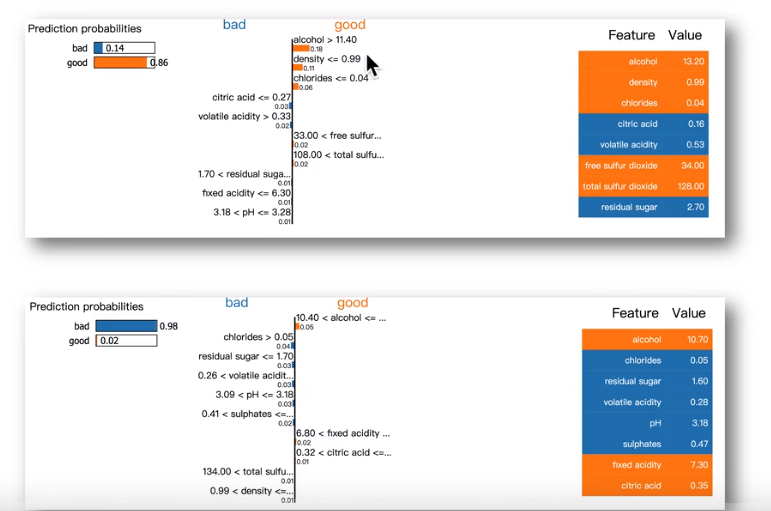
对于分类任务:如下图所示,LIME可以列出分类结果,所依据特征对应给比重。
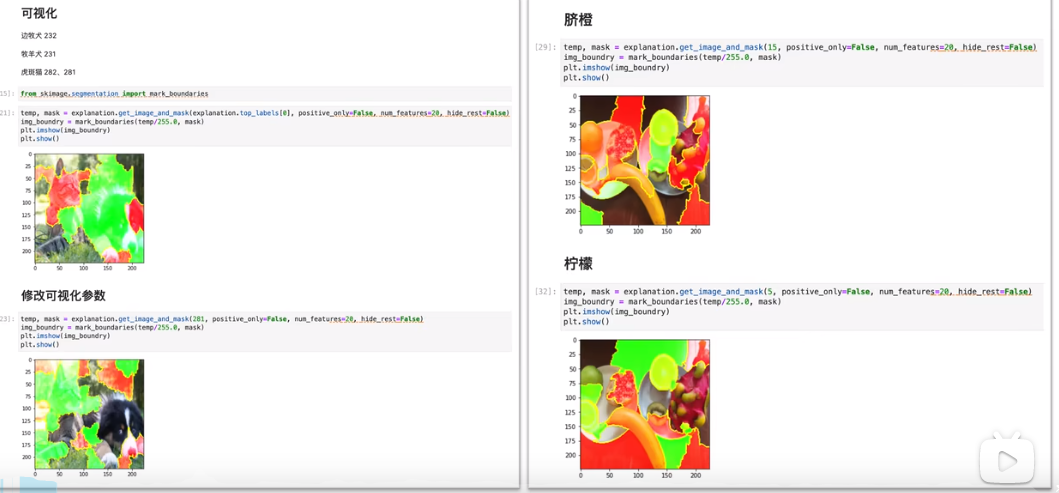
对于图像分类任务:如下图所示,可以标记出,分类结果对应的特征。并且可以表示出那些特征具有正向贡献,那些特征具有负向贡献。
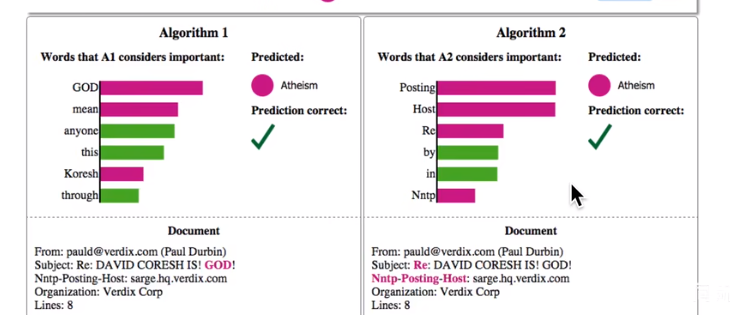
对文本数据:如下图预测一封邮件是无神论还是有神论内容,可以给出预测结果对应的单词的比重。

2.思路
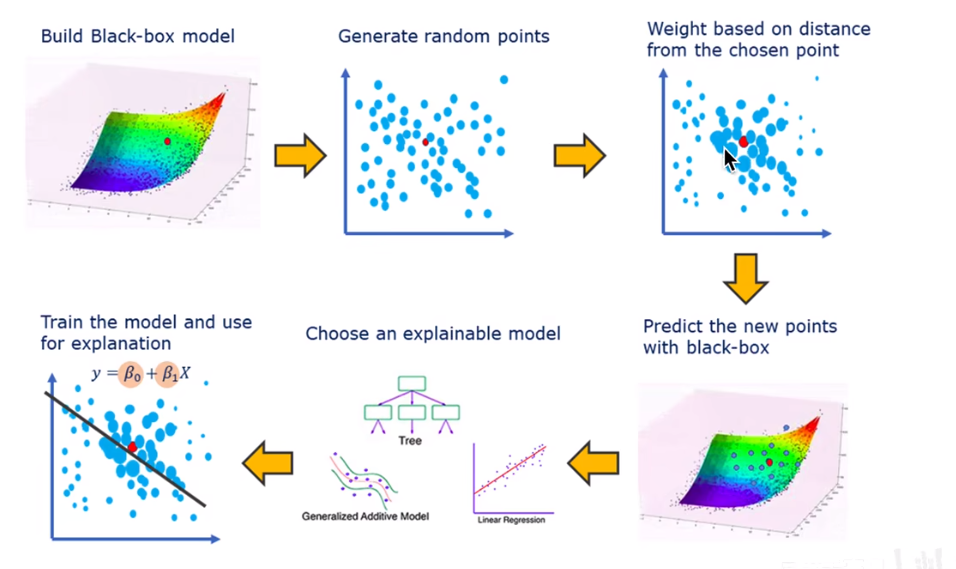
如下图所示:对于一个高维黑箱模型决策边界非常复杂,所以我们找到一个样本并从其邻域再选择一些样本,构成一个局部的小样本集 ,再将其输入到原模型得到预测结果,在根据其预测结果作为标签和模型得到的特征,用可解释性强的方法像,线性回归,树模型等训练出一个新的模型。这个新的模型就可以近似在局部邻域拟合出原模型的行为,该模型的权重就可以反应每个特征的贡献程度。
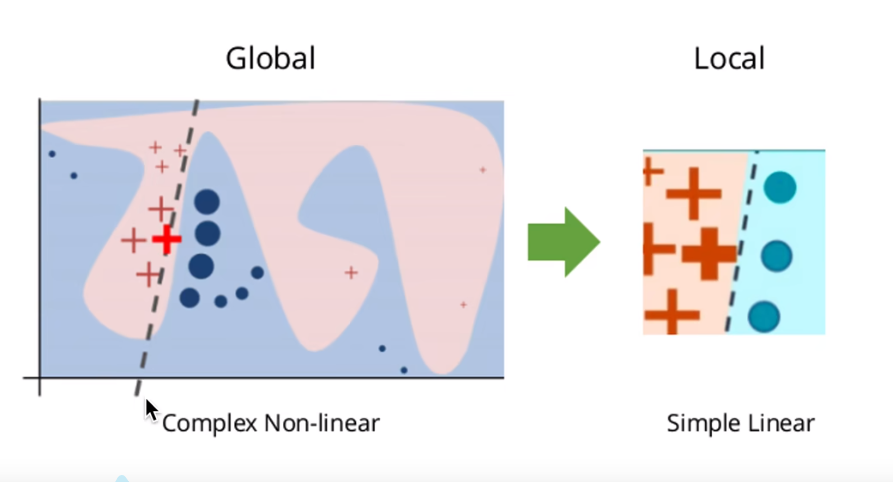
直观看:Global中两种颜色的交接为决策边界,LIME就是想找到Local局部决策边界,来表示全局的决策行为。也可以简单理解为,在全局是一个非线性曲线,但局部可以用一个线性曲线表示,LIME是一种通用范式,不是一种算法。
延深:也可以用可解性分析去评判一个模型好坏,尽管我们有一些模型评估方法,但这些方法都是从结果的好坏来评判一个模型,在实际应用中,我么会发现一个问题,可能一个模型能得到一个好的结果,但这个结果依据的特征却是不对的,比方说,我们要评价一份邮件是有神论还是无神论内容,下面两个算法都有好的结果,但第二个算法的依据中by和in这些常用介词显然不能作为结果的有效依据。