Transformer是一种基于注意力机制的深度神经网络结构,常用于文本生成、机器翻译等NLP任务。目前常用的Transformer类模型架构主要有三种:
| 结构 | 例子 | – |
|---|---|---|
| 仅编码器(EncoderOnly) | bert,T5 | 输入为一整个句子 |
| 仅解码器(DecoderOnly) | GPT | 输入为掩码后的句子,不断循环得到结果 |
| Encoder-Decoder | Transformer | 编码器负责将输入序列转换为隐藏状态,解码器则将该隐藏状态作为输入,生成输出序列。 |
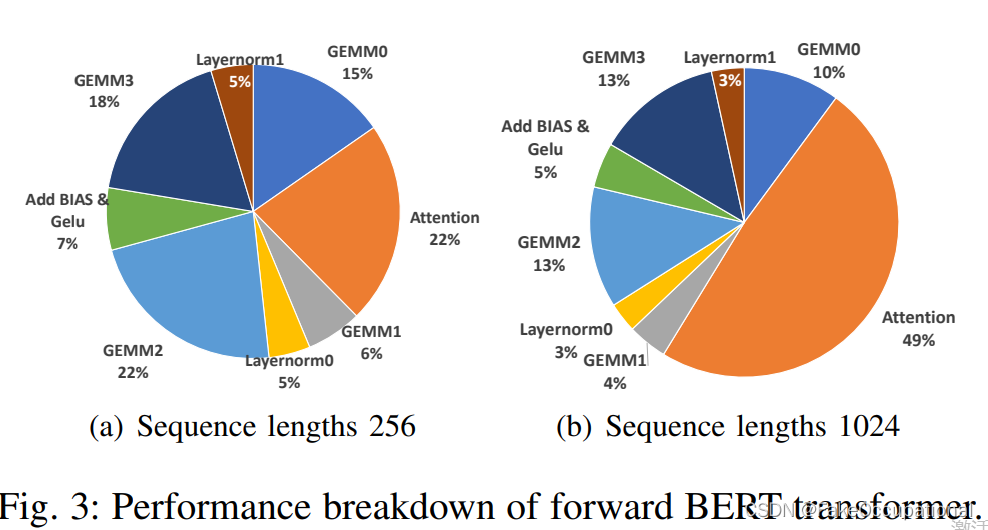
- ByteTransformer:针对可变⻓度输⼊进⾏增强的⾼性能变压器 https://arxiv.org/pdf/2210.03052.pdf
- https://github.com/bytedance/ByteTransformer

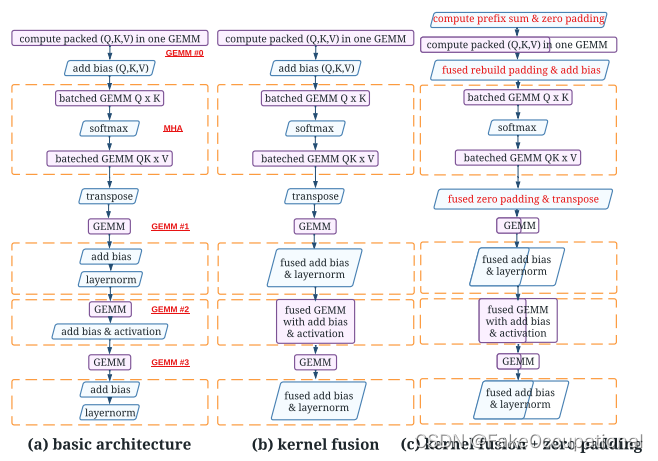
Kernel fuse
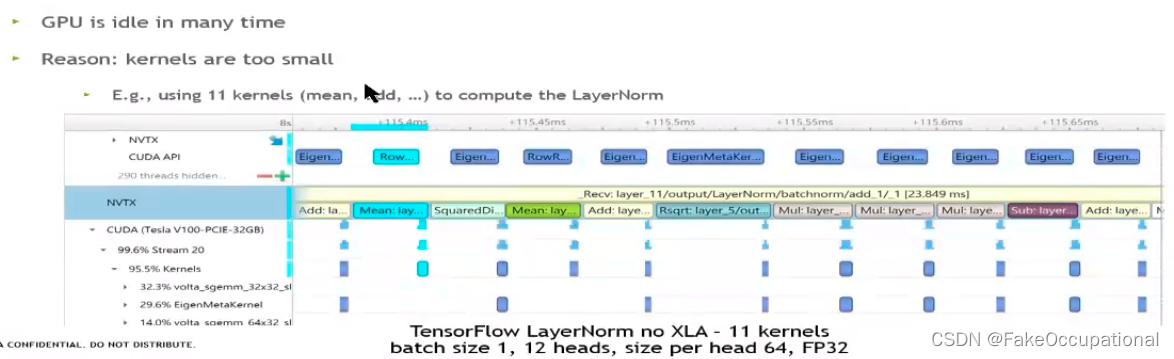
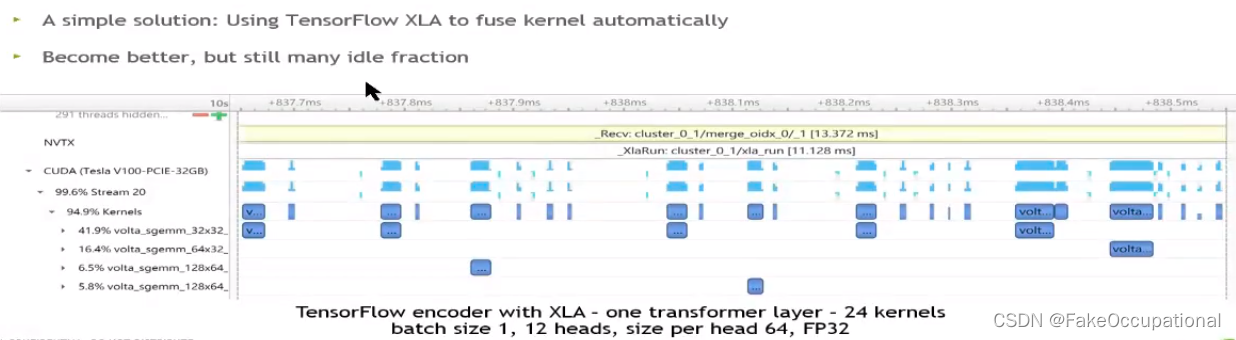
- 如图,可见host启动调用GPU会花费很多时间
- 在实际计算时,cpu和gpu各自计算,如果kernel很小,则gpu就需要等待cpu
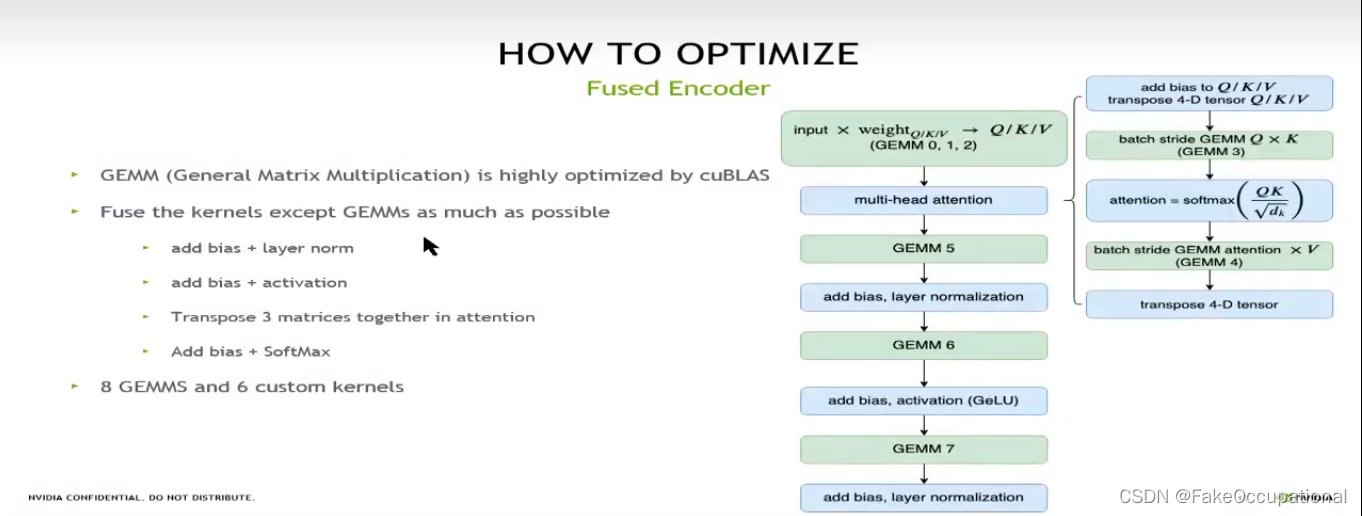
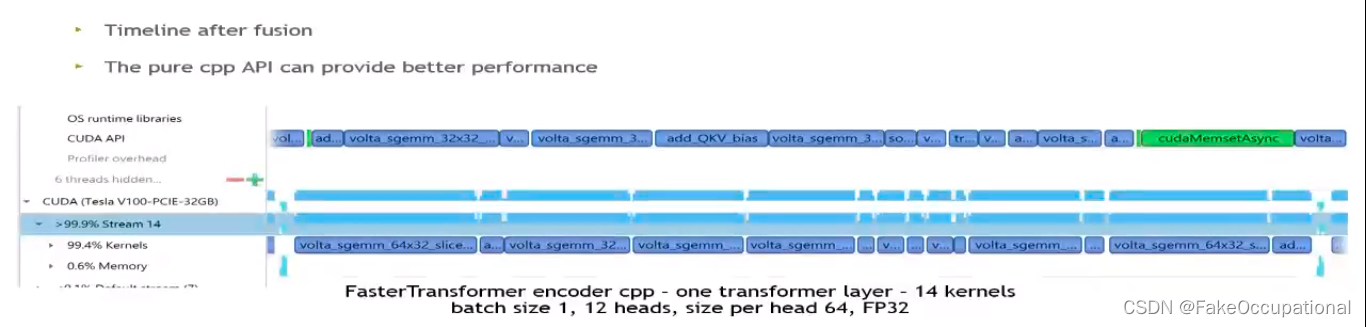
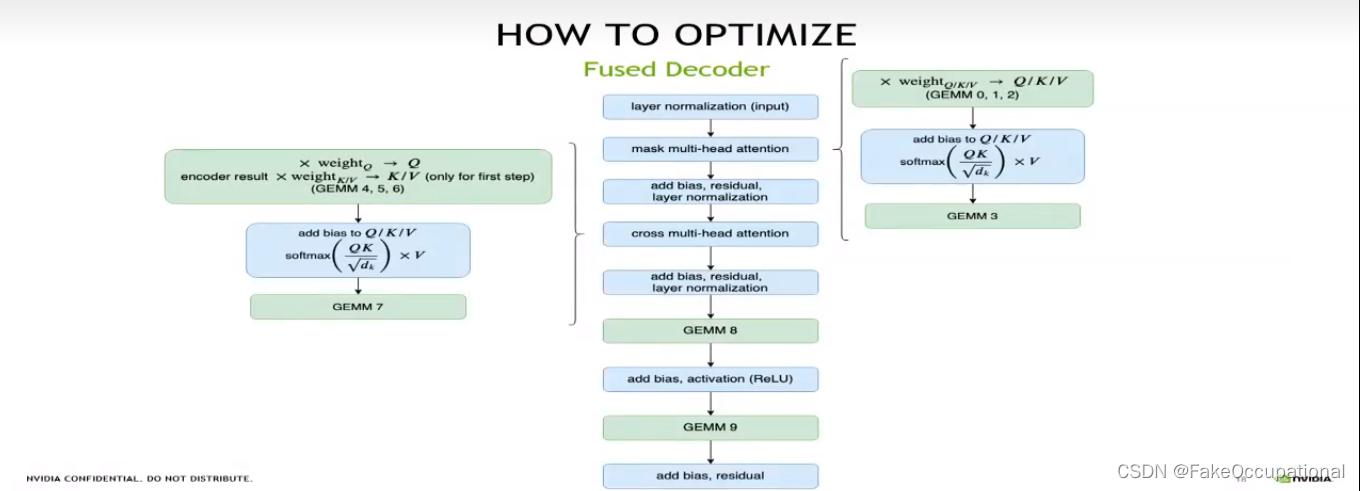
- GPU Kernel融合(Kernel Fusion)是一种优化技术,用于将多个GPU内核(Kernel)组合成一个更大的内核,减少内核之间通信和数据传输开销。在GPU编程中,内核是并行执行的函数,用于处理大规模数据集上的计任务。
当存在多个连续的内核时,个内核都需要从全内存中读取数据,并将结果写到全局内存。这涉及到内核之间的数据传输和同步操作,会引入额外延迟和开销而通过融合这些内核,可以减少数据传输和同步次数,从而提整体的性能和效率。
GPU Kernel融合的过程包以下步骤:
- 识别可以融合的内核:通过分析内核之间的依赖系和数据访问式,确定哪些内核可以被融合。
- 重组内核代码:将个内核的代码合成一个更的内核函数。
- 优化内访问:重新安内核中的内访问模式,以最小化全局内存的读写操作。
- 合并内核参数将多个内的参数合并为一个内核的参数列表。
- 生成融合后的内核根据融合后的代码和参数生成一个新的内函数。
通过GPU Kernel融合,可以减少内核之间的通信和数据传输开销提高GPU程序性能和效率这对于需要执行多个连续计算任务的应用程序特别有益,例如图像处理、机器学习和科学计算等领域。




KV Cache

// https://jaykmody.com/blog/gpt-from-scratch/#decoder-block
def generate(inputs, params, n_head, n_tokens_to_generate):from tqdm import tqdmfor _ in tqdm(range(n_tokens_to_generate), "generating"): # auto-regressive decode looplogits = gpt2(inputs, **params, n_head=n_head) # model forward passnext_id = np.argmax(logits[-1]) # greedy samplinginputs.append(int(next_id)) # append prediction to inputreturn inputs[len(inputs) - n_tokens_to_generate :] # only return generated ids
- GPT类解码器模型,注意力块的输入是q,k,v(和掩码)。实际上可以利用线性变换的线性性质,解码时候q只需要最后一个new_q,前面的没用,用new_q作为q(比如大小为[1,d_k])。然后,需要计算当前输入令牌的new_k(比如大小为[1,d_k])和new_v(比如大小为[1,d_k])。将其附加到现有缓存得到q(比如大小为[n,d_k])和k(比如大小为[n,d_k]),并将其传递给注意块以进行进一步处理atten(new_q, k, v)。但是这时只能输出最后一个的词概率
logits, kvcache = gpt2(inputs, **params, n_head=n_head, kvcache=kvcache) # model forward pass,最终代码如下:
// https://jaykmody.com/blog/gpt-from-scratch/#decoder-block
kvcache = None
for _ in tqdm(range(n_tokens_to_generate), "generating"): # auto-regressive decode looplogits, kvcache = gpt2(inputs, **params, n_head=n_head, kvcache=kvcache) # model forward passnext_id = np.argmax(logits[-1]) # greedy samplinginputs = np.append(inputs, [next_id]) # append prediction to input
CG
- http://giantpandacv.com/project/%E9%83%A8%E7%BD%B2%E4%BC%98%E5%8C%96/
- 智能 CPU 卸载是一种降低显存占用的方法。扩散模型 (如 Stable Diffusion) 的推理并不是运行一个单独的模型,而是多个模型组件的串行推理。如在推理 ControlNet Stable Diffusion 时,需要首先运行 CLIP 文本编码器,其次推理扩散模型 UNet 和 ControlNet,然后运行 VAE 解码器,最后运行 safety checker (安全检查器,主要用于审核过滤违规图像)。而在扩散过程中大多数组件仅运行一次,因此不需要一直占用 GPU 内存。通过启用智能模型卸载,可以确保每个组件在不需要参与 GPU 计算时卸载到 CPU 上,从而显著降低显存占用,并且不会显著增加推理时间 (仅增加了模型在 GPU-CPU 之间的转移时间)。
- https://zhuanlan.zhihu.com/p/630832593
- CUDA full GPU acceleration, KV cache in VRAM
mem reuse
- http://dlsys.cs.washington.edu/pdf/lecture9.pdf