一、简介
Java序列化框架是一种用于在Java应用程序中将对象转换为字节流或从字节流反序列化为对象的工具。序列化是将对象的状态转换为字节流的过程,以便可以将其存储在文件中、通过网络传输或在不同的系统之间共享。反序列化是将字节流转换回对象的过程。
Java序列化框架的主要目的是简化对象的序列化和反序列化过程,使开发人员可以更轻松地将对象保存到持久存储中,或者在分布式系统中传输对象。这些框架通常提供了高级功能,如版本控制、自定义序列化方式、压缩和加密等。
以下是笔者收集的Java部序列化框架(Protocol Buffers (ProtoBuf)、JSON 序列化框架),可能会因为项目需求和个人偏好而有不同的选择。以下是一些较为常见的 Java 序列化框架,以供参考。
二、Protocol Buffers (ProtoBuf)
Protocol Buffers(ProtoBuf)是一种由 Google 设计的用于序列化结构化数据的轻量级、高效、可扩展的框架。ProtoBuf 的设计目标是在不同的语言和平台之间高效地传输数据,并且可以轻松地进行扩展和演化。以下是 Protocol Buffers 框架的原理讲解:
-
数据定义语言(IDL):
在 ProtoBuf 中,首先需要使用一种叫做数据定义语言(IDL)的语法来定义数据结构。这个语法描述了数据的结构、字段名和数据类型。使用 IDL 可以明确地定义数据模型,然后使用 ProtoBuf 编译器将这些定义转换为不同语言的类或结构体。这种定义的方式使得数据结构变得可扩展且易于维护。 -
二进制编码:
ProtoBuf 使用二进制编码来序列化数据,而不是使用文本格式。这使得编码后的数据更紧凑且高效,适用于高性能的数据交换。二进制编码的格式相对简单,每个字段使用字段号标识,以及与字段类型对应的编码。 -
序列化和反序列化:
ProtoBuf 框架提供了编码和解码的功能,允许将数据序列化为二进制格式,以及从二进制格式反序列化为对象。序列化时,ProtoBuf 根据字段号和类型,将数据编码为紧凑的二进制形式。反序列化时,ProtoBuf 根据字段号和类型,解析二进制数据并重新构建出对象。 -
版本兼容性:
ProtoBuf 支持向后和向前的版本兼容性,这意味着您可以在不破坏现有数据的情况下进行数据模型的扩展或修改。当您更新数据定义时,可以在新版本中添加、删除或修改字段,而旧版本的解析器仍然可以正确地解析新版本的数据,忽略它们不识别的字段。 -
跨语言支持:
ProtoBuf 支持多种编程语言,包括但不限于 Java、C++、Python、Go、C# 等。ProtoBuf 编译器可以将 IDL 定义转换为各个语言的类或结构体,使得不同语言的应用程序可以轻松地进行数据交换。 -
性能和大小:
由于采用了紧凑的二进制编码格式,ProtoBuf 具有出色的性能和较小的数据大小。这使得它非常适用于网络通信、存储以及高性能的数据处理。 -
扩展性:
ProtoBuf 的数据定义是层次化的,允许在一个消息中嵌套其他消息,从而构建出复杂的数据结构。这种嵌套结构的设计使得数据模型可以按需扩展,更好地反映实际需求。
Protocol Buffers 框架通过二进制编码、紧凑性、版本兼容性和跨语言支持等特性,提供了一种高效、灵活和可扩展的数据序列化方案,适用于各种应用场景,特别是对性能和数据大小有严格要求的应用。这里我们用一个小的案例进行演示,首先安装Protocol并且进行配置环境变量。步骤如下:
首先去下载对应操作系统的 Protocol Buffers 编译器并配置对应的环境变量。点击此处到下载页面,本文演示的为win10操作系统,下载好解压到对应的文件夹,然后去path中配置环境变量到bin目录下。下图为笔者下载版本:
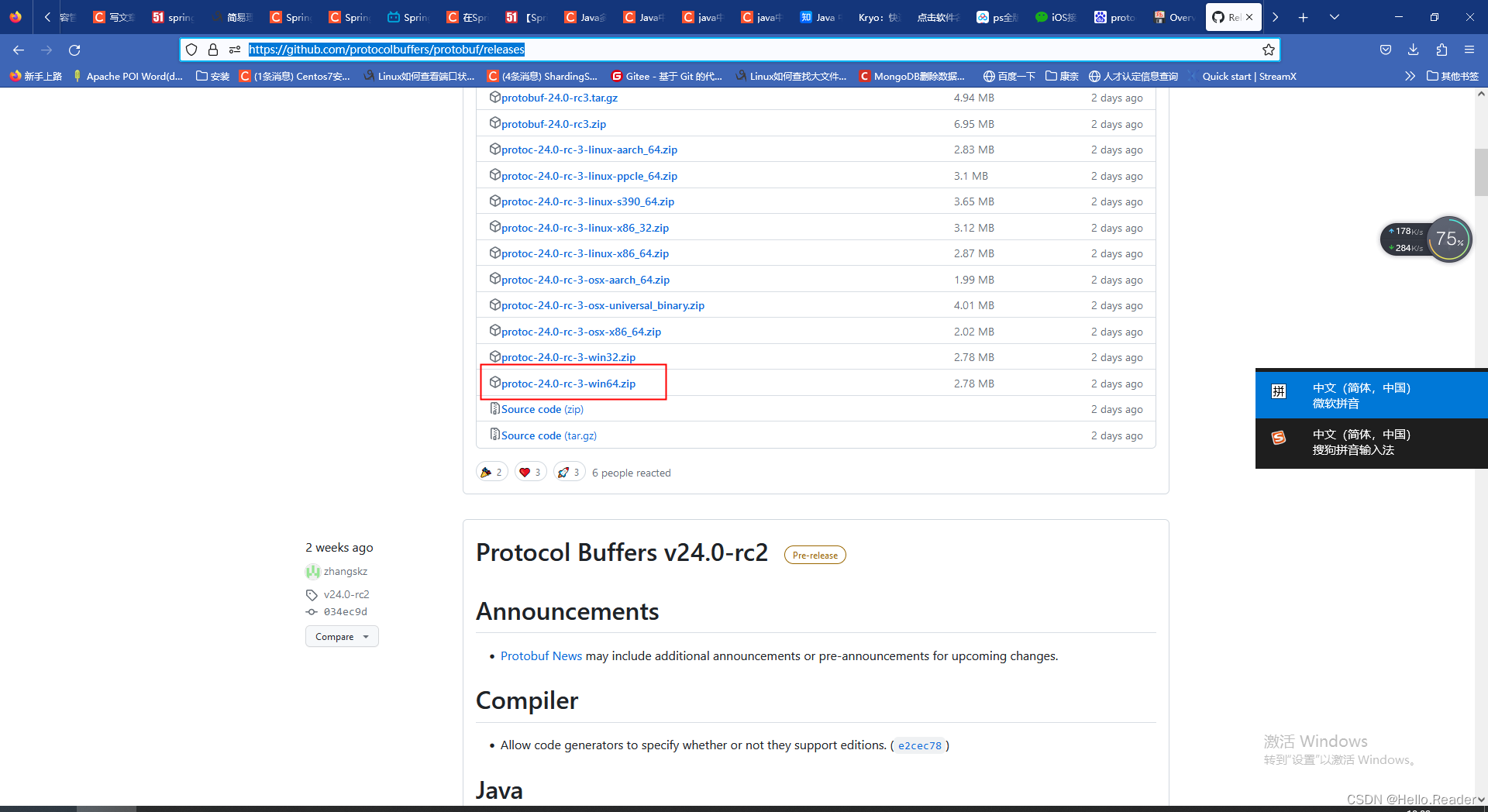
D:\i-tools\protoc-23.4-win64\bin #是笔者本机的路径,笔者的版本为protoc3
如果是macos系统,你可以使用 Homebrew 进行安装,命令如下:
brew install protobuf
在 Linux(Ubuntu) 上,你可以使用以下命令来安装 Protocol Buffers 编译器:
sudo apt-get update
sudo apt-get install protobuf-compiler
安装完编译器后,你需要将 Protocol Buffers 的 bin 目录添加到系统的 PATH 环境变量中,这样你就可以在命令行中直接运行 protoc 命令。
在 Linux 和 macOS 上,你可以编辑 shell 配置文件(如 ~/.bashrc 或 ~/.zshrc),添加如下行:
export PATH="$PATH:/usr/local/bin"
首先需要编写一个 .proto 文件,定义数据结构和消息格式。这个文件描述了你要传输的数据的类型和字段。例如,假设你要定义一个简单的消息,可以编写以下 .proto 文件:
syntax = "proto3";package protocol;option java_package = "cn.konne.konneim.serverim.model"; //生成的包名,填你自己的包路径即可option java_outer_classname="PersonProto"; //生成的实体名message Person {string name = 1;int32 age = 2;
}使用 Protocol Buffers 编译器将 .proto 文件编译成 Java 代码。打开终端,切换到包含 .proto 文件的目录,然后运行以下命令:
protoc --java_out=. your_proto_file.proto #使用idea自带插件可以生成,并且提高开发效率。笔者使用的是Gen Protobuf
这会生成一个名为 PersonProto.java 的文件,其中包含生成的 Java 类来表示你在 .proto 文件中定义的消息。
在你的 Java 代码中,你可以导入生成的类,并使用它们来创建、序列化和反序列化消息。
引入对应的maven文件
<dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java-util</artifactId><version>3.23.0</version></dependency>
以下是一个简单的示例:
import com.google.protobuf.InvalidProtocolBufferException;public class PersonTest {public static void main(String[] args) {// 创建一个 Person 对象PersonProto.Person person = PersonProto.Person.newBuilder().setName("Alice").setAge(30).build();// 将 Person 对象序列化为字节数组byte[] data = person.toByteArray();// 从字节数组反序列化为 Person 对象PersonProto.Person parsedPerson = null;try {parsedPerson = PersonProto.Person.parseFrom(data);// 打印解析后的 Person 对象System.out.println("Name: " + parsedPerson.getName());System.out.println("Age: " + parsedPerson.getAge());} catch (InvalidProtocolBufferException e) {throw new RuntimeException(e);} }
}
运行结果如下:
Name: Alice
Age: 30Process finished with exit code 0
二、Java 原生序列化
Java 原生序列化(Native Serialization)是一种将 Java 对象转换为字节流,以便将其存储在文件中、通过网络传输或在内存中传递的机制。Java 提供了 java.io.Serializable 接口和 java.io.ObjectOutputStream、java.io.ObjectInputStream 类来支持原生序列化。以下是 Java 原生序列化的一些原理讲解:
-
java.io.Serializable接口:
Java 的原生序列化机制要求被序列化的类实现java.io.Serializable接口。这个接口没有任何方法,它只是一个标记接口,用于指示该类可以被序列化。当一个类实现了Serializable接口,它的对象可以被序列化和反序列化。 -
序列化过程:
当你想将一个对象序列化时,Java 原生序列化机制会将对象的状态(即对象的成员变量)以及一些额外的元数据(如类的名称、序列化版本号等)转换为一个字节流。这个字节流可以存储在文件、传输到网络上或者在内存中传递。 -
ObjectOutputStream类:
ObjectOutputStream是用于将 Java 对象序列化为字节流的类。你可以将一个ObjectOutputStream与一个输出流(如文件输出流、网络输出流等)关联起来,然后使用它将对象写入输出流中。ObjectOutputStream会自动处理对象图中的所有对象,将它们转换为字节流。 -
反序列化过程:
当你想从一个字节流中恢复一个对象时,Java 原生序列化机制会将字节流反序列化为对象的状态和元数据。这个过程会创建一个新的对象,然后将状态数据填充到对象的成员变量中。 -
ObjectInputStream类:
ObjectInputStream是用于从字节流中反序列化 Java 对象的类。你可以将一个ObjectInputStream与一个输入流(如文件输入流、网络输入流等)关联起来,然后使用它从输入流中读取字节流并将其反序列化为对象。 -
版本兼容性:
在序列化和反序列化过程中,Java 原生序列化机制会使用类的序列化版本号来验证类的版本兼容性。如果序列化的类版本与反序列化时的类版本不匹配,可能会导致版本不兼容的错误。
尽管 Java 原生序列化提供了一种简单的序列化和反序列化机制,但它也有一些缺点及局限性,如序列化后的数据比较臃肿、性能相对较低,而且不够灵活。在一些情况下,可能会考虑使用其他第三方的序列化框架,以获得更好的性能和灵活性。
这里我们就不过多讲述了,这里我们编写一简单的示例,代码如下图所示:
import java.io.*;class Person implements Serializable {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}
}public class SerializationExample {public static void main(String[] args) {// 创建一个 Person 对象Person person = new Person("Alice", 30);// 将 Person 对象序列化到文件serializePerson(person, "person.ser");// 从文件中反序列化 Person 对象Person deserializedPerson = deserializePerson("person.ser");// 打印反序列化后的对象属性System.out.println("Name: " + deserializedPerson.getName());System.out.println("Age: " + deserializedPerson.getAge());}// 将对象序列化到文件private static void serializePerson(Person person, String filename) {try (FileOutputStream fileOut = new FileOutputStream(filename);ObjectOutputStream out = new ObjectOutputStream(fileOut)) {out.writeObject(person);System.out.println("Serialized data is saved in " + filename);} catch (IOException e) {e.printStackTrace();}}// 从文件中反序列化对象private static Person deserializePerson(String filename) {try (FileInputStream fileIn = new FileInputStream(filename);ObjectInputStream in = new ObjectInputStream(fileIn)) {return (Person) in.readObject();} catch (IOException | ClassNotFoundException e) {e.printStackTrace();return null;}}
}运行结果如下:
Serialized data is saved in person.ser
Name: Alice
Age: 30Process finished with exit code 0
三、JSON 序列化框架
Jackson: 高性能的 JSON 序列化和反序列化库。
Jackson 是一个用于处理 JSON 格式数据的 Java 库,它提供了序列化(将 Java 对象转换为 JSON 格式数据)和反序列化(将 JSON 格式数据转换为 Java 对象)的功能。Jackson 具有高性能、灵活性和广泛的应用,是在 Java 中处理 JSON 数据的常用选择之一。以下是 Jackson 的一些原理讲解:
-
JSON 数据结构映射:
Jackson 允许将 JSON 数据映射到 Java 对象,以及将 Java 对象映射到 JSON 数据。你可以使用注解或者配置来定义 JSON 数据和 Java 对象之间的映射关系。 -
ObjectMapper类:
Jackson 的核心类是ObjectMapper,它提供了序列化和反序列化 JSON 数据的方法。你可以使用ObjectMapper的实例来执行 JSON 数据和 Java 对象之间的转换操作。 -
注解驱动:
Jackson 支持使用注解来配置 JSON 映射,如@JsonProperty、@JsonCreator等。通过在 Java 类的字段或方法上使用这些注解,你可以指示 Jackson 如何进行序列化和反序列化。 -
JSON 树模型:
Jackson 提供了一个 JSON 树模型,允许你以树结构的方式访问和操作 JSON 数据。你可以使用JsonNode类来表示 JSON 数据,进行查询、修改等操作。 -
数据绑定:
Jackson 支持从 JSON 数据绑定到 Java 对象,或者从 Java 对象绑定到 JSON 数据。你可以使用readValue()方法来执行 JSON 数据到对象的绑定,以及使用writeValue()方法将对象转换为 JSON 数据。 -
支持多种数据格式:
Jackson 支持处理不同的 JSON 数据格式,如 JSON 对象、JSON 数组等。它也支持处理各种 Java 数据类型,包括基本类型、集合、Map 等。 -
自定义序列化和反序列化:
你可以编写自定义的序列化器和反序列化器,以满足特定需求。通过实现JsonSerializer和JsonDeserializer接口,你可以在序列化和反序列化过程中进行自定义处理。 -
跨平台支持:
Jackson 支持多个平台,包括 Java SE、Java EE、Android 等。这使得开发人员可以在不同平台上使用相同的代码来处理 JSON 数据。
Jackson 是一个强大的 Java 库,用于处理 JSON 数据的序列化和反序列化。它通过注解、ObjectMapper 类、JSON 树模型和自定义序列化器等原理,提供了灵活、高性能的 JSON 数据处理能力,适用于广泛的应用场景。
这里我们创建一个简单的示例来演示如何进行 JSON 的序列化和反序列化操作。以下是一个使用 Jackson 库的示例代码:
需要先在项目中添加 Jackson 的依赖。如果使用 Maven,可以在 pom.xml 中添加以下依赖:
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.12.5</version> <!-- 根据实际情况使用最新版本,如果在springboot项目中引入,则不需要填写版本好,它本身就是spring的技术栈 -->
</dependency>
然后,我们来看一个简单的示例:
import com.fasterxml.jackson.databind.ObjectMapper;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}public class JacksonExample {public static void main(String[] args) throws Exception {// 创建一个 ObjectMapper 实例ObjectMapper objectMapper = new ObjectMapper();// 创建一个 Person 对象Person person = new Person("Alice", 30);// 将 Person 对象序列化为 JSON 格式字符串String json = objectMapper.writeValueAsString(person);System.out.println("Serialized JSON: " + json);// 从 JSON 格式字符串反序列化为 Person 对象Person deserializedPerson = objectMapper.readValue(json, Person.class);// 打印反序列化后的对象属性System.out.println("Name: " + deserializedPerson.getName());System.out.println("Age: " + deserializedPerson.getAge());}
}
运行结果如下:
Serialized JSON: {"name":"Alice","age":30}
Name: Alice
Age: 30
Gson: Google 提供的简单易用的 JSON 序列化库。
Gson 是一个用于处理 JSON 格式数据的 Java 库,它提供了将 Java 对象序列化为 JSON 格式数据和将 JSON 格式数据反序列化为 Java 对象的功能。Gson 具有简单易用、灵活性和广泛的应用,是在 Java 中处理 JSON 数据的另一种常用选择。以下是 Gson 的一些原理讲解:
-
JSON 数据结构映射:
Gson 允许将 JSON 数据映射到 Java 对象,以及将 Java 对象映射到 JSON 数据。你可以使用注解或者通过配置来定义 JSON 数据和 Java 对象之间的映射关系。 -
Gson类:
Gson 的核心类是Gson,它提供了序列化和反序列化 JSON 数据的方法。你可以创建一个Gson的实例来执行 JSON 数据和 Java 对象之间的转换操作。 -
注解驱动:
Gson 支持使用注解来配置 JSON 映射,如@SerializedName、@Expose等。通过在 Java 类的字段上使用这些注解,你可以指示 Gson 如何进行序列化和反序列化。 -
JSON 树模型:
Gson 提供了一个 JSON 树模型,允许你以树结构的方式访问和操作 JSON 数据。你可以使用JsonElement类来表示 JSON 数据,进行查询、修改等操作。 -
数据绑定:
Gson 支持从 JSON 数据绑定到 Java 对象,或者从 Java 对象绑定到 JSON 数据。你可以使用fromJson()方法来执行 JSON 数据到对象的绑定,以及使用toJson()方法将对象转换为 JSON 数据。 -
支持多种数据格式:
Gson 支持处理不同的 JSON 数据格式,如 JSON 对象、JSON 数组等。它也支持处理各种 Java 数据类型,包括基本类型、集合、Map 等。 -
自定义序列化和反序列化:
你可以编写自定义的序列化器和反序列化器,以满足特定需求。通过实现JsonSerializer和JsonDeserializer接口,你可以在序列化和反序列化过程中进行自定义处理。 -
跨平台支持:
Gson 支持多个平台,包括 Java SE、Java EE、Android 等。这使得开发人员可以在不同平台上使用相同的代码来处理 JSON 数据。
Gson 是一个简单易用的 Java 库,用于处理 JSON 数据的序列化和反序列化。它通过注解、Gson 类、JSON 树模型和自定义序列化器等原理,提供了灵活、高性能的 JSON 数据处理能力,适用于广泛的应用场景。
在这里我们可以创建一个简单的示例来演示如何进行 JSON 的序列化和反序列化操作。以下是一个使用 Gson 库的示例代码:
需要在项目中添加 Gson 的依赖。如果使用 Maven,可以在 pom.xml 中添加以下依赖:
<dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.8</version> <!-- 根据实际情况使用最新版本 -->
</dependency>
然后,我们来看一个简单的示例:
import com.google.gson.Gson;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}public class GsonExample {public static void main(String[] args) {// 创建一个 Gson 实例Gson gson = new Gson();// 创建一个 Person 对象Person person = new Person("Alice", 30);// 将 Person 对象序列化为 JSON 格式字符串String json = gson.toJson(person);System.out.println("Serialized JSON: " + json);// 从 JSON 格式字符串反序列化为 Person 对象Person deserializedPerson = gson.fromJson(json, Person.class);// 打印反序列化后的对象属性System.out.println("Name: " + deserializedPerson.getName());System.out.println("Age: " + deserializedPerson.getAge());}
}
运行结果如下:
Serialized JSON: {"name":"Alice","age":30}
Name: Alice
Age: 30Process finished with exit code 0Fastjson: 阿里巴巴开发的快速 JSON 序列化框架。
Fastjson 是一个用于处理 JSON 格式数据的 Java 库,它提供了高性能的 JSON 序列化和反序列化功能。Fastjson 具有出色的性能和广泛的应用,是在 Java 中处理 JSON 数据的另一种常用选择。以下是 Fastjson 的一些原理讲解:
-
JSON 数据结构映射:
Fastjson 允许将 JSON 数据映射到 Java 对象,以及将 Java 对象映射到 JSON 数据。你可以使用注解或者配置来定义 JSON 数据和 Java 对象之间的映射关系。 -
JSON类:
Fastjson 的核心类是JSON,它提供了序列化和反序列化 JSON 数据的方法。你可以使用JSON类来执行 JSON 数据和 Java 对象之间的转换操作。 -
注解驱动:
Fastjson 支持使用注解来配置 JSON 映射,如@JSONField、@JSONType等。通过在 Java 类的字段上使用这些注解,你可以指示 Fastjson 如何进行序列化和反序列化。 -
数据绑定:
Fastjson 支持从 JSON 数据绑定到 Java 对象,或者从 Java 对象绑定到 JSON 数据。你可以使用parseObject()方法执行 JSON 数据到对象的绑定,以及使用toJSONString()方法将对象转换为 JSON 数据。 -
支持多种数据格式:
Fastjson 支持处理不同的 JSON 数据格式,如 JSON 对象、JSON 数组等。它也支持处理各种 Java 数据类型,包括基本类型、集合、Map 等。 -
自定义序列化和反序列化:
你可以编写自定义的序列化器和反序列化器,以满足特定需求。通过实现SerializeFilter和ObjectDeserializer接口,你可以在序列化和反序列化过程中进行自定义处理。 -
跨平台支持:
Fastjson 支持多个平台,包括 Java SE、Java EE、Android 等。这使得开发人员可以在不同平台上使用相同的代码来处理 JSON 数据。
Fastjson 是一个高性能且功能丰富的 Java 库,用于处理 JSON 数据的序列化和反序列化。它通过注解、JSON 类、自定义序列化器等原理,提供了灵活、高性能的 JSON 数据处理能力,适用于广泛的应用场景。
在这里我们创建一个简单的示例来演示如何进行 JSON 的序列化和反序列化操作。以下是一个使用 Fastjson 库的示例代码:
需要在项目中添加 Fastjson 的依赖。如果使用 Maven,可以在 pom.xml 中添加以下依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.78</version> <!-- 根据实际情况使用最新版本 -->
</dependency>
然后,我们来看一个简单的示例:
import com.alibaba.fastjson.JSON;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}public class FastjsonExample {public static void main(String[] args) {// 创建一个 Person 对象Person person = new Person("Alice", 30);// 将 Person 对象序列化为 JSON 格式字符串String json = JSON.toJSONString(person);System.out.println("Serialized JSON: " + json);// 从 JSON 格式字符串反序列化为 Person 对象Person deserializedPerson = JSON.parseObject(json, Person.class);// 打印反序列化后的对象属性System.out.println("Name: " + deserializedPerson.getName());System.out.println("Age: " + deserializedPerson.getAge());}
}
运行结果如下:
Serialized JSON: {"age":30,"name":"Alice"}
Name: Alice
Age: 30Process finished with exit code 0
四、 XML 序列化框架
本篇不进行重点阐述讲解,XML数据传输现在用的比较少了
- JAXB: Java Architecture for XML Binding,支持 Java 类到 XML 数据的绑定。
- XStream: 简单易用的 XML 序列化框架。
五、Apache Avro
Apache Avro 是一种由 Apache 基金会开发的数据序列化系统,用于跨语言、跨平台的数据交换。Avro 具有轻量级、高性能和灵活的特点,适用于大规模数据处理、数据存储和远程通信。以下是 Apache Avro 框架的原理讲解:
-
数据定义语言(IDL):
类似于 Protocol Buffers,Apache Avro 也使用一种数据定义语言(IDL)来定义数据结构。IDL 定义了数据模型、字段名、数据类型和默认值。这些定义可以用于生成不同编程语言的类或结构体。
-
动态模式:
Avro 支持动态模式(Dynamic Schema),这意味着数据本身携带了其模式信息。每条记录都包含了与之关联的模式,使得数据在不同的系统之间可以自描述。这种自描述性使得 Avro 数据在跨语言和跨平台通信时更加灵活。 -
二进制编码:
Avro 使用二进制编码格式,将数据序列化为紧凑的二进制形式。编码格式包含了字段名、数据类型以及实际数据值。由于采用了二进制格式,Avro 数据在传输和存储时非常高效。 -
Schema Evolution:
Avro 支持模式的演化(Schema Evolution),允许在不破坏现有数据的情况下对模式进行扩展或修改。新版本的模式可以包含新增的字段或者修改字段的数据类型,而旧版本的解析器仍然可以正确地解析新版本的数据。 -
跨语言支持:
Apache Avro 支持多种编程语言,包括但不限于 Java、C、C++、Python、Ruby、JavaScript 等。Avro 模式可以被编译成各种语言的类,使得不同语言的应用程序能够轻松地读写 Avro 数据。 -
通信和存储:
Avro 适用于远程通信和数据存储。它可以用于构建高性能的 RPC(远程过程调用)系统,也可以用于将数据序列化后存储到文件或分布式存储系统中,如 Hadoop HDFS。 -
Code Generation vs. Reflection:
Avro 提供了两种数据访问的方式:代码生成(Code Generation)和反射(Reflection)。代码生成将 Avro 模式转换为编程语言的类,提供了高性能的数据访问。反射则允许直接从模式中提取数据,更加灵活但性能较低。 -
性能优化:
由于使用了紧凑的二进制编码,Avro 具有较高的性能和较小的数据大小。此外,通过使用代码生成,Avro 可以实现更快速的数据访问。
Apache Avro 是一种灵活、高性能、跨语言的数据序列化框架,具有自描述性、模式演化和紧凑的二进制编码特点,适用于大数据处理、分布式系统和数据交换场景。
Apache Avro 是一种数据序列化系统,用于跨多种编程语言和平台高效地传输数据。下面是一个简单的示例,演示如何使用 Avro 生成 Java 代码,并进行序列化和反序列化操作。
首先,你需要安装 Avro 工具并编写一个 Avro schema 文件来定义数据结构。以下是一个示例 Avro schema 文件:
{"type": "record","name": "Person","fields": [{"name": "name", "type": "string"},{"name": "age", "type": "int"}]
}
接下来,我们编写一个 Java 程序来演示 Avro 的序列化和反序列化操作。
需要在项目中添加 Avro 的依赖。如果使用 Maven,可以在 pom.xml 中添加以下依赖:
<dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.11.2</version></dependency>
以下是一个简单的示例代码:
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumReader;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.io.Decoder;
import org.apache.avro.io.Encoder;
import org.apache.avro.io.JsonEncoder;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;import java.io.ByteArrayOutputStream;public class AvroExample {public static void main(String[] args) throws Exception {// 定义 Avro schema 字符串String schemaString = "{\"type\":\"record\",\"name\":\"Person\",\"fields\":[{\"name\":\"name\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"int\"}]}";// 创建 Avro schema 对象Schema schema = new Schema.Parser().parse(schemaString);// 创建一个 GenericRecord 对象GenericRecord person = new GenericData.Record(schema);person.put("name", "Alice");person.put("age", 30);// 序列化 GenericRecord 对象为 JSON 格式字节数组ByteArrayOutputStream out = new ByteArrayOutputStream();Encoder encoder = new JsonEncoder(schema, out);DatumWriter<GenericRecord> writer = new SpecificDatumWriter<>(schema);writer.write(person, encoder);encoder.flush();byte[] jsonBytes = out.toByteArray();System.out.println("Serialized JSON: " + new String(jsonBytes));// 反序列化 JSON 格式字节数组为 GenericRecord 对象Decoder decoder = new JsonDecoder(schema, new String(jsonBytes));DatumReader<GenericRecord> reader = new SpecificDatumReader<>(schema);GenericRecord deserializedPerson = reader.read(null, decoder);// 打印反序列化后的对象属性System.out.println("Name: " + deserializedPerson.get("name"));System.out.println("Age: " + deserializedPerson.get("age"));}
}六、Kryo
Kryo 是一种快速、高性能的 Java 序列化框架,用于将对象序列化成字节流,以便在网络传输、数据存储或内存缓存等场景中使用。Kryo 旨在提供比 Java 原生序列化更高的性能和更小的序列化尺寸。以下是 Kryo 框架的原理讲解:
-
对象图遍历:
Kryo 序列化的核心原理是通过遍历对象图来将对象转换为字节流。对象图是由多个对象组成的层次结构,Kryo 会递归遍历这些对象,并将每个对象的字段转换为字节流。 -
注册类和序列化器:
为了加速序列化和反序列化过程,Kryo 允许用户注册需要序列化的类和对应的序列化器。序列化器是负责将特定类的对象转换为字节流,以及将字节流转换回对象的组件。通过注册类和序列化器,Kryo 可以避免在序列化过程中动态发现类信息,从而提高性能。 -
紧凑的二进制格式:
Kryo 使用一种紧凑的二进制格式来序列化数据。每个对象都由类型信息和字段值组成,类型信息用于指示对象的类,字段值则是对象各个字段的实际数据。Kryo 会按照字段在类中的声明顺序将字段值序列化为字节流。 -
自定义序列化策略:
Kryo 允许用户自定义序列化策略,以便对特定类的字段进行更精细的控制。用户可以通过实现 Kryo 的 Serializer 接口来自定义序列化和反序列化逻辑,以满足特定的需求,比如跳过某些字段的序列化,或者采用特定的压缩算法。 -
对象引用和循环引用:
Kryo 支持对象引用和处理循环引用。当多个对象引用同一个对象时,Kryo 会确保序列化后的数据只包含一个实例,并在反序列化时正确地恢复引用关系。同时,Kryo 也能处理循环引用,避免无限递归遍历。 -
高性能特性:
Kryo 的设计目标之一是高性能。它通过减少序列化尺寸和优化序列化/反序列化算法来实现快速的数据转换。Kryo 避免了 Java 原生序列化中的一些性能问题,如冗余的类型信息和大量的元数据。 -
支持多种数据类型:
Kryo 支持序列化多种数据类型,包括基本类型、数组、集合、映射、枚举、自定义对象等。用户可以根据需要序列化不同类型的数据。
Kryo 框架通过对象图遍历、紧凑的二进制格式、自定义序列化策略等原理,实现了高性能的对象序列化和反序列化。它适用于需要快速、高效的数据传输和存储场景,特别是在大数据量和高性能要求下表现出色。
接下来,我们编写一个 Java 程序来演示 Kryo 的序列化和反序列化操作。
需要在项目中添加 Kryo 的依赖。如果使用 Maven,可以在 pom.xml 中添加以下依赖:
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>3.0.3</version></dependency>
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;class Person {private String name;private int age;// 构造函数、getter 和 setter 方法public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}}public class KryoSerializationExample {public static void main(String[] args) {// 创建 Kryo 实例Kryo kryo = new Kryo();// 创建一个 Person 对象Person person = new Person();person.setName("Alice");person.setAge(30);// 序列化 Person 对象为字节数组ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();Output output = new Output(byteArrayOutputStream);kryo.writeObject(output, person);output.close();byte[] serializedData = byteArrayOutputStream.toByteArray();// 反序列化字节数组为 Person 对象ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);Input input = new Input(byteArrayInputStream);Person deserializedPerson = kryo.readObject(input, Person.class);input.close();// 打印反序列化后的对象System.out.println("Original Person: " + person);System.out.println("Deserialized Person: " + deserializedPerson);}
}七、FST (Fast-Serialization)
FST(Fast-Serialization Toolkit)是一个高性能的 Java 序列化框架,旨在提供比标准 Java 序列化更快的序列化和反序列化速度。FST 的设计原理主要包括以下几个方面:
-
基于字节码生成的序列化器和反序列化器:
FST 使用基于字节码生成的方式创建序列化器和反序列化器。它会动态地生成特定类的字节码,用于将对象序列化为字节流和将字节流反序列化为对象。这种方式避免了反射的开销,提高了序列化和反序列化的性能。 -
紧凑的二进制格式:
FST 使用一种紧凑的二进制格式来表示序列化后的数据。它会按照对象的实际布局,以及字段的数据类型和长度,将数据编码为字节流。这种紧凑的格式减少了数据的大小,从而降低了网络传输和存储的开销。 -
对象图遍历:
类似于其他序列化框架,FST 也会遍历对象图,将整个对象图的数据序列化为字节流。它会递归地序列化对象的字段,包括基本类型、数组、集合、映射等,以及嵌套的自定义对象。 -
支持循环引用和共享引用:
FST 支持处理循环引用和共享引用。循环引用是指对象之间存在相互引用关系,而共享引用是指多个对象引用同一个对象。FST 能够正确地处理这些引用关系,确保序列化和反序列化的正确性。 -
对象缓存和复用:
为了提高性能,FST 会缓存已生成的序列化器和反序列化器,以及已序列化的类信息。这样,在序列化和反序列化时可以直接复用缓存的信息,避免重复生成和解析。 -
支持自定义序列化策略:
FST 允许用户自定义序列化策略,以满足特定的需求。用户可以实现 FST 库提供的接口,自定义字段的序列化和反序列化逻辑,以及对象的创建和复用策略。 -
高性能特性:
FST 的设计目标之一是提供高性能的序列化和反序列化。通过基于字节码生成的方式、紧凑的二进制格式、对象缓存等优化,FST 在序列化和反序列化速度上表现出色。
FST(Fast-Serialization Toolkit)框架通过基于字节码生成的序列化器和反序列化器、紧凑的二进制格式、对象图遍历等原理,实现了高性能的对象序列化和反序列化。它适用于需要快速、高效数据传输和存储的场景,特别是在大数据量和高性能要求下表现出色。
FST(Fast-Serialization)是另一个高性能的 Java 序列化库。它提供了快速的序列化和反序列化操作,并且相比 Java 原生的序列化,它可以显著地提高性能和减少序列化数据大小。以下是一个使用 FST 序列化库的示例代码:
首先,确保在 pom.xml 文件中添加 FST 的依赖配置,如下所示:
<dependency><groupId>de.ruedigermoeller</groupId><artifactId>fst</artifactId><version>2.57</version>
</dependency>
接下来,我们来编写示例代码:
import org.nustaq.serialization.FSTObjectInput;
import org.nustaq.serialization.FSTObjectOutput;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.Serializable;class Person implements Serializable {private String name;private int age;// 构造函数、getter 和 setter 方法public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class FSTSerializationExample {public static void main(String[] args) throws IOException, ClassNotFoundException {// 创建一个 Person 对象Person person = new Person();person.setName("Alice");person.setAge(30);// 序列化 Person 对象为字节数组ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();FSTObjectOutput output = new FSTObjectOutput(byteArrayOutputStream);output.writeObject(person);output.flush();byte[] serializedData = byteArrayOutputStream.toByteArray();// 反序列化字节数组为 Person 对象ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);FSTObjectInput input = new FSTObjectInput(byteArrayInputStream);Person deserializedPerson = (Person) input.readObject();input.close();// 打印反序列化后的对象System.out.println("Original Person: " + person);System.out.println("Deserialized Person: " + deserializedPerson);}
}
八、Hessian
Hessian 是一种基于二进制的远程调用协议和序列化框架,用于在分布式系统中进行跨语言的远程调用和数据传输。它支持多种编程语言,如 Java、Python、C# 等。Hessian 的原理可以总结如下:
-
二进制协议:
Hessian 使用二进制协议来进行数据传输和序列化。在传输数据之前,Hessian 将数据序列化为二进制格式,然后通过网络进行传输。接收方接收到二进制数据后,再进行反序列化,将二进制数据转换为原始对象。 -
序列化和反序列化:
Hessian 使用自定义的序列化和反序列化算法来处理数据。序列化是将对象转换为二进制数据的过程,而反序列化是将二进制数据还原为原始对象的过程。Hessian 的序列化和反序列化算法具有高效性能,可以在不同语言之间进行数据交换。 -
数据类型映射:
Hessian 将不同编程语言的数据类型映射到通用的数据类型。例如,Hessian 使用标准的数据类型表示整数、浮点数、字符串等,从而确保在跨语言调用时数据类型的一致性。 -
RPC(远程过程调用)支持:
除了数据序列化,Hessian 还提供了远程调用的支持。它允许客户端调用远程服务器上的方法,就像调用本地方法一样。客户端将方法调用的参数序列化为二进制数据并发送给服务器,服务器接收后进行反序列化并执行对应的方法,最后将结果序列化返回给客户端。 -
性能和效率:
Hessian 的设计目标之一是提供高性能和高效的数据传输。通过使用二进制协议、紧凑的数据格式以及高效的序列化和反序列化算法,Hessian 在数据传输和处理方面表现出色。 -
跨语言支持:
Hessian 支持多种编程语言,这使得不同语言的应用程序可以进行远程调用和数据传输。每种语言都有相应的 Hessian 库,用于实现序列化、反序列化和远程调用的功能。 -
版本兼容性:
Hessian 具有一定的版本兼容性,可以处理一些模式的演化。然而,更复杂的模式变化可能需要手动进行处理,以确保在不同版本之间的兼容性。
Hessian 是一种基于二进制的远程调用协议和序列化框架,通过二进制协议、序列化、反序列化和跨语言支持等原理,实现了高性能的分布式数据传输和远程调用。它适用于需要在分布式系统中进行跨语言调用和数据传输的场景。
以下是一个使用 Hessian 序列化库的示例代码:
首先,确保在 pom.xml 文件中添加 Hessian 的依赖配置,如下所示:
<dependency><groupId>com.caucho</groupId><artifactId>hessian</artifactId><version>4.0.38</version>
</dependency>
接下来,我们来编写示例代码:
import com.caucho.hessian.io.Hessian2Input;
import com.caucho.hessian.io.Hessian2Output;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.Serializable;class Person implements Serializable {private String name;private int age;// 构造函数、getter 和 setter 方法public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}
}public class HessianSerializationExample {public static void main(String[] args) throws IOException {// 创建一个 Person 对象Person person = new Person();person.setName("Alice");person.setAge(30);// 序列化 Person 对象为字节数组ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();Hessian2Output output = new Hessian2Output(byteArrayOutputStream);output.writeObject(person);output.flush();byte[] serializedData = byteArrayOutputStream.toByteArray();// 反序列化字节数组为 Person 对象ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);Hessian2Input input = new Hessian2Input(byteArrayInputStream);Person deserializedPerson = (Person) input.readObject();input.close();// 打印反序列化后的对象System.out.println("Original Person: " + person);System.out.println("Deserialized Person: " + deserializedPerson);}
}
九、Msgpack
MessagePack(简称 Msgpack)是一种高效的二进制序列化格式,用于在不同编程语言之间进行数据交换。它采用紧凑的二进制编码方式,旨在提供比 JSON、XML 等文本格式更高性能的数据序列化和反序列化。以下是 MessagePack 的原理讲解:
-
二进制编码:
MessagePack 使用二进制编码来序列化数据,将数据转换为紧凑的二进制格式。相比于文本格式(如 JSON 或 XML),二进制编码可以减少数据的大小,从而提高数据传输和存储的效率。 -
数据类型和格式编码:
在 MessagePack 中,不同的数据类型(如整数、浮点数、字符串、数组、映射等)被编码成不同的格式。每种数据类型的格式由特定的标识符表示。例如,整数可以使用不同的格式表示有符号整数和无符号整数。 -
变长编码:
为了进一步减小数据大小,MessagePack 采用了变长编码。对于小于 128 的整数或字符串等数据,它可以采用一个字节表示,而对于较大的数据,会使用多个字节进行编码。这种变长编码可以有效地减少数据的冗余。 -
数据格式无关性:
MessagePack 的设计目标之一是实现数据格式的无关性,即不同编程语言和平台之间可以互相解析 MessagePack 格式的数据。为了达到这个目标,MessagePack 定义了固定的格式规范,所有的实现都遵循这个规范。 -
跨语言支持:
MessagePack 支持多种编程语言,包括但不限于 Java、C、C++、Python、Ruby、JavaScript 等。每种语言都有相应的 MessagePack 库,用于实现序列化和反序列化的功能。
-
性能优化:
由于使用了紧凑的二进制编码和变长编码,MessagePack 具有出色的性能和较小的数据大小。这使得它在高性能的数据传输和存储场景中表现出色。
-
扩展性:
MessagePack 具有一定的扩展性,允许用户通过添加自定义的类型扩展其功能。这可以通过定义新的数据类型以及相应的编码规则来实现。
MessagePack 是一种高效的二进制序列化格式,通过二进制编码、紧凑的数据格式和变长编码等原理,实现了高性能的数据序列化和反序列化。它适用于需要快速、高效数据传输和存储的分布式系统和网络通信场景。
以下是一个使用 Msgpack 序列化库的示例代码:
首先,确保在 pom.xml 文件中添加 Msgpack 的依赖配置,如下所示:
<dependency><groupId>org.msgpack</groupId><artifactId>msgpack-core</artifactId><version>0.9.2</version>
</dependency>
接下来,我们来编写示例代码:
import org.msgpack.core.MessagePack;
import org.msgpack.core.MessagePacker;
import org.msgpack.core.MessageUnpacker;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;public class MsgpackSerializationExample {public static void main(String[] args) throws IOException {// 创建一个 Map 对象作为示例数据Map<String, Object> data = new HashMap<>();data.put("name", "Alice");data.put("age", 30);// 序列化数据为字节数组ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();MessagePacker packer = MessagePack.newDefaultPacker(byteArrayOutputStream);packer.packMapHeader(data.size());for (Map.Entry<String, Object> entry : data.entrySet()) {packer.packString(entry.getKey());packer.packString(entry.getValue().toString());}packer.close();byte[] serializedData = byteArrayOutputStream.toByteArray();// 反序列化字节数组为数据ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(byteArrayInputStream);int mapSize = unpacker.unpackMapHeader();for (int i = 0; i < mapSize; i++) {String key = unpacker.unpackString();String value = unpacker.unpackString();System.out.println(key + ": " + value);}unpacker.close();}
}
十、Thrift
Apache Thrift 是一种跨语言的服务框架,用于构建高效、可扩展、跨语言的服务通信和数据序列化系统。它支持多种编程语言,并提供了自动生成的代码,用于在不同语言之间进行数据传输和远程调用。以下是 Apache Thrift 的原理讲解:
-
IDL(接口描述语言):
Thrift 使用一种称为接口描述语言(IDL)的语法来定义数据结构和服务接口。IDL 描述了数据类型、数据结构、接口和方法,以及它们之间的关系。IDL 文件充当了服务和数据模型的合同,用于生成不同编程语言的代码。 -
代码生成:
基于定义的接口和数据结构,Thrift 提供代码生成工具,将 IDL 文件转换为各种编程语言的类和接口。这些生成的类和接口用于处理数据序列化和远程调用,使不同语言的应用程序能够进行通信。 -
二进制协议:
Thrift 使用二进制协议进行数据传输和序列化。它将数据序列化为紧凑的二进制格式,然后通过网络进行传输。这种二进制协议比文本格式更高效,适用于高性能的数据交换。 -
序列化和反序列化:
Thrift 提供了序列化和反序列化的功能,用于将数据转换为字节流以及将字节流还原为数据对象。序列化器将数据结构转换为二进制数据,反序列化器则将二进制数据还原为原始数据结构。 -
RPC(远程过程调用):
Thrift 具有强大的远程调用功能,允许客户端调用远程服务器上的方法,就像调用本地方法一样。客户端生成对应的请求对象,序列化为二进制格式,然后通过网络发送给服务器。服务器接收请求,反序列化为请求对象,执行相应的方法,最后将结果序列化返回给客户端。 -
多语言支持:
Thrift 支持多种编程语言,包括但不限于 Java、C++、Python、Ruby、Go、C# 等。生成的代码使不同语言的应用程序可以互相调用和交互。 -
版本兼容性:
Thrift 支持版本兼容性,允许在不同版本之间进行调用。新版本的接口和数据结构可以扩展或修改旧版本的接口,从而实现向前和向后的兼容性。 -
数据类型映射:
Thrift 将不同编程语言的数据类型映射到通用的数据类型,以确保在跨语言调用时数据类型的一致性。
Apache Thrift 是一种跨语言的服务框架,通过IDL、代码生成、二进制协议、序列化和远程调用等原理,实现了高效、可扩展的服务通信和数据序列化。它适用于构建分布式系统、跨语言应用和高性能的服务通信场景。
以下是一个使用 Apache Thrift 的示例代码,演示如何定义、序列化和反序列化一个简单的数据结构。
首先,确保在 pom.xml 文件中添加 Thrift 的依赖配置,如下所示:
<dependency><groupId>org.apache.thrift</groupId><artifactId>libthrift</artifactId><version>0.15.0</version>
</dependency>
接下来,我们来编写示例代码,首先是 Thrift 定义文件 Person.thrift,用于定义数据结构:
namespace java tutorialstruct Person {1: required string name;2: required i32 age;
}
然后,使用 Thrift 编译器生成 Java 代码:
thrift --gen java Person.thrift
接下来,我们可以编写示例代码来使用生成的 Thrift 类和对象:
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.transport.TIOStreamTransport;
import org.apache.thrift.transport.TMemoryBuffer;
import tutorial.Person;import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;public class ThriftSerializationExample {public static void main(String[] args) throws TException {// 创建一个 Person 对象Person person = new Person();person.setName("Alice");person.setAge(30);// 将 Person 对象序列化为字节数组TMemoryBuffer memoryBuffer = new TMemoryBuffer(1024);TIOStreamTransport transport = new TIOStreamTransport(memoryBuffer);TBinaryProtocol protocol = new TBinaryProtocol(transport);person.write(protocol);byte[] serializedData = memoryBuffer.getArray();// 将字节数组反序列化为 Person 对象ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(serializedData);TIOStreamTransport inputStreamTransport = new TIOStreamTransport(byteArrayInputStream);TBinaryProtocol inputProtocol = new TBinaryProtocol(inputStreamTransport);Person deserializedPerson = new Person();deserializedPerson.read(inputProtocol);// 打印反序列化后的对象System.out.println("Original Person: " + person);System.out.println("Deserialized Person: " + deserializedPerson);}
}
十一、Xerial Snappy
Xerial Snappy 是一个高速压缩/解压缩库,旨在提供快速的数据压缩和解压缩功能。它基于 Google 的 Snappy 压缩算法,并进行了优化,适用于多种编程语言。以下是 Xerial Snappy 的原理讲解:
-
Snappy 压缩算法:
Xerial Snappy 基于 Snappy 压缩算法,这是由 Google 开发的一种快速压缩算法。Snappy 的特点是压缩和解压缩速度非常快,适用于需要高性能压缩的场景。它主要采用哈希表、变长编码和无损压缩等技术来实现数据的压缩。 -
无损压缩:
Snappy 是一种无损压缩算法,这意味着压缩后的数据可以完全还原为原始数据,而不会损失任何信息。这使得 Snappy 在需要确保数据准确性的情况下非常有用。 -
数据块划分:
Snappy 将输入数据划分为多个数据块,每个数据块都可以独立地进行压缩和解压缩。这种数据块划分方式有助于并行压缩和解压缩,提高了处理大数据流的效率。 -
压缩字典:
Snappy 使用一个压缩字典来存储重复出现的字节序列,以便更有效地压缩数据。压缩字典包含了一组常见的字节序列,当发现相同的字节序列时,可以使用压缩字典中的索引来表示,从而减小压缩后的数据大小。 -
高性能特性:
Xerial Snappy 对 Snappy 压缩算法进行了优化,使其在压缩和解压缩速度上更加高效。这使得它适用于需要高性能数据压缩和解压缩的场景,如大规模数据处理和存储。 -
跨语言支持:
Xerial Snappy 支持多种编程语言,包括但不限于 Java、C、C++、Python、Go 等。它为这些语言提供了相应的库和接口,使开发人员可以轻松地在不同语言中使用 Snappy 压缩和解压缩功能。
Xerial Snappy 是一个基于 Snappy 压缩算法的高速压缩/解压缩库,通过数据块划分、压缩字典和优化等原理,实现了快速的数据压缩和解压缩。它适用于各种需要高性能数据压缩和解压缩的应用场景。
以下是一个使用 Xerial Snappy 的示例代码:
首先,确保在 pom.xml 文件中添加 Xerial Snappy 的依赖配置,如下所示:
<dependency><groupId>org.xerial.snappy</groupId><artifactId>snappy-java</artifactId><version>1.1.10.3</version>
</dependency>
接下来,我们来编写示例代码:
import org.xerial.snappy.Snappy;import java.io.IOException;public class SnappyCompressionExample {public static void main(String[] args) throws IOException {// 原始数据String originalData = "Hello, this is a test for Snappy compression.";// 使用 Snappy 压缩数据byte[] compressedData = Snappy.compress(originalData.getBytes());// 使用 Snappy 解压缩数据byte[] decompressedData = Snappy.uncompress(compressedData);// 打印原始数据和解压缩后的数据System.out.println("Original Data: " + originalData);System.out.println("Compressed Data: " + new String(compressedData));System.out.println("Decompressed Data: " + new String(decompressedData));}
}
十二、Javolution
Javolution 是一个专注于性能和实时系统的 Java 库,旨在提供高性能的数据结构和算法,以满足实时和低延迟的需求。它通过优化数据访问和内存布局等方式,提供了比标准 Java 库更高效的数据处理能力。以下是 Javolution 的一些原理讲解:
-
内存分配和对象池:
Javolution 使用自己的内存分配和对象池机制,以避免标准 Java 内存管理的开销。它使用直接内存分配和对象池来减少垃圾回收的影响,从而降低延迟并提高性能。 -
特定数据结构的优化:
Javolution 提供了一些特定的数据结构,如快速集合、并发数据结构等,这些数据结构经过了优化,具有更高的性能和更低的内存消耗。 -
紧凑的内存布局:
Javolution 采用紧凑的内存布局,通过减少对象头部的开销和对齐数据,使得数据在内存中的存储更加紧凑。这有助于提高数据的缓存命中率,从而加速数据访问。 -
无装箱/拆箱:
Javolution 避免了装箱和拆箱操作,这是标准 Java 中常见的性能瓶颈之一。它使用原始数据类型来存储数据,避免了装箱操作带来的额外开销。 -
基于模板的编程:
Javolution 使用基于模板的编程技术,允许在编译时进行更多的优化。通过生成特定类型的代码,可以针对不同数据类型和需求进行优化,从而提高性能。 -
低延迟设计:
Javolution 的设计目标之一是实现低延迟。它通过减少内存分配、垃圾回收和不必要的同步操作,以及优化数据结构和算法,来实现更低的延迟。 -
并发支持:
Javolution 提供了一些并发数据结构和工具,用于构建高性能的并发系统。这些数据结构和工具经过优化,能够在并发环境下提供高效的数据访问和操作。 -
跨平台支持:
Javolution 支持多个平台,包括 Java SE、Java EE、Android 等,使得开发人员可以在不同平台上享受高性能的数据处理能力。
Javolution 是一个专注于性能和实时系统的 Java 库,通过内存分配、对象池、紧凑的内存布局、无装箱/拆箱、基于模板的编程等原理,提供了高性能的数据结构和算法,适用于需要实时、低延迟的应用场景。
以下是一个使用 Javolution 的示例代码,演示如何使用其数据结构和特性:
首先,确保在 pom.xml 文件中添加 Javolution 的依赖配置,如下所示:
<dependency><groupId>javolution</groupId><artifactId>javolution</artifactId><version>5.4.4</version>
</dependency>
接下来,我们来编写示例代码,展示如何使用 Javolution 的 FastMap 数据结构:
import javolution.util.FastMap;import java.util.Map;public class JavolutionExample {public static void main(String[] args) {// 创建一个 FastMap 对象FastMap<String, Integer> fastMap = new FastMap<>();// 向 FastMap 中添加键值对fastMap.put("one", 1);fastMap.put("two", 2);fastMap.put("three", 3);// 从 FastMap 中获取值int value = fastMap.get("two");System.out.println("Value for key 'two': " + value);// 打印 FastMap 中的所有键值对System.out.println("FastMap contents:");for (Map.Entry<String, Integer> entry : fastMap.entrySet()) {System.out.println(entry.getKey() + " -> " + entry.getValue());}}
}
十三、KyroNet
KryoNet 是一个 Java 网络库,用于构建网络应用程序,特别是多人在线游戏和实时应用。它基于 Kryo 序列化框架,并提供了网络通信的抽象和功能,使开发人员能够轻松地创建高性能的网络应用。以下是 KryoNet 的原理讲解:
-
网络通信模型:
KryoNet 使用基于 NIO(非阻塞 I/O)的网络通信模型。它通过通道(Channel)和选择器(Selector)来实现非阻塞的网络通信,从而支持并发处理多个连接。 -
序列化和反序列化:
KryoNet 使用 Kryo 序列化框架来处理数据的序列化和反序列化。在网络通信中,需要将数据从 Java 对象转换为字节流进行传输,然后再从字节流转换回 Java 对象。Kryo 提供了高性能的序列化和反序列化功能,使数据的传输更加高效。 -
自定义协议:
KryoNet 允许开发人员定义自己的网络通信协议。通过继承 KryoNet 提供的类和接口,开发人员可以定义消息的格式、数据结构、字段等,从而实现自定义的通信协议。 -
事件驱动模型:
KryoNet 使用事件驱动的模型来处理网络消息。当有数据到达时,KryoNet 将触发相应的事件,开发人员可以注册事件处理器来处理这些事件。这种模型使得网络应用程序能够并发处理多个连接和消息。 -
线程模型:
KryoNet 使用线程池来处理网络事件。每个连接都会被分配一个线程来处理数据的读取、写入和事件处理。这种线程模型能够有效地管理多个连接,同时保证高性能和低延迟。 -
可靠性和顺序性:
KryoNet 提供了一些机制来确保数据的可靠性和顺序性。它支持 TCP 连接,这意味着数据会按照发送的顺序进行传输,并且会进行重传以确保数据的可靠性。 -
跨平台支持:
KryoNet 支持多个平台,包括 Java SE、Java EE 等。这使得开发人员可以在不同的平台上构建网络应用程序。
KryoNet 是一个基于 Kryo 序列化框架的网络库,通过 NIO 的网络通信模型、自定义协议、事件驱动模型和线程模型等原理,提供了高性能、可靠的网络通信功能,适用于构建实时性要求较高的多人在线游戏和实时应用。
以下是一个使用 KryoNet 的示例代码,演示如何创建一个简单的客户端和服务器,并进行数据通信:
首先,确保在 pom.xml 文件中添加 KryoNet 的依赖配置,如下所示:
<dependency><groupId>kryonet</groupId><artifactId>kryonet</artifactId><version>2.21</version></dependency>
接下来,我们来编写示例代码,创建一个简单的客户端和服务器:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryonet.Client;
import com.esotericsoftware.kryonet.Connection;
import com.esotericsoftware.kryonet.Listener;
import com.esotericsoftware.kryonet.Server;import java.io.IOException;class MyMessage {String text;
}public class KryoNetExample {public static void main(String[] args) {// 创建服务器Server server = new Server();Kryo kryoServer = server.getKryo();kryoServer.register(MyMessage.class); // 注册 MyMessage 类try {server.bind(54555);} catch (IOException e) {throw new RuntimeException(e);}server.start();// 添加服务器监听器server.addListener(new Listener() {public void received(Connection connection, Object object) {if (object instanceof MyMessage) {MyMessage message = (MyMessage) object;System.out.println("Server received: " + message.text);// 向客户端发送响应消息MyMessage response = new MyMessage();response.text = "Hello from server!";connection.sendTCP(response);}}});// 创建客户端Client client = new Client();Kryo kryoClient = client.getKryo();kryoClient.register(MyMessage.class); // 注册 MyMessage 类client.start();try {client.connect(5000, "localhost", 54555);} catch (IOException e) {throw new RuntimeException(e);}// 向服务器发送消息MyMessage message = new MyMessage();message.text = "Hello from client!";client.sendTCP(message);// 添加客户端监听器client.addListener(new Listener() {public void received(Connection connection, Object object) {if (object instanceof MyMessage) {MyMessage response = (MyMessage) object;System.out.println("Client received: " + response.text);}}});}
}十四、结束语
在上面文章中我们分别对java常用的序列话框架进行收集及示例代码编写讲解,希望可以帮助大家。至于在开发过程中使用那个框架,可以根据实际情况进行选择。