面包屑

创建一个面包屑组件
将路由导入然后格式化map对象 key-value
将当前路由的key和value获取然后存入list数组中
遍历list数据,渲染内容
<!--BreadcrumbCom.vue-->
<template><el-breadcrumb separator=">"><el-breadcrumb-item v-for="item in list" :key="item.name" :to="{ name: item.name }">{{ item.label }}</el-breadcrumb-item></el-breadcrumb></template><script>
import { routes } from '@/router';
export default{data(){//用来记录所有路由对应的labelthis.routesMap = new Map()//用来将路由处理成mapthis.initRoutesMap(routes)return{list:[],}},mounted(){},methods:{initRoutesMap(routes){routes.forEach(route => {this.routesMap.set(route.name, route.label)//如果有子路由if(route.children){this.initRoutesMap(route.children)}});}},watch:{$route:{immediate:true,handler(route){//处理路径this.list = route.matched.map(item=>{return {name:item.name,label:this.routesMap.get(item.name)}})}}}
}
</script><style lang="scss" scoped>
.el-breadcrumb {margin-bottom: 20px;
}
</style>动态菜单
在store/index.js中创建全局变量记录当前路由路径,并创建修改方法
//记录当前路由路径
currentPath:'/'//修改路由路径的方法
updateCurrentPath(state, value){state.currentPath = value
} 在AsideCom.vue中加载菜单
<template><el-menu default-active="currentPath" :collapse="collapse" router class="el-menu-vertical-demo"><el-menu-item index="/">首页</el-menu-item><el-sub-menu v-for="item in userInfo.checkedkeys" :key="item.path" :index="item.path"><template #title><el-icon><Avatar /></el-icon><span>{{ item.label }}</span></template><el-menu-item v-for="child in item.children" :key="child.path" :index="`/${item.path}/${child.path}`">{{ child.label }}</el-menu-item></el-sub-menu><!-- <el-sub-menu index="/manager"><template #title><el-icon><Avatar /></el-icon><span>账号管理</span></template><el-menu-item index="/manager/managerlist">管理员列表</el-menu-item><el-menu-item index="/manager/userlist">用户列表</el-menu-item></el-sub-menu> <el-sub-menu index="/banner"><template #title><el-icon><Avatar /></el-icon><span>轮播图管理</span></template><el-menu-item index="/banner/bannerlist">轮播图列表</el-menu-item><el-menu-item index="/banner/addbanner">添加轮播图</el-menu-item></el-sub-menu> --></el-menu>
</template><script>
import { Avatar } from '@element-plus/icons-vue';
import { mapState } from 'vuex'; export default{data(){return{}},computed:{...mapState(['currentPath','userInfo'])},components:{Avatar,},props:['collapse']}
</script>轮播图管理
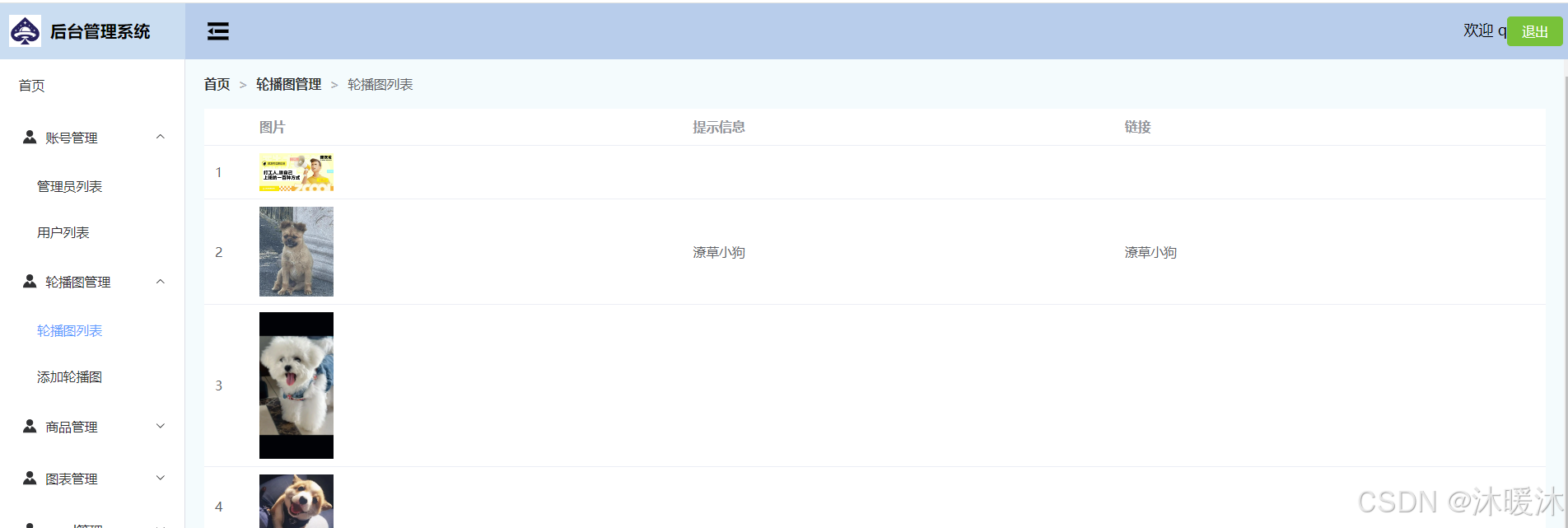
获取轮播图数据
//导入封装的axios
import ajax from "@/utils/axios";//获取轮播图列表
export function bannerList(){return ajax({method:'GET',url:'banner/list'})
}//添加轮播图
export function addBanner(params){return ajax({method:'POST',url:'banner/add',data:params})
}创建轮播图页面
<!--BannerListView.vue-->
<template><div><el-table :data="bannerList" ><el-table-column type="index"></el-table-column><el-table-column prop="img" label="图片"><template #default="scope"><div style="display: flex;align-items: center;"><el-image :src="scope.row.img"></el-image></div></template></el-table-column><el-table-column prop="alt" label="提示信息"></el-table-column><el-table-column prop="link" label="链接"></el-table-column></el-table></div></template><script>
import { bannerList } from '@/api/banner';export default{data(){return {bannerList:[]}},mounted(){bannerList().then(res=>{this.bannerList=res.data})}
}
</script><style lang="scss" scoped>
.el-image{width: 80px;
}
</style>添加轮播图
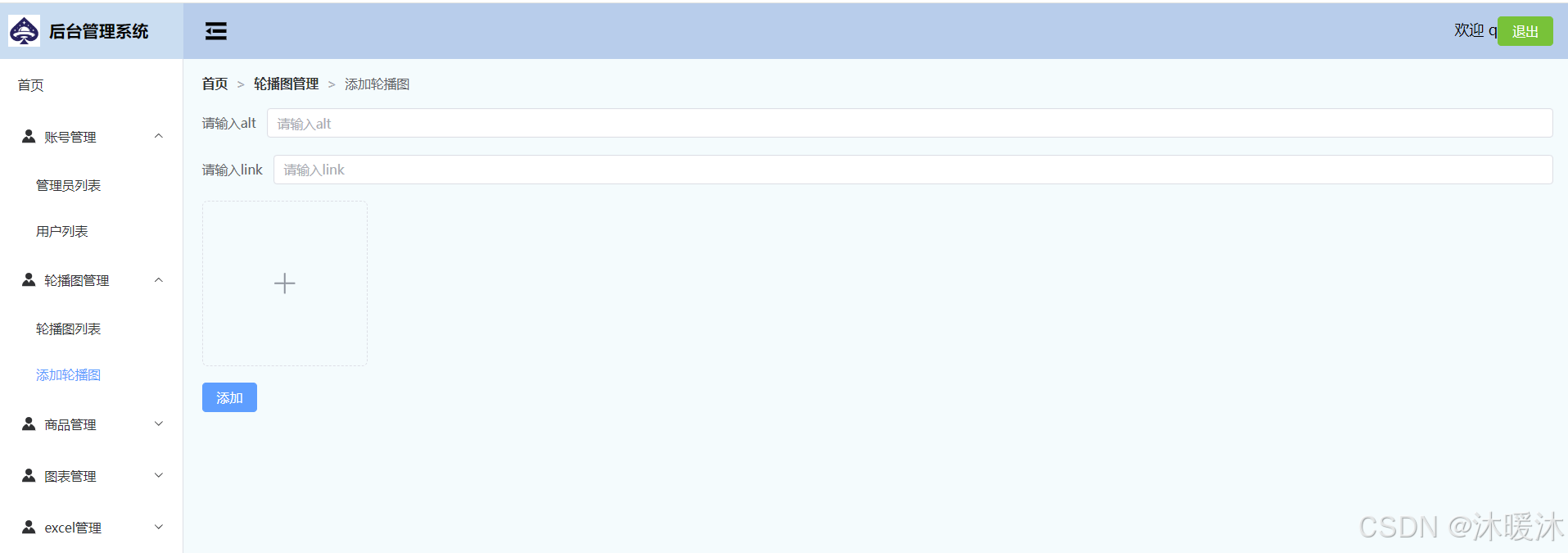
<!--AddBannerView.vue-->
<template><div><el-form><el-form-item label="请输入alt"><el-input v-model="formData.alt" placeholder="请输入alt"/></el-form-item><el-form-item label="请输入link"><el-input v-model="formData.link" placeholder="请输入link"/></el-form-item><el-form-item><el-uploadclass="avatar-uploader":http-request="httpRequest":show-file-list="false"><img v-if="imageUrl" :src="imageUrl" class="avatar" /><el-icon v-else class="avatar-uploader-icon"><Plus /></el-icon></el-upload></el-form-item><el-button @click="addBanner" type="primary">添加</el-button></el-form></div>
</template><script>
import { addBanner } from '@/api/banner';
import { Plus } from '@element-plus/icons-vue';
import { ElMessage } from 'element-plus';export default{data(){return {imageUrl:'',formData:{alt:'',link:'',img:''}}},components:{Plus},methods:{httpRequest(data){//根据文件生成一个url地址,该地址用于临时展示的//this.imageUrl = URL.createObjectURL(data.file)//1、获取用户选择的图片//2、将图片上传到存放图片的服务器,该服务器会返给图片地址//3、将图片地址发送给后端存储//创建一个文件加载器let reader = new FileReader()//指定其加载开始加载文件reader.readAsDataURL(data.file)//加载完成后的回调函数reader.onload=()=>{this.imageUrl = reader.result; //图片的base64this.formData.img = reader.result;}},addBanner(){addBanner(this.formData).then(res=>{if(res.code=='200'){ElMessage.success(res.message)//提交成功后进入轮播图列表查看this.$router.push('/banner/bannerlist')}else{ElMessage.error(res.message)}})}}
}</script>
<style>
.avatar-uploader .el-upload {border: 1px dashed var(--el-border-color);border-radius: 6px;cursor: pointer;position: relative;overflow: hidden;transition: var(--el-transition-duration-fast);
}.avatar-uploader .el-upload:hover {border-color: var(--el-color-primary);
}.el-icon.avatar-uploader-icon {font-size: 28px;color: #8c939d;width: 178px;height: 178px;text-align: center;
}
</style><style lang="scss" scoped>
.avatar-uploader .avatar {width: 178px;height: 178px;display: block;
}
</style>
图表管理echarts
官网:Apache ECharts
安装echarts
npm install echarts导入图表
将图表绑定在指定元素上
设置一个option
<template><div><el-button @click="changeType('line')">折线图</el-button><el-button @click="changeType('bar')" type="primary">柱状图</el-button><el-button @click="changeType('pie')" type="success">饼图</el-button><el-button @click="changeType('scatter')" type="info">散点图</el-button><el-button @click="changeType('line',['冰箱','空调','电视机','电磁炉'],['100','180','200','160'])" type="warning">电器销量</el-button><el-button @click="changeType('bar',['草莓','香蕉','西瓜','樱桃','甘蔗','橘子','橙子'],['200','111','222','333','210','123','20'])" type="danger">水果销量</el-button></div><div id="main"></div>
</template><script>
import * as echarts from 'echarts';export default{data(){return {mychart: null}},methods:{changeType(type,x,y){// 绘制图表this.myChart.setOption({title: {text: 'ECharts 入门示例'},tooltip: {},toolbox: {feature: {saveAsImage: {}}},xAxis: {data: x || ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子']},yAxis: {},series: [{name: '销量',type: type||'bar',data: y || [5, 20, 36, 10, 10, 20]}]});}},mounted(){// 基于准备好的dom,初始化echarts实例this.myChart = echarts.init(document.getElementById('main'));this.changeType('bar')}
}</script><style lang="scss" scoped>
#main{height: 600px;background-color: white;
}
</style>文件导入 excel
安装
npm install xlsx选择文件
将文件读成数据流
将数据流读为对象
将对象中的工作表内容读取出来
将读取的内容转为json
数据渲染
<template><div><el-button type="success" @click="importClick">选择文件</el-button><input ref="inp" hidden type="file" @change="importChange"/><el-table :data="computedTableData" ><el-table-column type="index" :index="(currentPage-1)*10+1" label="序号" width="80" /><el-table-column prop="nickname" label="昵称"></el-table-column><el-table-column label="性别"><template #default="scope"><span>{{ scope.row.sex == -1?'女':'男' }}</span></template></el-table-column><el-table-column prop="tel" label="联系电话"></el-table-column></el-table><!-- 分页显示 --><el-pagination background v-model:current-page="currentPage" layout="prev, pager, next" :total="userList.length" /></div>
</template><script>
import * as XLSX from 'xlsx'export default{data(){return {userList:[],currentPage: 1}},methods:{importClick(){//选择文件按钮的点击事件this.$refs.inp.click()},importChange(event){//选中文件后的回调函数//console.log(event.target.files[0])//获取选中的文件const file = event.target.files[0];//创建文件的加载器const reader = new FileReader();//将文件读取成数据流reader.readAsBinaryString(file);reader.onload = () => {//将文件转换成js对象const boxx = XLSX.read(reader.result,{type:'binary'})//将工作表1中的数据提取出来let res = boxx.Sheets['工作表1'];//将工作表1中的数据转换成jsonres = XLSX.utils.sheet_to_json(res);this.userList = res;}}},mounted(){},computed:{//计算当前页显示的数据computedTableData(){return this.userList.slice((this.currentPage-1)*10,(this.currentPage-1)*10+10);}}
}
</script>文件导出 excel
使用文档:js-export-excel - npm
安装
npm install js-export-excel1、导入使用函数
2、创建导出对象
3、定义导出内容
4、实现具体导出
<template><div><!-- 文件导出有两种方式:1)直接使用a标签 --><!-- <a href="https://code.jquery.com/jquery-3.6.2.min.js" download=""></a> --><!-- 2)自己将数据处理后本地保存 --><el-button @click="exportClick">文件导出</el-button><el-table :data="computedTableData" ><el-table-column type="index" :index="(currentPage-1)*10+1" label="序号" width="80" /><el-table-column prop="nickname" label="昵称"></el-table-column><el-table-column label="性别"><template #default="scope"><span>{{ scope.row.sex == -1?'女':'男' }}</span></template></el-table-column><el-table-column prop="tel" label="联系电话"></el-table-column></el-table><!-- 分页显示 --><el-pagination background v-model:current-page="currentPage" layout="prev, pager, next" :total="userList.length" /></div>
</template><script>
import { userList } from '@/api/user';
//1、导入使用函数
import ExportJsonExcel from 'js-export-excel';
export default{data(){return {userList:[],currentPage: 1}},mounted(){userList().then(res=>{this.userList = res.data;})},methods:{exportClick(){//2、创建导出对象let option= {}//导出文件名字option.fileName = 'userList'//导出内容option.datas = [{//需要导出的数据sheetData:this.userList,//工作表名称sheetName: "工作表1",sheetFilter: ["nickname", "sex", "tel"],sheetHeader: ["昵称", "性别", "联系电话"],columnWidths: [20, 20],}];//实现具体导出var toExcel = new ExportJsonExcel(option); //newtoExcel.saveExcel(); //保存}},computed:{//计算当前页显示的数据computedTableData(){return this.userList.slice((this.currentPage-1)*10,(this.currentPage-1)*10+10);}}
}
</script>富文本编辑器
官方文档:TinyMCE 7 Documentation | TinyMCE Documentation
安装:
npm install @tinymce/tinymce-vue tinymce
或npm install --save tinymce "@tinymce/tinymce-vue@^5"使用,需要申请api-key
<template><div><Editor></Editor></div>
</template><script>
import Editor from '@tinymce/tinymce-vue'
export default{data(){return {}},mounted(){},components:{Editor,}
}</script><style lang="scss" scoped></style>