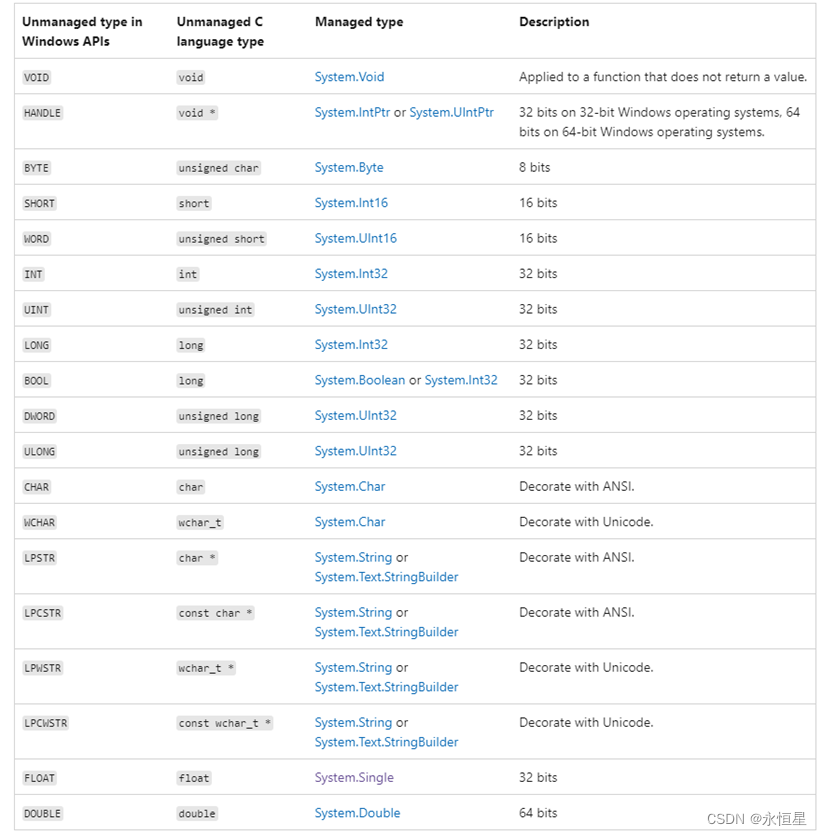
信息系统工程领域对数据安全的要求比较高,MySQL 数据库管理系统普遍应用于各种信息系统应用软件的开发之中,而角色与权限设计不仅关乎数据库中数据保密性的性能高低,也关系到用户使用数据库的最低要求。在对数据库的安全性进行设计时,为了保证数据的安全性和可靠性,提出通过设置角色和权限实现对数据的安全访问,然后通过编写代码进行实验,以验证此方式解决数据库中数据安全问题的有效性。
目录
1 相关概念
1.1 存储过程简介
1.2 游标简介
1.3 处理程序简介
2 综合运用设计
2.1 设计基础表和条件
2.2 分析思路
2.3 代码实现及错误问题分析
2.4 优化后正确代码
3 结 论
在 MySQL 数据库下,存储过程是非常重要的一项内容,但要发挥存储过程的重要作用,必须让存储过程结合游标、处理程序、流程控制语句对数据进行处理,这样既能发挥出游标和处理程序的优势,也能体现流程控制语句在数据库中的应用。利用数据库开发信息系统或开发网站平台时,开发人员会编写大量代码,有些功能是相似的,代码会重复编写,浪费开发人员的时间,也会增加代码的冗余,如果利用存储过程,则可以简化开发人员的工作量,并能减少数据在数据库和应用服务器之间的传输,从而有效提高数据库的处理速度,还可以提高数据库编程的灵活性。
1 相关概念
1.1 存储过程简介
存储过程是一批被编译了的语句的集合,存储在数据库的服务器端,用户仅需要通过指定存储过程名称来执行操作。存储过程具有良好的封装性,被创建之后,可在程序中被多次调用,而不必重新编写该存储过程中的 SQL 语句,后台管理人员可以随时对存储过程进行修改,并不会影响到调用存储过程的应用程序源代码,在存储过程中可以加入流程控制语句,类似具有了 C 语言程序设计的功能,可以解决数据库编程中的复杂问题。
存储过程的优点是可以处理复杂问题,并且能提高执行的性能,因为在服务器端,由于执行完 1 次之后,其执行过程就会存放在缓存中,后面的多次调用执行,仅需要执行缓存中的二进制代码即可,既提高了性能又节约了时间。
1.2 游标简介
游标是用来存储结果集的数据类型,用 SQL 语言从数据库中查询数据后,结果往往是一个含有多条记录的结果集,它放在内存的一块区域中,游标会通过循环结构,允许用户逐行地访问这些记录,按照用户自己的意愿来显示和处理每一条记录。游标不能单独使用,可以在存储过程或函数中使用。使用游标设计程序时,必须有 4 个步骤:声明游标、打开游标、获取数据、关闭游标。声明游标是开辟空间并存储查询结果集,此时游标在第一条记录的前面,打开游标是让游标指向查询结果集的第一条记录,获取数据是从结果集中获取单条记录,获取此条记录后,游标自动指向下一条记录。关闭游标是释放资源,无法再获取数据。
1.3 处理程序简介
处理程序用于解决数据库中的错误,由于错误在执行程序时是不确定的,当有错误出现时,需要通过处理程序解决,从而保证程序正常运行。当数据表中的记录数不确定的时候,如果用游标来获取单行数据,需要利用循环语句实现。由于记录条数不确定,导致循环次数也不确定,此时无法写出退出循环的条件语句,所以需要用事先定义好的处理程序自动处理问题。
2 综合运用设计
2.1 设计基础表和条件
存储过程在处理数据量不同的数据时是无差别的,在此设计问题时,设计的问题并不复杂,但是解决问题都需要用到存储过程、游标、处理程序和流程控制语句,通过简单的问题简述复杂的应用。在此建立两个简单的成绩表 score 和score1,分别包含姓名和分数两列,代码为:
create table score(name char(10),fsh float);
insert into score values('zhaoli',82),('sunyu',50),('liqiang',95);
create table score1(name char(10),fsh float);-- 无记录
具体要求:逐行获取第一个 score 表中的数据,把 score表中的分数大于 80 的记录插入到第二个表 score1 中,并验证代码的正确性。
2.2 分析思路
1)把表中的记录逐行取出,解决此问题需利用游标取出表中的数据,并利用变量进行存储。如果单纯用 select 语句查询数据,仅可以看到所有的查询结果,并且结果集并不能被存储到其他数据表中。
2)利用游标取数据的同时需要定义问题处理程序,当游标获取不到数据的时候对问题进行处理,此时定义处理程序也需要用到变量判定是否发现了问题。
3)由于是逐行获取数据,为了提高程序的可读性和简化代码,需利用流程控制语句中的循环结构,通过循环去匹配游标定位到数据表中的逐行记录。此时一定要考虑循环的次数,避免出现死循环。所有循环结束的判定条件要和定义处理程序进行结合,通过定义处理程序的变量获得退出循环
的条件。
4)为了能够把获取到的数据添加到第二个表中,还需要判定存放到变量中的记录的值是否符合条件,利用条件判断语句解决问题。
5)需要把各个代码段集合成一个整体去执行,需要存储过程解决此问题。
2.3 代码实现及错误问题分析
对于没有经验的初学者而言,通常会按照以上思路直接写出以下代码:
delimiter //
create procedure cc1()-- 第 1 行定义存储过程。
Begin-- 第 2 行和第 16 行是开始和结束的代码段。
declare f float default 0;
declare x char(10);-- 第 3 行和第 4 行定义变量用于存放游标从数据表中取出的每一条记录的两个值。
declare t int default 0;-- 第 5 行用于给定义处理程序的变量赋值为 0。
declare c cursor for select * from score;--第6行为声明游标。
declare continue handler for not found set t=1;-- 第 7 行代表定义处理程序,当不能获取数据的时候,此时设置变量 t为 1,从而控制循环的退出。
open c;-- 第 8 行代表打开游标。
while t<>1 do-- 第 9-13 行代表循环控制语句,通过循环取出数据并进行条件判定,符合条件的存储到 score1 表中。
fetch c into x,f; -- 第 10 行代表获取表中数据
if f>80 then insert into score1 values(x,f);
end if;
end while;
close c;-- 第 14 行关闭游标
select * from score1;-- 第 15 行代表查看存入的数据,以验证代码是否正确。
end//,
通过编译可以看出,代码编译过程无语法错误,提示正确,如图 1 所示。
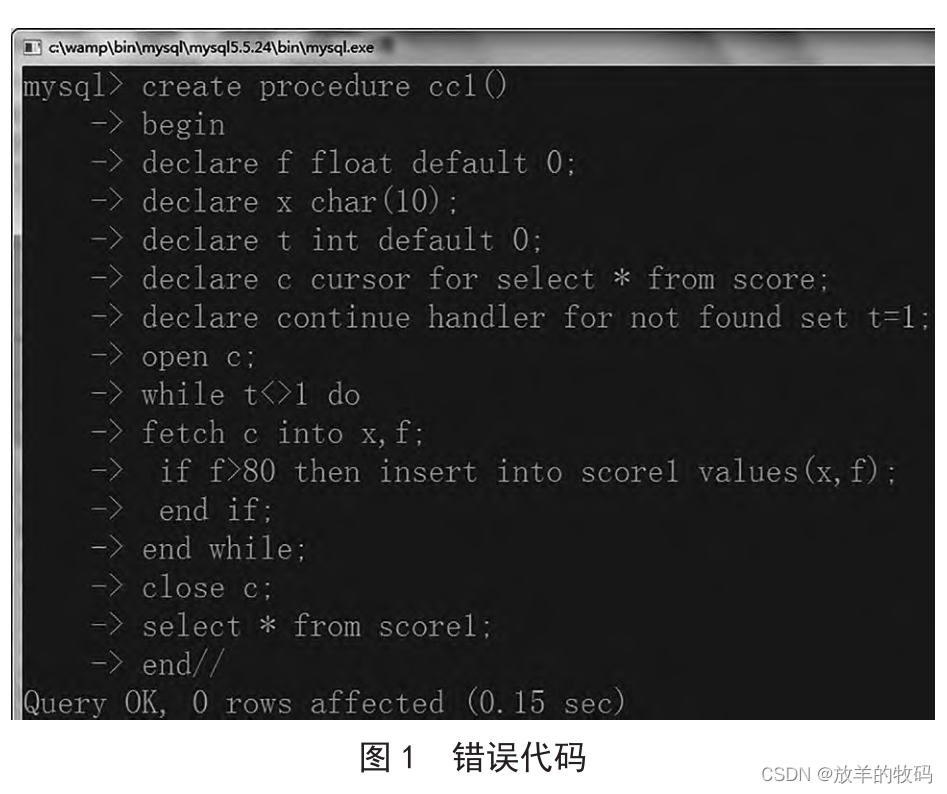
下面执行存储过程,会发现虽然编译正确,但是执行结果是错误的。根据建立数据表时输入的 3 条记录判断,应该有 2 条记录符合条件,但这里显示了 3 条记录,如图 2 所示。

通过以上执行结果发现,score1 表中的最后两行是重复的,正确结果应该不重复,表中应该有两条符合条件的记录,即第 1 条和第 2 条记录。错误原因分析如下:
由于 score 表中有 3 条记录,根据定义的处理程序和循环结构,会循环 4 次去提取数据,每次提取完成之后,会把一条记录中的两个值赋值给变量 x 和 f,在第 4 次循环取数据时,由于没有记录可以获取,此时,变量 t 设置为 1,所以第 4 次并未取到值给变量,但是 x 和 f 的值是保留了第3 次取数据时所赋给的值,并且符合大于 80 的条件,此时又把此条记录加入 score2 表中。又因为定义处理程序时,declare 后面的关键字是 continue,当处理程序发现问题后,程序会继续执行,所以 score2 表中出现了重复的记录。如何解决这个问题,仅需要在提取到数据的第 10 行代码后面加入条件即可。如图 3 所示。
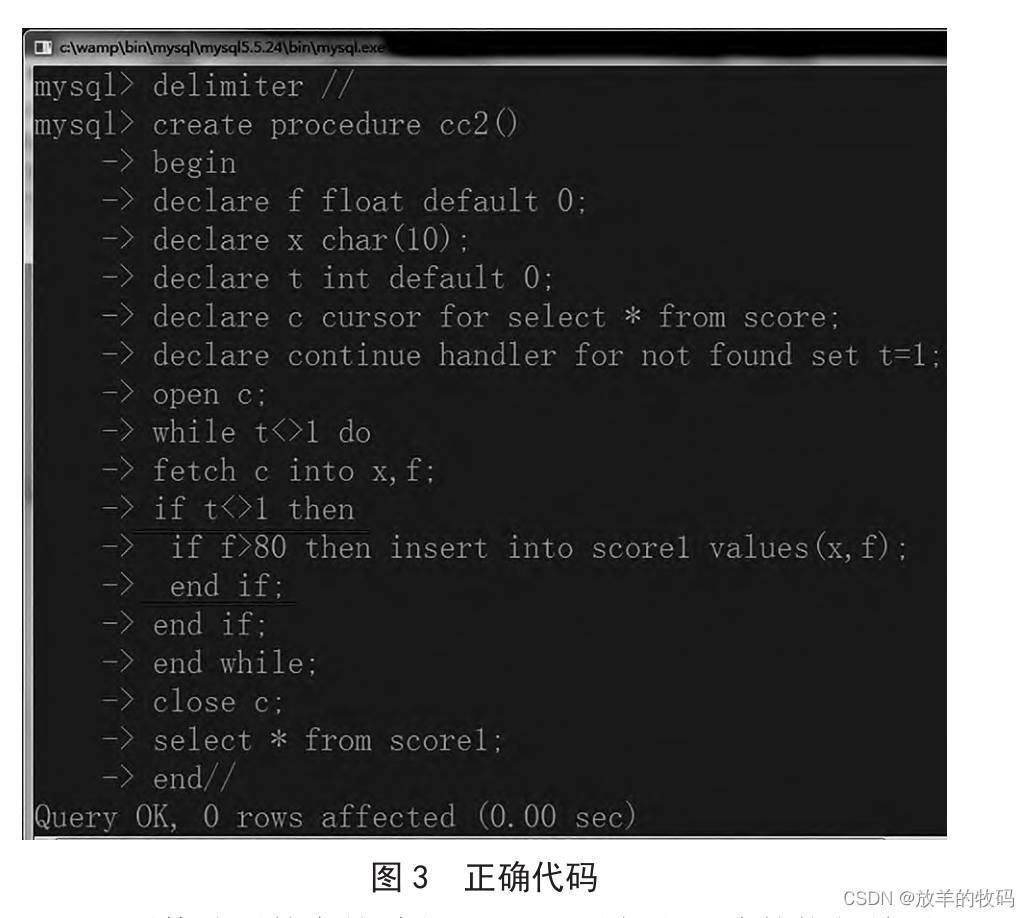
调用修改后的存储过程 cc2,可以得出正确的执行结果,代码和结果如图 4 所示。

2.4 优化后正确代码
针对存储过程、游标、定义处理的应用,以上代码已经是最简洁状态,无法进行优化,但在 while 循环结构中,有两个 if 条件的嵌套,使得代码的行数和可读性减弱,可以在此基础上对代码进行优化,两个 if 条件合并成一个 if 条件。结果不变,但可以提高代码的可读性,如图 5 所示。
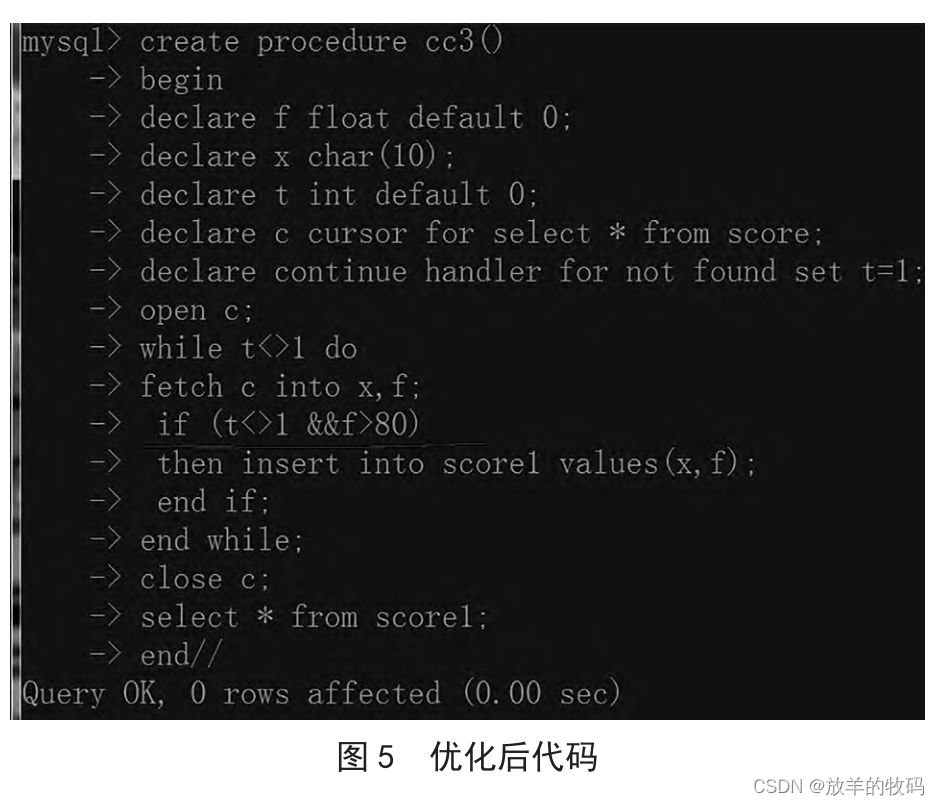
在以上代码中,针对定义处理程序的语法结构,declare参数 1 handler for 参数 2SQL 语句。
参数 1:exit 退出当前程序,continue 继续执行程序。
参数 2:not found 代表当 fetch 抓取不到数据的状态,或者游标指针走到最后一条记录后面的状态。
SQL 语句:set temp=1,temp 是变量,必须提前声明,其值只能是 0(false)或者 1(true)。在上面的代码中,用到的参数为 continue,continue 所代表的含义是当程序出现问题时,定义的处理程序起作用,并且代码继续执行,也可以用 exit 实现,此时代码不再执行,直接跳出存储过程。除此之外,对于循环中的条件和循环而言,也可以用其他循环结构实现,提高代码的灵活性。代码为:
delimiter //
create procedure cc4()
begin
declare f float default 0;
declare x char(10);
declare t int default 0;
declare c cursor for select * from score where fsh>80;-- 把循环结构中的if条件编辑到查询语句中,提升代码的可读性。
declare exit handler for not found set t=1;-- 此处用 exit 代替 continue,当条件成立的时候,退出整个存储过程。
open c;
repeat– 此处用 repeat 循环代替 while 循环。
fetch c into x,f;
insert into score1 values(x,f);
until t=1
end repeat;
close c;
select * from score1;-- 此行可以去掉,因为是 exit,循环截止的时候,直接结束程序运行,不会执行此行代码。
3 结 论
在设计数据库的过程中,需要根据内容选择合适的数据库对象,在选择之后,还要考虑此数据库对象所需要加载的其他内容,例如仅创建一个存储过程很简单,但仅能解决简单问题,遇到复杂问题或者数据表中的数据量特别大的情况,就需要考虑知识的综合运用,运用变量、游标、循环结构、条件结构、处理程序等多项内容,进而解决复杂问题。此方案以简单数据表为例进行描述,可为基于 MySQL 数据库的信息系统或信息平台提供借鉴,以解决实际问题。在后续的研究中,将进一步优化案例设计,选择多个数据表的大数据量展开对比,拟通过此种方式,进一步挖掘综合运用方面的优势,提供更宝贵的经验借鉴。