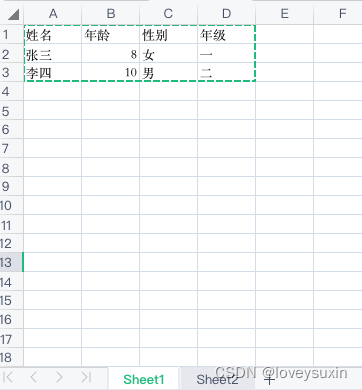
excel文件内容如下:
一、xlrd 读Excel 操作
1、打开Excel文件读取数据
file=xlrd.open_workbook(filename)#文件名以及路径,如果路径或者文件名有中文给前面加一个 r2、常用函数
(1)获取一个sheet工作表
table = file.sheets()[0] #通过索引顺序获取
table = file.sheet_by_index(sheet_indx) #通过索引顺序获取
table = file.sheet_by_name(sheet_name) #通过名称获取# 以上三个函数都会返回一个xlrd.sheet.Sheet()对象names = file.sheet_names() #返回book中所有工作表的名字
file.sheet_loaded(sheet_name or indx) # 检查某个sheet是否导入完毕(2)行操作函数
nrows = table.nrows # 获取该sheet中的行数,注,这里table.nrows后面不带().table.row(rowx) # 返回由该行中所有的单元格对象组成的列表,这与tabel.raw()方法并没有区别。table.row_slice(rowx, start_colx=0, end_colx=None) # 返回由该行中所有的单元格对象组成的列表table.row_types(rowx, start_colx=0, end_colx=None) # 返回由该行中所有单元格的数据类型组成的列表;返回值为逻辑值列表,若类型为empy则为0,否则为1table.row_values(rowx, start_colx=0, end_colx=None) # 返回由该行中所有单元格的数据组成的列表table.row_len(rowx) # 返回该行的有效单元格长度,即这一行有多少个数据
(3)列操作函数
ncols = table.ncols # 获取列表的有效列数table.col(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有的单元格对象组成的列表table.col_slice(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有的单元格对象组成的列表table.col_types(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有单元格的数据类型组成的列表table.col_values(colx, start_rowx=0, end_rowx=None) # 返回由该列中所有单元格的数据组成的列表
(4)单元格操作
table.cell(rowx,colx) # 返回单元格对象table.cell_type(rowx,colx) # 返回对应位置单元格中的数据类型table.cell_value(rowx,colx) # 返回对应位置单元格中的数据3、代码演示
(1) 基本函数用法演示
import os
import xlrdcurrent_path = os.getcwd()
path = os.path.join(current_path, 'test.xlsx')file = xlrd.open_workbook(path)# excel中最重要的方法就是book和sheet的操作
'''(1) 获取book(excel文件)中一个工作表 '''
sheet1 = file.sheets()[0] # 通过索引获取sheet页
sheet1 = file.sheet_by_index(0) # 通过索引获取sheet页
sheet1 = file.sheet_by_name('Sheet1') # 通过名称获取sheet页
print(sheet1, sheet1, sheet1) # 以上三个函数都会返回一个xlrd.sheet.Sheet()对象names = file.sheet_names() # #返回文件中所有工作表的名字
print(names) # ['Sheet1', 'Sheet2']'''(2)行的操作'''
print('-----------行操作----------------')
nrows = sheet1.nrows # 获取该sheet中的行数,注,sheet1.nrows后面不带()
print(nrows) # 3
# 返回由该行中所有的单元格对象组成的列表
print(sheet1.row(2)) # [text:'李四', number:10.0, text:'男', text:'二']
# 返回由该行中切片单元格对象组成的列表(rowx, start_colx=0, end_colx=None)
print(sheet1.row_slice(2, 1, 3)) # [number:10.0, text:'男']
# 返回由该行中所有单元格的数据类型组成的列表,支持开始结束列选择: table.row_types(rowx, start_colx=0, end_colx=None)
print(sheet1.row_types(2)) # array('B', [1, 2, 1, 1])# 返回由该行中所有单元格的数据组成的列表,支持开始结束列选择 table.row_values(rowx, start_colx=0, end_colx=None)
print(sheet1.row_values(2)) # ['李四', 10.0, '男', '二']# 返回该行的有效单元格长度,即这一行有多少个数据
print(sheet1.row_len(2)) # 4'''(3)列操作'''
print('-----------列操作----------------')
ncols = sheet1.ncols # 获取列表的有效列数
print(ncols) # 4print(sheet1.col(0)) # [text:'姓名', text:'张三', text:'李四']
print(sheet1.col_slice(0, 0, 1)) # [text:'姓名']
print(sheet1.col_types(0)) # [1, 1, 1]
print(sheet1.col_values(0)) # ['姓名', '张三', '李四']'''(4)单元格操作'''
print('-----------单元格操作----------------')
print(sheet1.cell(1, 1)) # number:8.0
print(sheet1.cell_type(1, 1)) # 2
print(sheet1.cell_value(1, 1)) # 8.0
输出内容:
<xlrd.sheet.Sheet object at 0x10b7b77c0> <xlrd.sheet.Sheet object at 0x10b7b77c0> <xlrd.sheet.Sheet object at 0x10b7b77c0>
['Sheet1', 'Sheet2']
-----------行操作----------------
3
[text:'李四', number:10.0, text:'男', text:'二']
[number:10.0, text:'男']
array('B', [1, 2, 1, 1])
['李四', 10.0, '男', '二']
4
-----------列操作----------------
4
[text:'姓名', text:'张三', text:'李四']
[text:'姓名']
[1, 1, 1]
['姓名', '张三', '李四']
-----------单元格操作----------------
number:8.0
2
8.0
(2)案例演示
import os
import xlrdcurrent_path = os.getcwd()
path = os.path.join(current_path, 'test.xlsx')xlsx = xlrd.open_workbook(path)# 通过sheet名查找:xlsx.sheet_by_name("sheet1")
# 通过索引查找:xlsx.sheet_by_index(3)
table = xlsx.sheet_by_index(0)# 获取单个表格值 (2,1)表示获取第3行第2列单元格的值
value = table.cell_value(2, 1)
print("第3行2列值为", value)# 获取表格行数
nrows = table.nrows
print("表格一共有", nrows, "行")# 获取第3列所有值(列表生成式)
name_list = [str(table.cell_value(i, 2)) for i in range(1, nrows)]
print("第3列所有的值:", name_list)
输出:
第3行2列值为 10.0
表格一共有 3 行
第3列所有的值: ['女', '男']



![[IDEA]使用idea比较两个jar包的差异](https://img-blog.csdnimg.cn/d10b8b8bad9d4c319d8868ef8bfdbf1f.png)