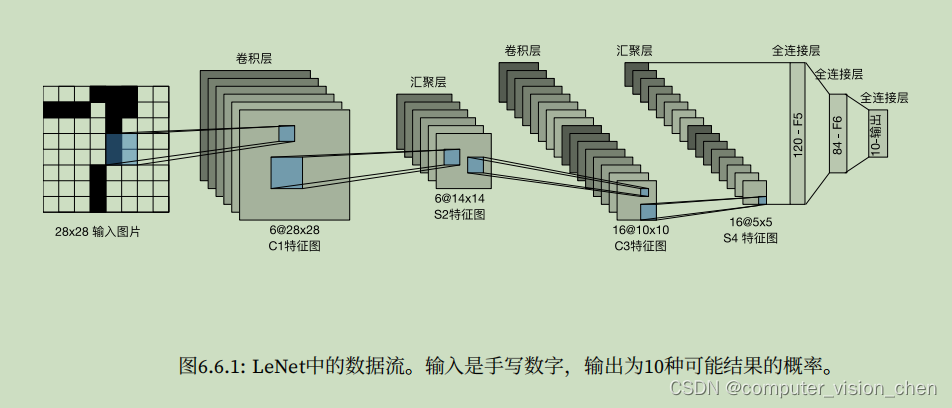
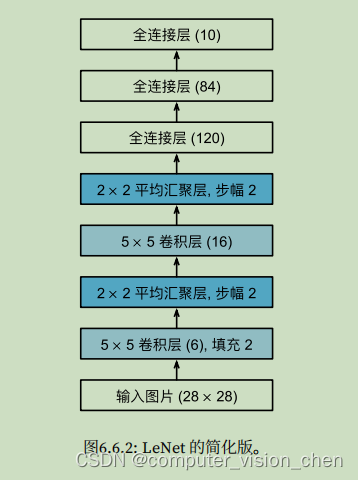
模型架构
代码实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),#padding=2补偿5x5卷积核导致的特征减少。nn.AvgPool2d(kernel_size=2,stride=2),nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(),nn.Linear(16*5*5,120),nn.Sigmoid(),nn.Linear(120,84),nn.Sigmoid(),nn.Linear(84,10)
)
'''定义X,并打印模型的形状'''
# 第一个参数是样本
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)
# 输出如下:
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
'''定义训练批次并加载训练集和测试集'''
batch_size = 256
# 按照batch_size把数据集取出来。取出来之后是放到内存中的,后面要把它加载到GPU中
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 计算预测正确的个数
def accuracy(y_hat,y):'''计算预测正确的数量'''if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:# y_hat是下标表示类别,值是该类别的概率。模型结果是预测10个类的概率,谁的概率最大,就取谁的下标y_hat = y_hat.argmax(axis=1)# y_hat.type(y.dtype):因为==对数据类型很敏感,因此我们将y_hat的数据类型转换为与y的数据类型一致。# y_hat.type(y.dtype) == y,将预测值y_hat与真实值y比较,返回一个包含 0和1的张量,赋值给cam,最后求和会得到正确预测的数量。cam = y_hat.type(y.dtype) == yreturn float(cam.type(y.dtype).sum())
def evaluate_accuracy_gpu(net,data_iter,device=None):if isinstance(net,nn.Module):net.eval() # 将模型设置为评估模式if not device:'''iter(net.parameters())是将参数集合转换为迭代器,并获取其中的第一个元素next(iter(net.parameters())).device ,指取到net.parameters()的第一个元素,获取该元素的设备。'''device = next(iter(net.parameters())).device# Accumulator用于对多个变量进行累加,d2l.Accumulator(2) 是在Accumulator实例中创建了2个变量,分别用于存储正确预测的数量和预测的总数量。当我们遍历数据集时,两者都随着时间的推移而累加。metric = d2l.Accumulator(2) # 正确预测数,预测总数with torch.no_grad():for X,y in data_iter:if isinstance(X,list): # 详见文章最下面的补充内容X = [x.to(device) for x in X] # 令X使用设备deviceelse:X = X.to(device)y = y.to(device)# y.numel()是批次中样本的数量,accuracy(net(X),y)是用于计算模型在输入数据X上的输出结果与标签Y之间的准确率。# metric.add函数将正确预测的数量 和 样本数量作为参数传递进去,用于记录和累计这些指标的值。metric.add(accuracy(net(X),y),y.numel())return metric[0]/metric[1] # 返回准确率,其中metric[0]存放的是正确预测的个数,metric[1]存放的是样本数量,
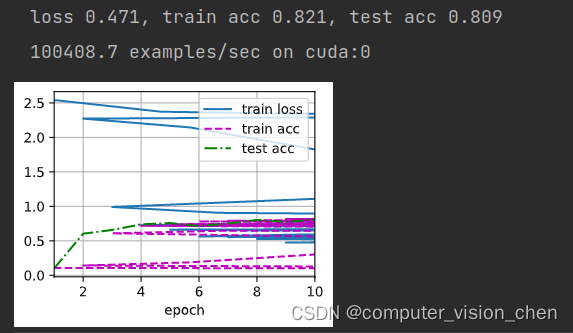
def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d: # 对神经网络中的线性层和卷积层的权重进行初始化nn.init.xavier_uniform_(m.weight) #用于初始化权重的函数,net.apply(init_weights)print('training on',device)net.to(device) # 设置模型使用deviceoptimizer = torch.optim.SGD(net.parameters(),lr=lr)loss = nn.CrossEntropyLoss()'''该代码创建了一个名为animator的动画器,用于在训练过程中可视化损失函数和准确率的变化情况'''animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['train loss','train acc','test acc'])timer,num_batches = d2l.Timer(),len(train_iter)for epoch in range(num_epochs):# 创建 Accumulator类,统计训练损失之和,正确预测个数之和,样本数metric = d2l.Accumulator(3)net.train()for i,(X,y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X,y = X.to(device),y.to(device)y_hat = net(X)l = loss(y_hat,y)l.backward()optimizer.step()with torch.no_grad():metric.add(l*X.shape[0], d2l.accuracy(y_hat,y), X.shape[0])timer.stop()train_l = metric[0] / metric[2] # 损失之和 / 样本数train_acc = metric[1] / metric[2] # 正确预测个数 / 样本数if (i+1) % (num_batches//5)==0 or i == num_epochs-1:animator.add(epoch + (i+1)/num_epochs,(train_l,train_acc,None))test_acc = evaluate_accuracy_gpu(net,test_iter)animator.add(epoch+1,(None,None,test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
# 定义学习率和批次 开始训练
lr,num_epochs = 0.9,10
train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
使用训练好的模型进行预测
y_hat = net(x)
补充:
isinstance(net,nn.Module)
isinstance(net,nn.Module)是Python的内置函数,用于判断一个对象是否属于制定类或其子类的实例。如果net是nn.Module类或子类的实例,那么表达式返回True,否则返回False. nn.Module是pytorch中用于构建神经网络模型的基类,其他神经网络都会继承它,因此使用 isinstance(net,nn.Module),可以确定Net对象是否为一个有效的神经网络模型。
`nn.init.xavier_uniform_(m.weight)
nn.init.xavier_uniform_(m.weight) 是一个用于初始化权重的函数,采用的是 Xavier 均匀分布初始化方法。
在神经网络中,权重的初始化非常重要,合适的初始化可以帮助网络更好地学习和收敛。Xavier 初始化方法是一种常用的权重初始化方法之一,旨在使权重在前向传播过程中保持方差不变。
具体而言,nn.init.xavier_uniform_() 函数会对输入的权重张量 m.weight 进行操作,将其初始化为一个均匀分布中的随机值。这个均匀分布的范围根据权重张量的形状进行调整,以保持前向传播过程中特征的方差稳定。
通过使用 Xavier 初始化方法,可以加速神经网络的训练过程,并且有助于避免梯度消失或梯度爆炸等问题。