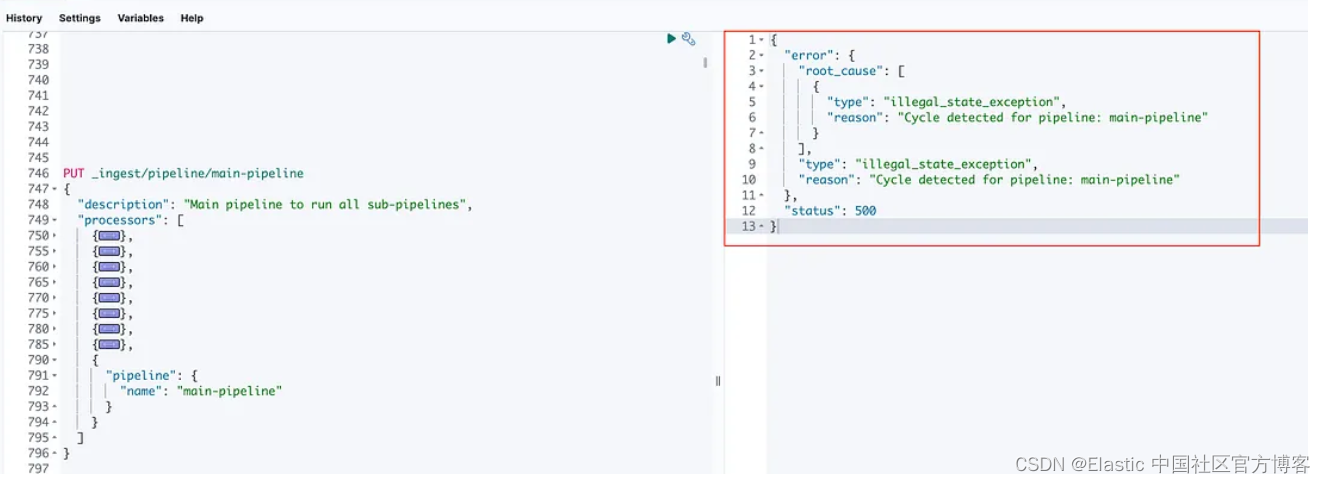
在数据处理和摄取领域,管道在组织和自动化数据从源到目的地的流动方面发挥着至关重要的作用。 管道是数据按顺序通过的一系列处理阶段,每个阶段负责特定任务。 然而,有时,管道可能会遇到一个重大挑战,称为 “Cycle detected for pipeline: main-pipeline.”。 本文旨在解释此错误的含义、原因,并提供示例以更好地理解该概念。
了解 “Cycle detected for pipeline: main-pipeline.” 错误:错误消息 “Cycle detected for pipeline: main-pipeline.” 通常出现在 Elasticsearch 的摄取节点管道的上下文中。 摄取节点管道是在摄取到 Elasticsearch 期间应用于文档的一系列处理步骤。 这些管道用于在数据在数据库中建立索引之前转换和丰富数据。
本文中的 “循环” 是指管道之间的循环依赖关系,其中一个管道直接或间接引用自身。 这种循环引用会产生无限循环,使管道无法完成其处理。 结果,Elasticsearch 检测到此周期并抛出 “Cycle detector for pipeline: main-pipeline” 错误。
管道循环的原因: 管道循环发生的潜在原因有以下几种:
- 不正确的管道定义:如果管道定义包含对同一管道名称的引用,则管道可能会无意中引用自身。
- 递归管道逻辑:一个管道可能以递归方式调用另一个管道,从而导致处理的无限循环。
- 处理器配置错误:如果管道中的处理器无意中调用同一管道,则可能会导致循环。
示例 1:不正确的管道定义
让我们考虑这样一个场景:我们定义了一个名为 “summary-pipeline” 的管道,但我们错误地在管道定义本身内部引用了它:
PUT _ingest/pipeline/summary-pipeline
{"description": "Pipeline to summarize data","processors": [{"pipeline": {"name": "summary-pipeline" // Incorrect reference to itself}},// Other processors...]
}示例 2:递归管道逻辑
假设我们有两个管道,“pipeline-a” 和 “pipeline-b”,其中 “pipeline-a” 引用 “pipeline-b”,反之亦然:
PUT _ingest/pipeline/pipeline-a
{"description": "Pipeline A","processors": [{"pipeline": {"name": "pipeline-b"}},// Other processors...]
}PUT _ingest/pipeline/pipeline-b
{"description": "Pipeline B","processors": [{"pipeline": {"name": "pipeline-a"}},// Other processors...]
}这些示例说明了管道循环如何无意中发生并导致 “Cycle detected for pipeline: main-pipeline” 错误。
解决方案
要解决 “Cycle detected for pipeline: main-pipeline” 错误,仔细检查管道定义并确保管道之间不存在循环引用至关重要。 验证每个管道是否正确调用其他管道而不是引用自身。
结论
摄取节点管道是 Elasticsearch 中数据处理和丰富的强大工具。 然而,在开发管道时,必须避免可能导致管道循环的循环依赖。 “Cycle detected for pipeline: main-pipeline” 错误可能是一个难以诊断的问题,但只要适当注意管道定义和逻辑,就可以避免该错误,从而确保 Elasticsearch 中数据的顺利摄取和处理。



![[国产MCU]-BL602开发实例-定时器](https://img-blog.csdnimg.cn/9492ba0c826d4d9e8a37d5a68282a75b.png#pic_center)