当前,我们正见证着一场技术革命,而 OpenAI 正处于这场变革的最前沿。其中最激动人心的创新之一就是ChatGPT,它运用自然语言处理的力量,打造出更加引人入胜、直观的用户体验。而将 OpenAI 的 API 与物联网设备相结合,更是为我们打开了无限可能。

本文将探索 ChatGPT 与 ESP-BOX 的潜力,这对强大的组合可以将物联网设备提升到一个新的水平。
本文主要分为三个部分,分别介绍本项目的关键内容:
- 第一部分将详细介绍 ESP-BOX,阐述其功能和特点。
- 第二部分为案例研究,描述如何从零开始一步步构建项目。
- 最后一部分为总结,提供了相关资料的来源,便于您巩固和加深对本项目的了解和理解。
ESP-BOX 简介
ESP-BOX 是新一代 AIoT 开发平台,包含 ESP32-S3-BOX 和 ESP32-S3-BOX-Lite 开发板,二者搭载 ESP32-S3 Wi-Fi + Bluetooth 5 (LE) SoC,为开发集成各种传感器、控制器和网关的 AIoT 应用提供了灵活可定制的解决方案。

ESP-BOX 拥有丰富的功能,使其成为理想的 AIoT 开发平台。 接下来将为您介绍其中一些关键功能:
1. 双麦克风远场语音互动
ESP-BOX 支持双麦克风远场语音互动,实现与设备远距离互动。
2. 离线中英文语音指令识别,识别率高
ESP-BOX 提供离线的中英文语音指令识别,具有高识别率,可轻松开发支持语音的设备。
3. 200+ 中英文语音指令可重新配置
开发人员可根据需求轻松配置 200 多个中英文语音指令。
4. 持续识别和唤醒中断
ESP-BOX 支持持续识别和唤醒中断,确保设备始终做好接收语音指令的准备。
5. 灵活可复用的 GUI 框架
ESP-BOX 配备灵活可复用的 GUI 框架,让开发人员可以为应用程序创建个性化的用户界面。
6. 端到端的 AIoT 开发框架 ESP-RainMaker
ESP-BOX 基于端到端的AIoT 开发框架 ESP-RainMaker,为开发人员提供创建强大智能设备所需的工具。
7. 兼容 Pmod™ 接口,支持外设模块扩展
ESP-BOX 具备兼容 Pmod™ 的接口,可轻松扩展设备功能,与各种外设模块互动无障碍。
案例研究
本案例使用 ESP-BOX 和 OpenAI API 开发一款语音控制的聊天机器人 (chatbot)。
介绍
本案例将介绍如何使用 ESP-BOX 和 OpenAI API 开发一款语音控制的聊天机器人。该系统可以接收用户的语音指令,将其展示在屏幕上,并调用 OpenAI API 进行处理,生成相应的回复。回复将显示在 ESP-BOX 屏幕上,然后播放出来。我们将按照下文中的开发流程,逐步深入了解如何巧妙地融合这些技术,打造出高效的语音控制聊天机器人。
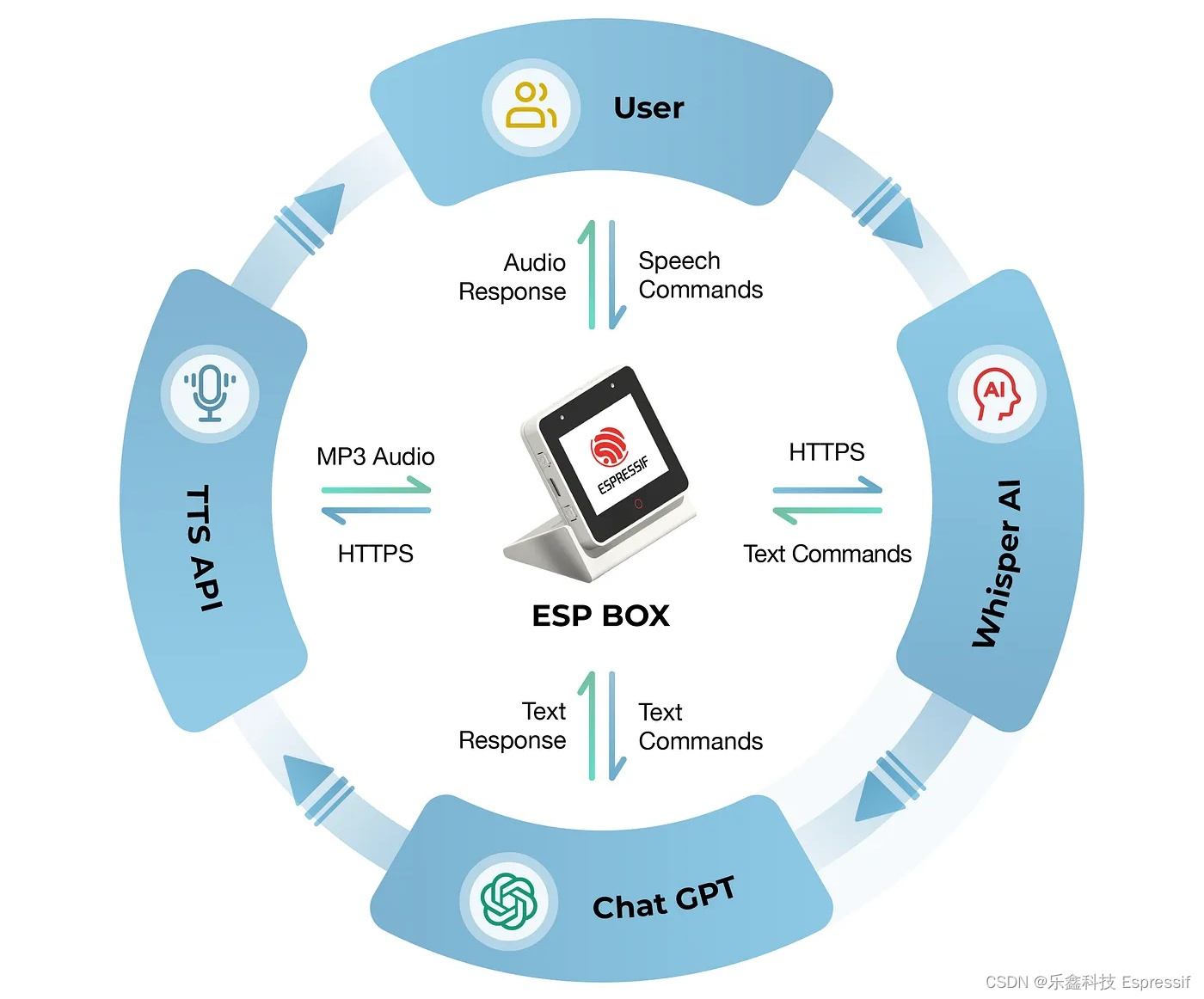
环境设置
为了避免错误,需设置合适的环境并安装正确的软件版本。
-
ESP-IDF
在本示例中,我们将使用 ESP-IDF 5.0 版本(主分支)。如果你需要关于如何设置 ESP-IDF 的指导,请参考官方《ESP-IDF 编程指南》了解更多信息。
*截至撰写本文时,IDF 提交头为 df9310ada2。
-
ChatGPT API
ChatGPT 是一个基于 GPT-3.5 架构的强大语言模型,要使用 ChatGPT,请先前往 OpenAI 平台上创建账户,获取免费或付费的 API 密钥。通过 API 密钥,可获取很多功能和能力,例如自然语言处理与生成、文本补全以及对话建模等,还可根据自己的需求定义这些功能。更多信息请访问官方 API 参考。
*请务必保障 API 密钥的机密性和安全性,防止未经授权访问您的账户和数据。
赋能离线语音识别
乐鑫开发的创新性语音识别框架 ESP-SR 能够使设备在不依赖外部云服务的情况下识别口语词汇和短语,因此非常适合离线语音识别应用。
ESP-SR 框架包含多个模块,包括音频前端 (AFE)、唤醒词引擎 (WakeNet)、语音指令词识别 (MultiNet) 和语音合成(目前仅支持中文)。请查阅 ESP-SR 官方文档获取更多信息。
集成 OpenAI API
OpenAI API 提供了许多功能,开发人员可以利用这些功能来增强他们的应用程序。我们的项目使用了音频转文本 API 和补全 API,以及基于 ESP-IDF 的 C 语言代码。下文简要介绍我们所使用的代码。
-
音频转文本
我们使用 HTTPS 和 OpenAI 音频 API 从音频中提取文本,以下为实现代码。
esp_err_t create_whisper_request_from_record(uint8_t *audio, int audio_len)
{// Set the authorization headerschar url[128] = "https://api.openai.com/v1/audio/transcriptions";char headers[256];snprintf(headers, sizeof(headers), "Bearer %s", OPENAI_API_KEY);// Configure the HTTP clientesp_http_client_config_t config = {.url = url,.method = HTTP_METHOD_POST,.event_handler = response_handler,.buffer_size = MAX_HTTP_RECV_BUFFER,.timeout_ms = 60000,.crt_bundle_attach = esp_crt_bundle_attach,};// Initialize the HTTP clientesp_http_client_handle_t client = esp_http_client_init(&config);// Set the headersesp_http_client_set_header(client, "Authorization", headers);// Set the content type and the boundary stringchar boundary[] = "boundary1234567890";char content_type[64];snprintf(content_type, sizeof(content_type), "multipart/form-data; boundary=%s", boundary);esp_http_client_set_header(client, "Content-Type", content_type);// Set the file data and sizechar *file_data = NULL;size_t file_size;file_data = (char *)audio;file_size = audio_len;// Build the multipart/form-data requestchar *form_data = (char *)malloc(MAX_HTTP_RECV_BUFFER);assert(form_data);ESP_LOGI(TAG, "Size of form_data buffer: %zu bytes", sizeof(*form_data) * MAX_HTTP_RECV_BUFFER);int form_data_len = 0;form_data_len += snprintf(form_data + form_data_len, MAX_HTTP_RECV_BUFFER - form_data_len,"--%s\r\n""Content-Disposition: form-data; name=\"file\"; filename=\"%s\"\r\n""Content-Type: application/octet-stream\r\n""\r\n", boundary, get_file_format(file_type));ESP_LOGI(TAG, "form_data_len %d", form_data_len);ESP_LOGI(TAG, "form_data %s\n", form_data);// Append the audio file contentsmemcpy(form_data + form_data_len, file_data, file_size);form_data_len += file_size;ESP_LOGI(TAG, "Size of form_data: %zu", form_data_len);// Append the rest of the form-dataform_data_len += snprintf(form_data + form_data_len, MAX_HTTP_RECV_BUFFER - form_data_len,"\r\n""--%s\r\n""Content-Disposition: form-data; name=\"model\"\r\n""\r\n""whisper-1\r\n""--%s--\r\n", boundary, boundary);// Set the headers and post fieldesp_http_client_set_post_field(client, form_data, form_data_len);// Send the requestesp_err_t err = esp_http_client_perform(client);if (err != ESP_OK) {ESP_LOGW(TAG, "HTTP POST request failed: %s\n", esp_err_to_name(err));}// Clean up clientesp_http_client_cleanup(client);// Return error codereturn err;
}这段代码是一个名为 whisper_from_record 的函数,它接受一个指向包含音频数据的缓冲区的指针和一个表示音频数据长度的整数 audio_len。该函数向 OpenAI API 端点发送一个 POST 请求,对给定的音频数据进行转录。
该函数首先初始化 OpenAI API 的 URL,并使用持有者令牌 (bearer token) 的OPENAI_API_KEY 设置授权头。然后,配置并初始化 HTTP 客户端,包括配置 URL、HTTP 方法、事件处理程序、缓冲区大小、超时和 SSL 证书等。
接下来,将内容类型 (content type) 和多部分表单数据 (multipart/form_data) 请求的边界字符串设置为 HTTP 客户端的头部,还设置了文件数据和文件大小,并构建了一个多部分表单数据请求。使用 malloc() 函数分配 form_data 缓冲区,并添加必要的信息,包括音频文件的文件名、内容类型、文件内容以及将用于转录的模型名称。
一旦构建了 form_data,它就被设置为 HTTP 客户端的 POST 字段,并且客户端将 POST 请求发送到 OpenAI API 端点。如果请求过程中出现错误,该函数会记录错误消息。最后,清理 HTTP 客户端,并释放为 form_data 分配的资源。
该函数返回一个 esp_err_t 错误代码,指示 HTTP 请求是否成功。
-
聊天补全
我们使用 OpenAI 聊天补全 (Chat Completion) API 发送 HTTPS 请求来进行聊天补全。这个过程使用 create_chatgpt_request 函数,该函数接受一个表示输入文本的 content 参数,并将参数内容输入 GPT-3.5 模型。
esp_err_t create_chatgpt_request(const char *content)
{char url[128] = "https://api.openai.com/v1/chat/completions";char model[16] = "gpt-3.5-turbo";char headers[256];snprintf(headers, sizeof(headers), "Bearer %s", OPENAI_API_KEY);esp_http_client_config_t config = {.url = url,.method = HTTP_METHOD_POST,.event_handler = response_handler,.buffer_size = MAX_HTTP_RECV_BUFFER,.timeout_ms = 30000,.cert_pem = esp_crt_bundle_attach,};// Set the headersesp_http_client_handle_t client = esp_http_client_init(&config);esp_http_client_set_header(client, "Content-Type", "application/json");esp_http_client_set_header(client, "Authorization", headers);// Create JSON payload with model, max tokens, and contentsnprintf(json_payload, sizeof(json_payload), json_fmt, model, MAX_RESPONSE_TOKEN, content);esp_http_client_set_post_field(client, json_payload, strlen(json_payload));// Send the requestesp_err_t err = esp_http_client_perform(client);if (err != ESP_OK) {ESP_LOGW(TAG, "HTTP POST request failed: %s\n", esp_err_to_name(err));}// Clean up clientesp_http_client_cleanup(client);// Return error codereturn err;
}该函数首先设置了用于 HTTP POST 请求的 URL、模型和头部信息,然后创建一个包含模型、最大 token 数和内容的 JSON 负载。
接下来,函数设置了 HTTP 请求的头部信息,并将 JSON 负载设置为请求的 POST 字段。
使用 esp_http_client_perform() 发送 HTTP POST 请求,如果请求失败,将记录错误消息。
最后,清理 HTTP 客户端并返回错误代码。
-
处理响应
ESP-IDF HTTP 客户端库使用回调函数 response_handler 来处理在 HTTP 请求/响应交换过程中发生的事件。
esp_err_t response_handler(esp_http_client_event_t *evt)
{static char *data = NULL; // Initialize data to NULLstatic int data_len = 0; // Initialize data to NULLswitch (evt->event_id) {case HTTP_EVENT_ERROR:ESP_LOGI(TAG, "HTTP_EVENT_ERROR");break;case HTTP_EVENT_ON_CONNECTED:ESP_LOGI(TAG, "HTTP_EVENT_ON_CONNECTED");break;case HTTP_EVENT_HEADER_SENT:ESP_LOGI(TAG, "HTTP_EVENT_HEADER_SENT");break;case HTTP_EVENT_ON_HEADER:if (evt->data_len) {ESP_LOGI(TAG, "HTTP_EVENT_ON_HEADER");ESP_LOGI(TAG, "%.*s", evt->data_len, (char *)evt->data);}break;case HTTP_EVENT_ON_DATA:ESP_LOGI(TAG, "HTTP_EVENT_ON_DATA (%d +)%d\n", data_len, evt->data_len);ESP_LOGI(TAG, "Raw Response: data length: (%d +)%d: %.*s\n", data_len, evt->data_len, evt->data_len, (char *)evt->data);// Allocate memory for the incoming data data = heap_caps_realloc(data, data_len + evt->data_len + 1, MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);if (data == NULL) {ESP_LOGE(TAG, "data realloc failed");free(data);data = NULL;break;}memcpy(data + data_len, (char *)evt->data, evt->data_len);data_len += evt->data_len;data[data_len] = '\0';break;case HTTP_EVENT_ON_FINISH:ESP_LOGI(TAG, "HTTP_EVENT_ON_FINISH");if (data != NULL) {// Process the raw dataparsing_data(data, strlen(data));// Free memoryfree(data); data = NULL;data_len = 0;}break;case HTTP_EVENT_DISCONNECTED:ESP_LOGI(TAG, "HTTP_EVENT_DISCONNECTED");break;default:break;}return ESP_OK;
}在 HTTP_EVENT_ON_DATA 事件发生时,该函数为接收到的数据分配内存空间,将数据复制到缓冲区,并相应地增加 data_len 变量的值。这样做是为了累积响应数据。
在 HTTP_EVENT_ON_FINISH 事件发生时,该函数打印一条消息,指示 HTTP 交换已完成,然后调用 parsing_data 函数来处理累积的原始数据,释放内存并将数据和 data_len 变量重置为零,释放分配的内存并将缓冲区及其长度重置为零。
最后,该函数返回 ESP_OK,表示操作成功。
-
解析原始数据
我们使用 JSON 解析器组件解析从 ChatGPT API 和 Whisper AI API 获取的 HTTPS 原始响应。为了完成这个任务,我们使用一个调用解析器组件的函数。有关该工具的更多细节,请参考 GitHub。
void parse_response (const char *data, int len)
{jparse_ctx_t jctx;int ret = json_parse_start(&jctx, data, len);if (ret != OS_SUCCESS) {ESP_LOGE(TAG, "Parser failed");return;}printf("\n");int num_choices;/* Parsing Chat GPT response*/if (json_obj_get_array(&jctx, "choices", &num_choices) == OS_SUCCESS) {for (int i = 0; i < num_choices; i++) {if (json_arr_get_object(&jctx, i) == OS_SUCCESS && json_obj_get_object(&jctx, "message") == OS_SUCCESS &&json_obj_get_string(&jctx, "content", message_content, sizeof(message_content)) == OS_SUCCESS) {ESP_LOGI(TAG, "ChatGPT message_content: %s\n", message_content);}json_arr_leave_object(&jctx);}json_obj_leave_array(&jctx);}/* Parsing Whisper AI response*/else if (json_obj_get_string(&jctx, "text", message_content, sizeof(message_content)) == OS_SUCCESS) {ESP_LOGI(TAG, "Whisper message_content: %s\n", message_content);} else if (json_obj_get_object(&jctx, "error") == OS_SUCCESS) {if (json_obj_get_string(&jctx, "type", message_content, sizeof(message_content)) == OS_SUCCESS) {ESP_LOGE(TAG, "API returns an error: %s", message_content);}}
}集成 TTS API
目前,OpenAI 并未公开提供其文本转语音 (TTS) API 的访问权限。然而,市面上有多种其他的 TTS API 可供选择,包括 Voicerss、TTSmaker 和会话精灵 (TalkingGenie)。这些 API 可以根据文本输入生成语音,你可以在它们的网站上找到更多相关信息。
本教程使用的是 TalkingGenie API,它是目前可用的最佳选择之一,可以生成高质量、自然流畅的英文和中文语音。TalkingGenie 的一个特点是它能够无缝地将混合语言文本(如中文和英文)转化为语音。这对于面向全球受众的内容创作来说是一个宝贵的工具。下面的代码将 ChatGPT 生成的文本响应发送给 TalkingGenie API,然后通过 ESP-BOX 播放生成的语音。
esp_err_t text_to_speech_request(const char *message, AUDIO_CODECS_FORMAT code_format)
{int j = 0;size_t message_len = strlen(message);char *encoded_message;char *language_format_str, *voice_format_str, *codec_format_str;// Encode the message for URL transmissionencoded_message = heap_caps_malloc((3 * message_len + 1), MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);url_encode(message, encoded_message);// Determine the audio codec formatif (AUDIO_CODECS_MP3 == code_format) {codec_format_str = "MP3";} else {codec_format_str = "WAV";}// Determine the required size of the URL buint url_size = snprintf(NULL, 0, "https://dds.dui.ai/runtime/v1/synthesize?voiceId=%s&text=%s&speed=1&volume=%d&audiotype=%s", \VOICE_ID, \encoded_message, \VOLUME, \codec_format_str);// Allocate memory for the URL bufferchar *url = heap_caps_malloc((url_size + 1), MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);if (url == NULL) {ESP_LOGE(TAG, "Failed to allocate memory for URL");return ESP_ERR_NO_MEM;}// Format the URL stringsnprintf(url, url_size + 1, "https://dds.dui.ai/runtime/v1/synthesize?voiceId=%s&text=%s&speed=1&volume=%d&audiotype=%s", \VOICE_ID, \encoded_message, \VOLUME, \codec_format_str);// Configure the HTTP clientesp_http_client_config_t config = {.url = url,.method = HTTP_METHOD_GET,.event_handler = http_event_handler,.buffer_size = MAX_FILE_SIZE,.buffer_size_tx = 4000,.timeout_ms = 30000,.crt_bundle_attach = esp_crt_bundle_attach,};// Initialize and perform the HTTP requestesp_http_client_handle_t client = esp_http_client_init(&config);esp_err_t err = esp_http_client_perform(client);if (err != ESP_OK) {ESP_LOGE(TAG, "HTTP GET request failed: %s", esp_err_to_name(err));}// Free allocated memory and clean up the HTheap_caps_free(url);heap_caps_free(encoded_message);esp_http_client_cleanup(client);// Return the result of the function callreturn err;
}
函数 text_to_speech 接受一个消息字符串和 AUDIO_CODECS_FORMAT 参数作为输入。消息字符串是将被合成为语音的文本,而 AUDIO_CODECS_FORMAT 参数指定语音应该以 MP3 还是 WAV 格式进行编码。
该函数首先使用 url_encode 函数对消息字符串进行编码,将一些非有效字符替换为相应的 ASCII 代码,然后将该代码转换为两位十六进制格式。接下来为生成的编码字符串分配内存,检查 AUDIO_CODECS_FORMAT 参数,并设置适当的编解码器格式字符串,用于 url。
然后,函数确定 TalkingGenie API 的 GET 请求需要多大的 url 缓冲区,并分配相应的内存给 url 缓冲区。然后,将适当的参数写入 url 字符串,包括 voiceId(指定要使用的语音)、编码的文本、语音的速度和音量以及音频类型 (MP3 或 WAV)。
接下来,函数使用 url 和其他配置参数设置 esp_http_client_config_t 结构体,并使用该结构体初始化 esp_http_client_handle_t,然后使用 esp_http_client_perform 向 TalkingGenie API 发送 GET 请求。如果请求成功,函数返回 ESP_OK,否则返回错误代码。
最后,函数释放为 url 缓冲区和编码消息分配的内存,清理 esp_http_client_handle_t,并返回错误代码。
-
处理 TTS 响应
类似地,回调函数 http_event_handler 可用于处理在 HTTP 请求/响应交换过程中发生的事件。
static esp_err_t http_event_handler(esp_http_client_event_t *evt)
{switch (evt->event_id) {// Handle errors that occur during the HTTP requestcase HTTP_EVENT_ERROR:ESP_LOGE(TAG, "HTTP_EVENT_ERROR");break;// Handle when the HTTP client is connectedcase HTTP_EVENT_ON_CONNECTED:ESP_LOGI(TAG, "HTTP_EVENT_ON_CONNECTED");break;// Handle when the header of the HTTP request is sentcase HTTP_EVENT_HEADER_SENT:ESP_LOGI(TAG, "HTTP_EVENT_HEADER_SENT");break;// Handle when the header of the HTTP response is receivedcase HTTP_EVENT_ON_HEADER:ESP_LOGI(TAG, "HTTP_EVENT_ON_HEADER");file_total_len = 0;break;// Handle when data is received in the HTTP responsecase HTTP_EVENT_ON_DATA:ESP_LOGI(TAG, "HTTP_EVENT_ON_DATA, len=%d", evt->data_len);if ((file_total_len + evt->data_len) < MAX_FILE_SIZE) {memcpy(record_audio_buffer + file_total_len, (char *)evt->data, evt->data_len);file_total_len += evt->data_len;}break;// Handle when the HTTP request finishescase HTTP_EVENT_ON_FINISH:ESP_LOGI(TAG, "HTTP_EVENT_ON_FINISH:%d, %d K", file_total_len, file_total_len / 1024);audio_player_play(record_audio_buffer, file_total_len);break;// Handle when the HTTP client is disconnectedcase HTTP_EVENT_DISCONNECTED:ESP_LOGI(TAG, "HTTP_EVENT_DISCONNECTED");break;// Handle when a redirection occurs in the HTTP requestcase HTTP_EVENT_REDIRECT:ESP_LOGI(TAG, "HTTP_EVENT_REDIRECT");break;}return ESP_OK;
} HTTP_EVENT_ON_DATA 事件用于处理从服务器接收到的音频数据。音频数据存储在名为 record_audio_buffer 的缓冲区中,接收到的音频数据的总长度存储在名为 file_total_len 的变量中。如果接收到的音频数据的总长度小于预定义的 MAX_FILE_SIZE,则将数据复制到 record_audio_buffer 中。
最后,HTTP_EVENT_ON_FINISH 事件用于处理 HTTP 响应的结束。在这种情况下,将 record_audio_buffer 传递给名为 audio_player_play 的函数,用于播放音频。
显示
我们使用 LVGL 实现显示功能。LVGL 是一个开源的嵌入式图形库,因其强大且具有视觉吸引力的特性和低内存占用而日益受到欢迎。LVGL 还发布了一个名为 SquareLine Studio 的可视化拖放式 UI 编辑器。这是一个强大的工具,可帮助你轻松为应用程序创建美观的图形界面。
您可以使用乐鑫提供的官方软件包管理工具将 LVGL 集成到项目中,该工具可直接将 LVGL 和相关的移植组件添加到项目中,极大程度地节省了时间和精力。有关更多信息,请参阅官方博客和文档。
总结
OpenAI 的 ChatGPT 与乐鑫的 ESP-BOX 的完美融合,为创造强大而智能的物联网设备开创了新可能。ESP-BOX 提供灵活且可定制的 AIoT 开发平台,拥有远场语音交互、离线语音命令识别和可复用的 GUI 框架等功能。当这些功能与 OpenAI API 相结合时,开发者们即可打造语音控制的聊天机器人,提升物联网应用的用户体验。

您可以查看乐鑫的 GitHub 仓库,获取更多有关 ESP-IoT-Solution、ESP-SR 和 ESP-BOX 的开源案例。在 ESP-BOX 仓库的 examples 文件夹找到该项目的源代码。未来,我们计划引入一个用于 OpenAI API 的组件,以便为用户提供更多功能。