目录
一、html实体编码
1、Unicode字符编码
2、字符的数字表示
3、常见实体编码
4、url
协议
主机
http状态码
http常用的状态码
端口
常见协议端口
查询参数
锚点
url字符
urlcode字符
绝对url和相对url
二、字符编码
Ascll字符集
html字符集
html的url编码
html的base64编码
三、this关键字
什么是this关键字
作用域
绑定this关键字
Function.prototype.call()
Function.prototype.apply()
Function.prototype.bind()
一、html实体编码
网页包含了大量的文字,浏览器必须知道这些文字的编码方法,才能把文字还原出来。
一般情况下,服务器向浏览器发送 HTML 网页文件时,会通过 HTTP 头信息,声明网页的编码方式。
Content-Type: text/html; charset=UTF-8HTTP 头信息的Content-Type字段先声明,服务器发送的数据类型是text/html(即 HTML 网页),然后声明网页的文字编码是UTF-8。
网页内部也会再用<meta>标签,再次声明网页的编码。
<meta charset="UTF-8">1、Unicode字符编码
1、由于多数字符集都有容量限制,而且不兼容多语言环境,Unicode联盟开发了 Unicode 标准。
2、Unicode标准涵盖了世界上的所有字符、标点和符号。不论是何种平台、程序或语言,Unicode 都能够进行文本数据的处理、存储和交换。
3、Unicode联盟开发了Unicode标准。他们的目标是用标准的Unicode转换格式 (UTF) 来取代现有的字符集。
4、Unicode标准已经获得了成功,在 XML、Java、ECMAScript (JavaScript)、LDAP、CORBA 3.0、WML 中,Unicode已经得到了实现。在许多操作系统以及所有的现代浏览器中,Unicode同样得到了支持。Unicode联盟与领导性的标准发展组织进行合作,比如 ISO、W3C 以及 ECMA。
以下是常用的编码方式:utf-8和utf-16
| 字符集 | 描述 |
| utf-8 | UTF8中的字符可以是1-4个字节长。UTF-8可以表示Unicode标准中的任意字符。UTF-8向后兼容 ASCII。UTF-8是网页和电子邮件的首选编码。 |
| utf-16 | UTF8中的字符可以是1-4个字节长。UTF-8可以表示Unicode标准中的任意字符。UTF-8向后兼容 ASCII。UTF-8是网页和电子邮件的首选编码。 |
2、字符的数字表示
网页可以使用不同语言的编码方式,但是最常用的编码是 UTF-8。UTF-8 编码是 Unicode 字符集的一种表达方式。这个字符集的设计目标是包含世界上的所有字符,目前已经收入了十多万个字符。每个字符有一个 Unicode 号码,称为码点(code point)。如果知道码点,就能查到这是什么字符。举例来说,英文字母a的码点是十进制的97(十六进制的61),汉字“中”的码点是十进制的20013(十六进制的4e2d)。
不是每一个 Unicode 字符都能直接在 HTML 语言里面显示:
(1)不是每个 Unicode 字符都可以打印出来,有些没有可打印形式,比如换行符的码点是十进制的10(十六进制的A),就没有对应的字面形式。
(2)小于号(<)和大于号(>)用来定义 HTML 标签,其他需要用到这两个符号的场合,必须防止它们被解释成标签。
(3)由于 Unicode 字符太多,无法找到一种输入法,可以直接输入所有这些字符。换言之,没有一种键盘,有办法输入所有符号。
(4)网页不允许混合使用多种编码,如果使用 UTF-8 编码的同时,又想插入其他编码的字符,就会很困难。
HTML 为了解决上面这些问题,允许使用 Unicode 码点表示字符,浏览器会自动将码点转成对应的字符。
字符的码点表示法是&#N;(十进制,N代表码点)或者&#xN;(十六进制,N代表码点),比如,字符a可以写成a(十进制)或者a(十六进制),字符中可以写成中(十进制)或者中(十六进制),浏览器会自动转换它们。
<p>hello</p>
<!-- 等同于 -->
十进制
<p>hello</p> // html实体编码
<!-- 等同于 -->
十六进制
<p>hello</p>注意,HTML 标签本身不能使用码点表示,否则浏览器会认为这是所要显示的文本内容,而不是标签。比如,<p>一旦写成<p>或者<p>,浏览器就不再认为这是标签了,而会当作文本内容将其显示为<p>。
3、常见实体编码
为了能够快速输入,HTML 为一些特殊字符,规定了容易记忆的名字,允许通过名字来表示它们,这称为实体表示法(entity)。
实体的写法是&name;,其中的name是字符的名字。下面是其中一些特殊字符,及其对应的实体。
-
<:< -
>:> -
":" -
':' -
&:& -
©:© -
#:# -
§:§ -
¥:¥ -
$:$ -
£:£ -
¢:¢ -
%:% -
*:$ast; -
@:@ -
^:^ -
±:± -
空格:
4、url
URL 是“统一资源定位符”(Uniform Resource Locator)的首字母缩写,中文译为“网址”,表示各种资源的互联网地址。下面就是一个典型的 URL。
https://www.example.com/path/index.html
所谓资源,可以简单理解成各种可以通过互联网访问的文件,比如网页、图像、音频、视频、JavaScript 脚本等等。只有知道了它们的 URL,才能在互联网上获取它们。
只要资源可以通过互联网访问,它就必然有对应的 URL。一个 URL 对应一个资源,但是同一个资源可能对应多个 URL。
URL 是互联网的基础。互联网之所以“互联”,就是因为网页可以通过“链接”(link),包含其他 URL。用户只要点击,就可以从一个 URL 跳转到另一个 URL,前往不同的网站。
协议
协议(scheme)是浏览器请求服务器资源的方法。
互联网支持多种协议,必须指明网址使用哪一种协议,默认是 HTTP 协议。
HTTPS 是 HTTP 的加密版本,出于安全考虑,越来越多的网站使用这个协议。
HTTP 和 HTTPS 的协议名称后面,紧跟着一个冒号和两个斜杠(://)。其他协议不一定如此,邮件地址协议mailto:的协议名后面只有一个冒号,比如mailto:foo@example.com。
主机
主机(host)是资源所在的网站名或服务器的名字,又称为域名。
有些主机没有域名,只有 IP 地址,比如192.168.2.15。这种情况常常出现在局域网。
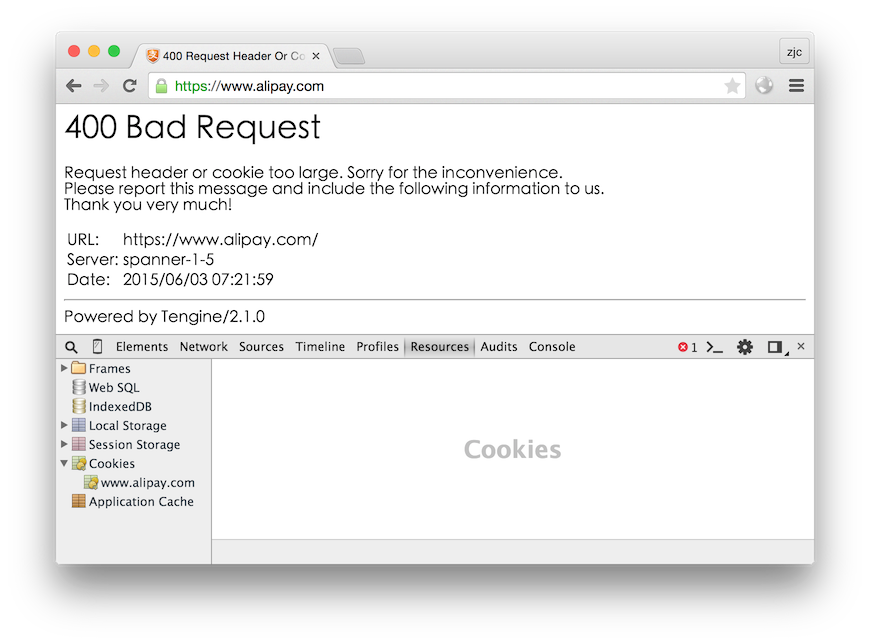
http状态码
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求:常见在登录界面:login.html |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
http常用的状态码
| 状态码 | 状态码英文 | 状态码中文详解 |
| 100 | Continue | 继续。客户端应继续其请求 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
端口
常见协议端口
-
http -------80
-
https------443
-
ftp----------20/21
-
tenlet------23
-
ssh---------22
-
DNS--------53
-
dhcp------67 68
-
smtp(邮件传输协议)--------25
-
pop3-------110
-
lapd--------389
-
mysql------3306
-
sqlserver(微软)----1443 语言:c#
-
oracle--------1521
-
3389——windows远程操作协议端口
-
redis------nosql------6379
查询参数
查询参数(parameter)是提供给服务器的额外信息。参数的位置是在路径后面,两者之间使用?分隔
查询参数可以有一组或多组。每组参数都是键值对(key-value pair)的形式,同时具有键名(key)和键值(value),它们之间使用等号(=)连接。比如,key1=value就是一个键值对,key1是键名,value1是键值。
多组参数之间使用&连接,比如key1=value1&key2=value2。
锚点
锚点(anchor)是网页内部的定位点,使用#加上锚点名称,放在网址的最后,比如#anchor。浏览器加载页面以后,会自动滚动到锚点所在的位置。
锚点名称通过网页元素的id属性命名。
url字符
URL 的各个组成部分,只能使用以下这些字符。
-
26个英语字母(包括大写和小写)
-
10个阿拉伯数字
-
连词号(
-) -
句点(
.) -
下划线(
_)
此外,还有18个字符属于 URL 的保留字符,只能在给定的位置出现。比如,查询参数的开头是问号(?),也就是说,问号只能出现查询参数的开头,出现在其他位置就是非法的,会导致网址解析错误。网址的其他部分如果要使用这些保留字符,必须使用它们的转义形式。
URL 字符转义的方法是,在这些字符的十六进制 ASCII 码前面加上百分号(%)。下面是这18个字符及其转义形式。
urlcode字符
-
!:%21 -
#:%23 -
$:%24 -
&:%26 -
':%27 -
(:%28 -
):%29 -
*:%2A -
+:%2B -
,:%2C -
/:%2F -
::%3A -
;:%3B -
=:%3D -
?:%3F -
@:%40 -
[:%5B -
]:%5D
绝对url和相对url
绝对 url 指的是,只靠 URL 本身就能确定资源的位置。这意味着,url 必须带有资源的完整信息,包含协议、主机、路径等部分。前面的例子都是绝对 url。
相对 url 指的是,url 不包含资源位置的全部信息,必须结合当前网页的位置,才能定位资源。
url 还可以使用两个特殊简写,表示特定位置。
-
.:表示当前目录,比如./a.html(当前目录下的a.html文件) -
..:表示上级目录,比如../a.html(上级目录下的a.html文件)
这两种简写可以多个连用,比如../../表示上两级目录。
二、字符编码
Ascll字符集
1、ASCII 字符集被用于因特网上不同计算机间传输信息。ascii码是字符的整数形式,是另一种标准码,任意一个字符都对应一个整数,将这个字符转换成ascii码是为了让你知道这个字符对应的数值是多少,其实转化不转化意义不大,因为他们在内存中的存储是一样的,都是0和1构成的相同的机器码,运算时你可以用字符直接运算,也可以用ascii码运算,结果是一样的。
2、不管是ascii码还是字符,都是显示出来方便我们看的,它们本质上是一组二进制码(机器码),字符和它的ascii码根本就是一回事,只是表现形式不同而已,计算机内部运算使用它的二进制,而你显示器上看到的是字符或ascii码。
3、ASCII ,它的全称是"美国信息交换标准代码"。它设计于60年代早期,是计算机和诸如打印机、磁带驱动器之类的硬件设备的标准字符集。
4、ASCII 是7比特字符集,包含了128个不同的字符值。
5、ASCII 支持0-9的数字,A-Z大写和小写英文字母,以及一些特殊字符。
6、通常需要时就到ASCII码对照表中进行转换,或者到在线转换网站进行编码。
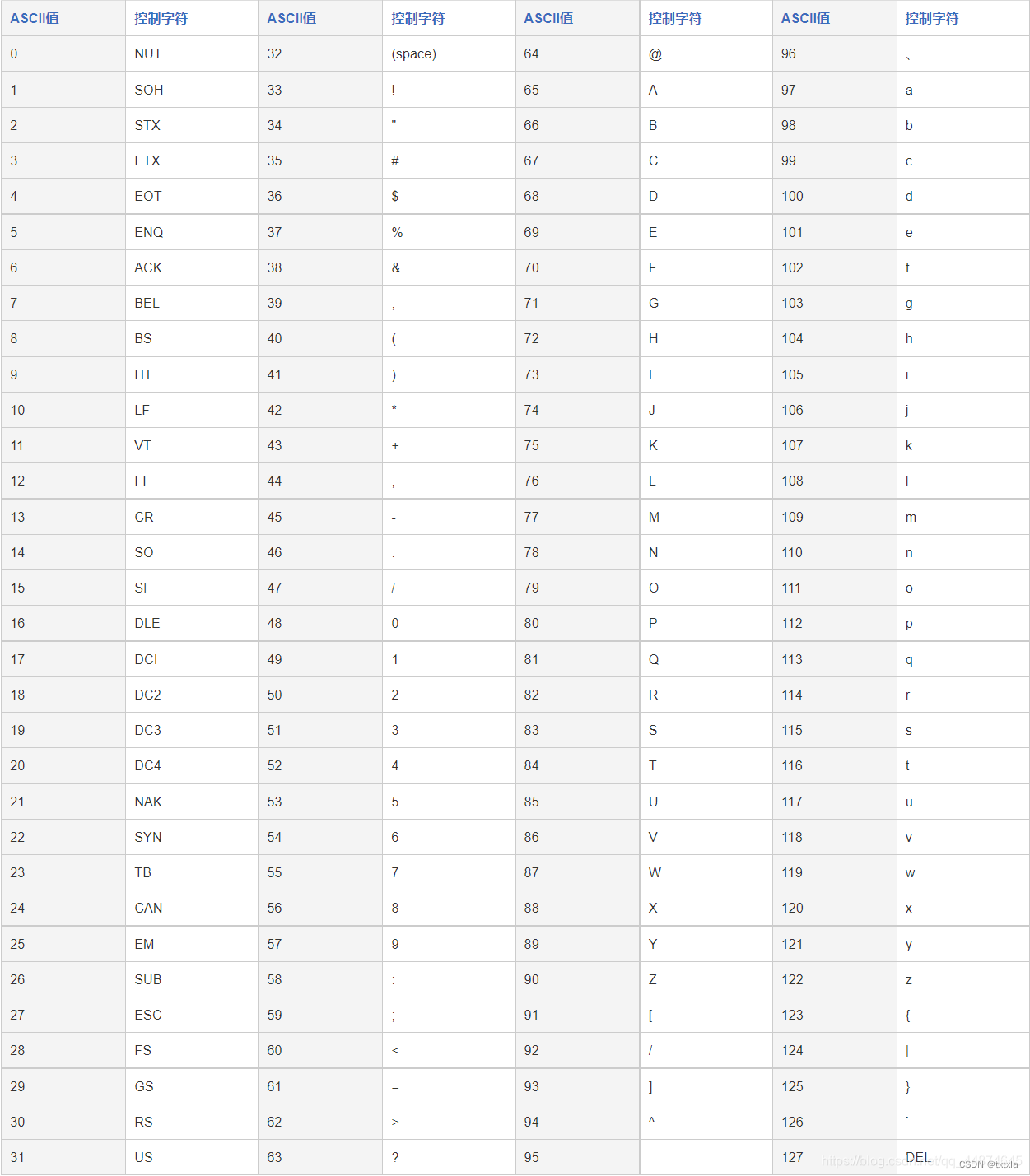
以下为常见Ascll码:
html字符集
1、如果需要正确地显示HTML页面,浏览器必须知道使用何种字符集。
2、万维网早期使用的字符集是ASCII。ASCII支持 0-9 的数字,大写和小写英文字母表,以及一些特殊字符。
3、除了ASCII字符集,后来还出现了ISO字符集和Unicode标准。
html的url编码
1、URL编码是一种浏览器用来打包表单输入的格式。
2、浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。
3、那为什么需要进行URL编码呢?
我们都知道Http协议中参数的传输是"key=value"这种键值对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?name1=value1&name2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出参数值。所以这时候就需要通过URL编码进行数据分离从而提取有用信息。
URL编码只是简单的在特殊字符的各个字节前加上%,例如,我们对上述会产生奇异的字符进行URL编码后结果:“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。
4、URL编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
html的base64编码
1、Base64 是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。
2、Base64 编码是从二进制到字符的过程,可用于在HTTP 环境下传递较长的标识信息。采用Base64 编码具有不可读性,需要解码后才能阅读。
3、Base64 由于以上优点被广泛应用于计算机的各个领域,然而由于输出内容中包括两个以上“符号类”字符(+, /, =),不同的应用场景又分别研制了Base64的各种“变种”。
4、其实在日常生活中,Base64编码无处不在。X.509公钥证书也好,电子邮件数据也好,经常要用到Base64编码,那么为什么要作一下这样的编码呢?
我们知道在计算机中的字节共有256个组合,对应就是ascii码,而ascii码的128~255之间的值是不可见字符。而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
对证书来说,特别是根证书,一般都是作Base64编码的,因为它要在网上被许多人下载。电子邮件的附件一般也作Base64编码的,因为一个附件数据往往是有不可见字符的。
5、那么Base64到底是怎样编码的呢?
简单来说,任何一个数据无非可以看作一个比特流,如01000100010011101100111010111100011001010…那么我们取6个比特为一组,计算它的ascii值,得到一个字符,这个字符肯定是可见字符,好,把它对应的字符写出来,再取6个比特,再次计算它的ascii值,如此下去,直到最后,就完成了编码。
三、this关键字
什么是this关键字
1、this是一个变量 ,一个引用。
this保存的就是当前对象的地址,指向对象本身,即this代表的就是“当前对象”。
2、this存储在堆内存中,存在于对象的内部。
3、this只能用在实例方法中,谁调用这个实例方法,this就是“谁自己”。
4、this不能出现在静态方法中
因为this代表当前对象,静态方法中不存在当前对象
强行调用会出现错误: 无法从静态上下文中引用非静态 变量 this
5、大多数情况下,this可以省略
作用域
javaScript的作用域分以下三种:
- 全局作用域:脚本模式运行所有代码的默认作用域
- 模块作用域:模块模式中运行代码的作用域
- 函数作用域:由函数创建的作用域
- 块级作用域:用一对花括号(一个代码块)创建出来的作用域(用 let 或 const 声明的变量属于额外的作用域)
绑定this关键字
Function.prototype.call()
call() 方法使用一个指定的 this值和单独给出的一个或多个参数来调用一个函数。
函数实例的call方法,可以指定函数内部this的指向(即函数执行时所在的作用域),然后在所指定的作用域中,调用该函数
var obj = {};var f = function () {return this;
};f() === window // true
f.call(obj) === obj // true
上面代码中,a函数中的this关键字,如果指向全局对象,返回结果为123。如果使用call方法将this关键字指向obj对象,返回结果为456。可以看到,如果call方法没有参数,或者参数为null或undefined,则等同于指向全局对象。
Function.prototype.apply()
apply方法的作用与call方法类似,也是改变this指向,然后再调用该函数。唯一的区别就是,它接收一个数组作为函数执行时的参数,使用格式如下。
func.apply(thisValue, [arg1, arg2, ...])
apply方法的第一个参数也是this所要指向的那个对象,如果设为null或undefined,则等同于指定全局对象。第二个参数则是一个数组,该数组的所有成员依次作为参数,传入原函数。原函数的参数,在call方法中必须一个个添加,但是在apply方法中,必须以数组形式添加。
Function.prototype.bind()
bind()方法用于将函数体内的this绑定到某个对象,然后返回一个新函数。
var d = new Date();
d.getTime() // 1481869925657var print = d.getTime;
print() // Uncaught TypeError: this is not a Date object.
上面代码中,我们将d.getTime()方法赋给变量print,然后调用print()就报错了。这是因为getTime()方法内部的this,绑定Date对象的实例,赋给变量print以后,内部的this已经不指向Date对象的实例了
而bind()方法可以解决这个问题。
var print = d.getTime.bind(d);
print() // 1481869925657
bind()方法将getTime()方法内部的this绑定到d对象,这时就可以安全地将这个方法赋值给其他变量了。