目录
Abstract
Background: DreamFusion
High-Resolution 3D Generation
Coarse-to-fine Diffusion Priors
Scene Models
Coarse-to-fine Optimization
NeRF optimization
Mesh optimization
Experiments
Controllable 3D Generation
Personalized text-to-3D
Prompt-based editing through fine-tuning
Abstract
- DreamFusion是目前基于文本的3D生成任务的主流方法,但它有两个重要缺陷:1)NeRF收敛速度慢;2)用于监督NeRF训练的图片质量较差,导致生成的3D目标质量较差。
- 对于上述两个问题,本文提出:1)用Instant-NGP替换DreamFusion中的NeRF;2)提出一中两阶段Coarse-to-fine的优化方法,第一步:基于Instant NGP表示低分辨率的3D物体,通过eDiff-I计算L_SDS,更新NeRF;第二步:用DMTet提取初始3D mesh,其次采样和渲染高分辨率图片,并和第一步类似,更新3D mesh。
- 相较于DreamFusion,Magic3D速度从1.5h较低到40m;同时在User Studies中,61.7%的用户认为Magic3D的生成效果更好。

Background: DreamFusion
DreamFusion是一种text-to-3D的生成方法,由两个关键部分组成:1)目标的神经场表示;2)预训练text-to-image扩散生成模型。通常,神经场是一个参数化函数:x = g(),给定相机位姿,渲染对应的图片x,其中,g是体渲染,theta是coordinate-based MLP。
扩散模型,包含去噪函数
,其中有预测噪声
,噪声图像
,噪声等级t和文本编码y。扩散模型提供了更新
的梯度方向:所有的渲染图像均被推到文本相关的高概率密度区域(all rendered images are pushed to the high probability density regions conditioned on the text embedding under the diffusion prior)。具体来说,DramFusion提出了Score Distillation Sampling (SDS):

其中,w(t)是权重函数。在实际应用时,常用classifier-free guidance,可以控制text conditioning的强度。
DreamFusion使用Mip-NeRF 360和Imagen。这有两个关键限制:1)无法获得高分辨率几何和纹理;2)现有的Mip-NeRF计算开销很大。
High-Resolution 3D Generation
- Magic3D是一个两阶段coarse-to-fine框架。
Coarse-to-fine Diffusion Priors
- Magic3D在coarse-to-fine中,有两个不同的扩散先验。在第一阶段,本文使用eDiff-I,可以在64 x 64低分辨率情况下,计算场景模型梯度;在第二阶段,本文使用Stable Diffusion,可以在高分辨率情况下反传梯度。尽管生成了高分辨率图像,SD的计算开销是可控的,因为扩散先验是作用在z_t上,而z_t的分辨率只有64 x 64。
Scene Models
- 在粗场景中,使用Instant NGP,NeRF可以平滑连续地处理拓扑学上的改变。
- 在细场景中,为减少计算开销,本文使用textured 3D meshes。使用NeRF作为mesh几何的初始化,可以有效避免mesh中大拓扑变化较难学习的问题。
Coarse-to-fine Optimization
NeRF optimization
- 与Instant NGP类似,本文用20初始化分辨率为256^3的occupancy grid,鼓励形状变化。每10 iter更新一次grid,并为可跳过的空白区域建立八叉树。在每次更新中,occupy grid降低0.6。
- 与Instant NGP不同,本文用MLP预测normals。
- 与DreamFusion类似,本文用MLP建模背景,输入为射线方向,预测RGB颜色。
Mesh optimization
- 将coarse density field减去一个非零整数,产生初始SDF s_i。同时,本文海基于粗阶段的color field直接初始化了volume texture field。
- 在优化阶段,本文用可导的光栅器将提取的surface mesh渲染为高分辨图片。对每个vertex,本文基于SDS梯度,同时优化s_i和delta_v_i。当渲染mesh为图片时,本文同时跟踪每个投影像素的3D坐标,用于在texture field中查询对应颜色,使梯度回传时同时优化texture field。
- 当渲染mesh时,本文增加focal length,聚焦于目标细节。使用粗阶段中学习的environment map产生背景,使用可导的抗锯齿方法(antialiasing)合成前景与背景。
- 为了鼓励表面平滑,本文对mesh上的不同相邻面的角度进行约束。
Experiments
本文在397个文本提示词上和DreamFusion进行比较。
Speed evaluation. 在8块A100上,coarse stage训练5000 iter,大概训练15分钟;fine stage训练3000 iter,大概训练25分钟。
Qualiatative comparisons

User studies. 在Amazon MTurk平台上,每个prompt由3个不同的users比较,共1191对比较。

Can single-stage optimization work with LDM prior?
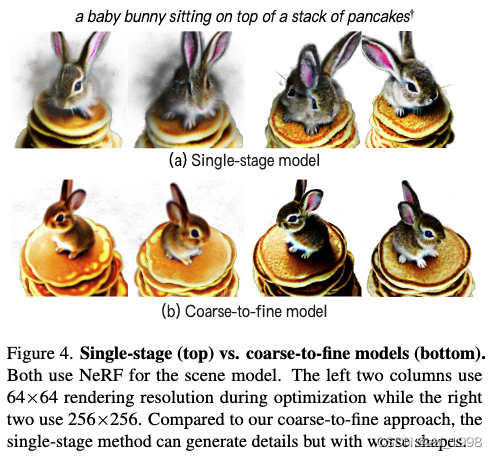
Coarse models vs. fine models.

Controllable 3D Generation
Personalized text-to-3D
基于Dreambooth fine-tune eDiff-I和LDM,将目标与[V]绑定。随后在计算SDS时,将[V]加入到文本提示词中。

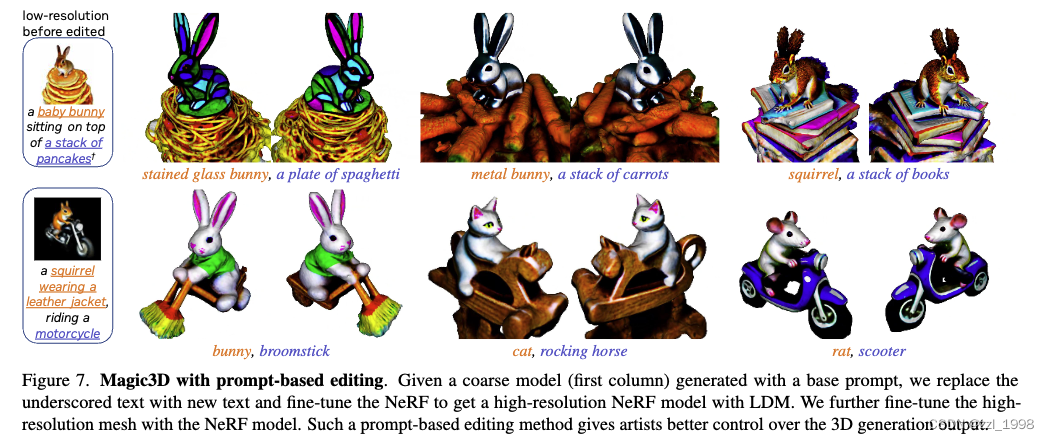
Prompt-based editing through fine-tuning
(a)基于base prompt训练粗模型;
(b)修改base prompt,使用LDM fine-tune粗模型;
(3)基于修改的文本提示词,优化mesh。