目录
背景:
mysql 整体结构:
SQL查询语句执行过程是怎样的:
知道了mysql的整体架构,那么一条查询语句是怎么被执行的呢:
什么是索引:
建立索引越多越好吗:
如何发现慢查询:
如何优化满查询:
背景:
性能测试过程中,数据库往往是造成性能瓶颈之一,而数据库瓶颈中sql 语句又是值得探究分析的一环,其中慢查询是重点优化对象,在MySQL中,慢查询是指查询执行时间较长或者消耗
较多资源的查询语句。具体来说,MySQL中可以通过设置一个阈值来定义慢查询,通常默认情况下是超过2秒钟的查询会被认为是慢查询,但是这个阈值可以根据具体情况进行调整。
慢查询的存在可能会对MySQL数据库的性能产生负面影响,因为它会占用大量的计算资源和I/O资源,导致其他查询的响应时间变慢。因此,及时发现并优化慢查询非常重要。
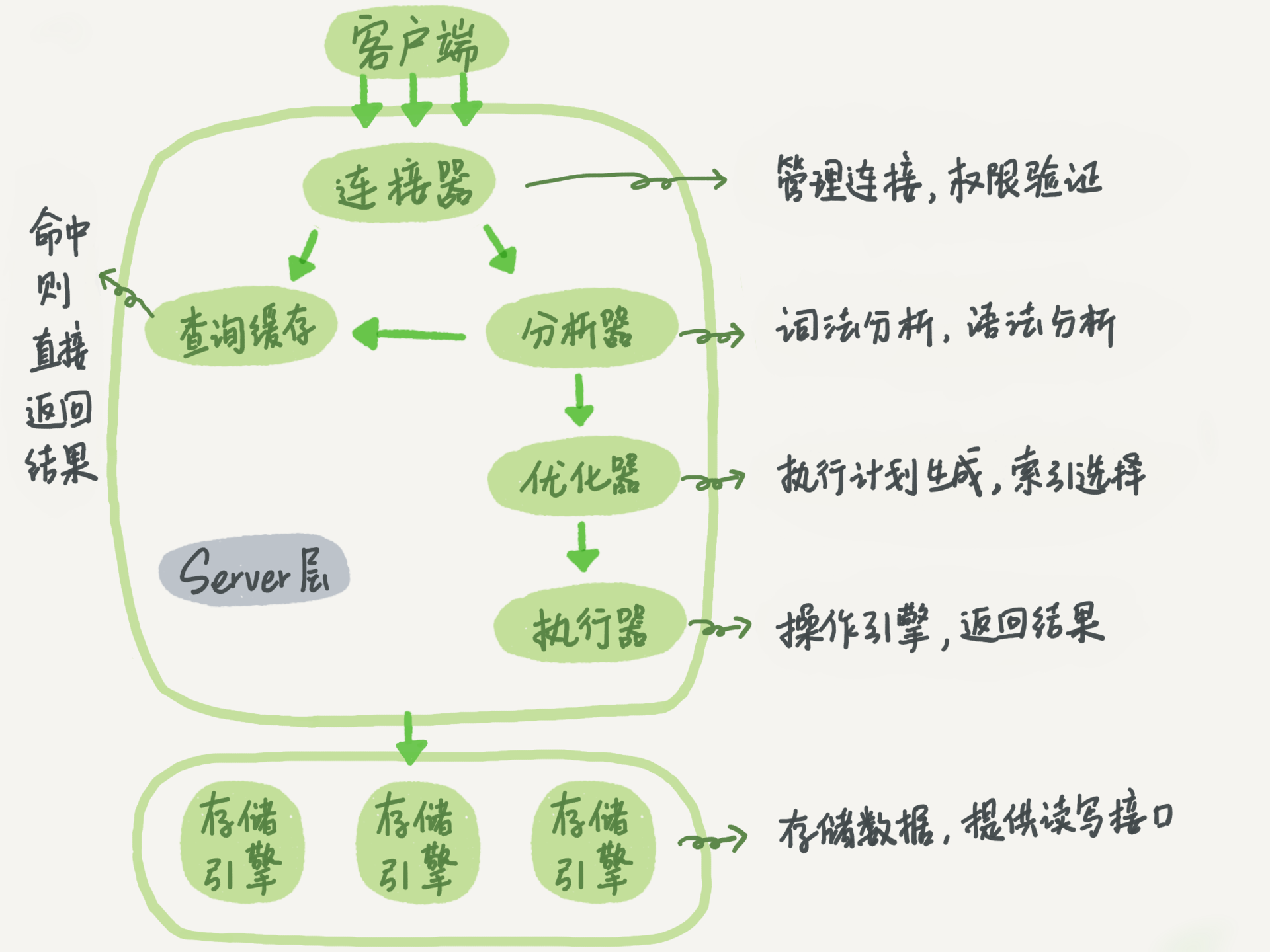
mysql 整体结构:
MySQL是一个典型的客户端-服务器(Client-Server)架构系统,它主要由以下几个组件构成:
-
客户端(Client):客户端是指连接到MySQL服务器的程序或工具,它们可以通过网络或本地套接字与MySQL服务器通信。MySQL提供了多种客户端工具,如mysql命令行工具、MySQL Workbench、phpMyAdmin等。
-
连接管理器(Connection Manager):连接管理器负责管理客户端连接和会话。它接收客户端的连接请求,并根据配置文件中的参数来限制连接数、最大并发数等,确保MySQL服务器的稳定性和安全性。
-
查询解析器(Query Parser):查询解析器负责解析客户端提交的SQL查询语句,并将其转换成MySQL服务器可理解的内部数据结构。在此过程中,查询解析器会检查查询语句的语法和语义是否正确,以及权限是否足够执行该查询。
-
优化器(Optimizer):优化器是MySQL查询执行的关键组件,它负责优化查询执行计划,以获得最佳的执行效率。优化器会分析查询语句,选择最优的索引、表的访问顺序、连接方式等来执行查询。MySQL提供了多种优化器,如基于规则的优化器、基于成本的优化器等。
-
存储引擎(Storage Engine):存储引擎是MySQL数据库中存储和管理数据的核心组件。MySQL支持多种存储引擎,如InnoDB、MyISAM、MEMORY等。每个存储引擎都有其独特的特性和适用场景,如InnoDB适合于高并发、事务性操作,MyISAM适合于读密集型操作等。
-
缓存(Cache):缓存是MySQL性能优化的重要手段之一。MySQL提供了多种缓存机制,如查询缓存、表缓存、缓冲池等。查询缓存可以缓存查询结果,以减少重复查询的开销;表缓存可以缓存表结构,以加速表的访问;缓冲池可以缓存磁盘上的数据,以提高数据访问的速度。
总的来说,MySQL架构是由客户端、连接管理器、查询解析器、优化器、存储引擎和缓存等组件构成的。每个组件都有其独特的作用和功能,共同协作来实现MySQL数据库系统的高效稳定运行。
SQL查询语句执行过程是怎样的:
知道了mysql的整体架构,那么一条查询语句是怎么被执行的呢:
你会先连接到这个数据库上,这时候接待你的就是连接器,连接建立完成后,执行逻辑就会来到查询缓存。如果开启来了查询缓存,之前执行过的语句及其结果可能会以 key-value 对的形
式,被直接缓存在内存中。如果命中,value直接返回给客户端。没有命中,则继续。执行完成后,执行结果会被存入查询缓存中。如果没有命中查询缓存,进入分析器,通过词法分析+语法分
析对 SQL 语句做解析,语法错误是从这个环节报出的。优化器是为了提升SQL的执行性能。经过了分析器,MySQL 就知道要做什么了。在开始执行之前,还要先经过优化器的处理。在表里面
有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。优化器优化后进入了执行器阶段,执行器跟存储层进行交互,取得执行结果并返
回。
什么是索引:
索引是一种用于加速数据库查询的数据结构。它可以快速定位到满足查询条件的记录,从而提高查询效率和性能。简单来讲,索引的出现其实就是为了提高数据查询的效率,就像书的目录
一样,如果你想快速找到其中的某一个知识点,在不借助目录的情况下,那我估计你可得找一会儿。同样,对于数据库的表而言,索引其实就是它的“目录”。在MySQL中,索引通常是基于B-
Tree(B树)或哈希表实现的。
索引主要包括主键索引和和非主键索引,主键索引是建立在表的主键列上的索引,而非主键索引则是建立在其他列或列组合上的索引。在查询过程中,主键索引和非主键索引的查询方式和效率有所不同。对于主键索引,MySQL可以通过B-Tree索引结构快速定位到指定的行记录,因为主键索引唯一,每个值都对应一个行记录,因此可以直接找到匹配的行记录。例如,如果需要查询id为10的学生记录,可以使用如下的SQL语句:
SELECT * FROM students WHERE id = 10;
MySQL会利用主键索引快速定位到id为10的行记录,效率非常高。而对于非主键索引,MySQL也可以通过B-Tree索引结构定位到满足查询条件的行记录,但是需要额外的步骤。首先,MySQL会根据非主键索引找到满足查询条件的行记录的主键值,然后再通过主键索引定位到实际的行记录。例如,如果需要查询姓名为“Tom”的学生记录,可以使用如下的SQL语句:
SELECT * FROM students WHERE name = 'Tom';
MySQL会利用非主键索引idx_students_name找到所有姓名为“Tom”的行记录的主键值,然后再根据主键索引定位到实际的行记录。这个过程称为“回表查询”,需要额外的IO操作和CPU计
算,因此效率相对较低。如果表中的数据量很大,回表查询的开销会更加显著。
建立索引越多越好吗:
建立索引并不是越多越好,反而可能会对数据库性能产生负面影响。首先,索引会占用存储空间,如果过多地建立索引,会导致数据库占用更多的磁盘空间,对于大型数据库来说,这可能
会导致磁盘空间不足。其次,索引会影响插入、更新和删除操作的性能。当进行插入、更新和删除操作时,MySQL需要更新数据和索引,如果过多地建立索引,就会使这些操作花费更多的时
间,从而降低数据库的性能。
最后,索引会影响查询操作的效率。虽然索引可以加速查询操作,但是如果过多地建立索引,就会导致MySQL需要在多个索引中选择最优的索引,这会增加查询的开销,并且可能会导致
MySQL选择不合适的索引,从而降低查询的效率。因此,在建立索引时,需要根据具体情况进行选择,避免过多地建立索引。通常情况下,可以考虑在经常使用的列上建立索引,或者在需要优
化查询的列上建立索引。同时,可以通过监控索引的使用情况,来确定哪些索引需要优化或删除,以提高数据库的性能和效率。
如何发现慢查询:
1. 通过设置slow_query_log参数来开启慢查询日志,对慢查询日志进行监控,如果新增慢查询便立即发送通知。(推荐)
2. 慢查询日志分析工具:MySQL提供了一些工具,如mysqldumpslow和mysqlsla,可以根据查询日志来分析慢查询,找出执行时间最长的查询和最频繁的查询等信息。
如何优化满查询:
情况1 :通过explain你可能会发现,SQL压根没走任何索引,而且现在表中的数据量巨大无比。
解决:建合适索引
情况2 : 通过explain查看SQL执行计划中的key字段。如果发现优化器选择的Key和你预期的Key不一样。那显然是优化器选错了索引
解决: 最快的解决方案就是:force index ,强制指定索引,或通过增加索引、优化索引、重构查询语句等方式来提高查询效率
情况3 :查询语句复杂或者存在大量子查询
解决:查询语句复杂或者存在大量子查询会影响查询性能,可以考虑通过优化SQL语句来提高查询效率。例如,可以使用JOIN语句替换多个子查询,或者使用WHERE子句限制返回的行数。
分析优化实践:
假设有一个名为“orders”的表,包含以下列:
- id: INT,主键列
- customer_id: INT,顾客编号
- status: ENUM('pending', 'completed', 'cancelled'),订单状态
- order_date: DATETIME,订单日期
- amount: DECIMAL(10,2),订单金额
现在需要查询所有订单金额大于1000元的未完成订单,查询语句如下:
SELECT * FROM orders WHERE status = 'pending' AND amount > 1000;
首先,可以通过使用EXPLAIN语句来查看查询计划,以了解查询的执行情况:
EXPLAIN SELECT * FROM orders WHERE status = 'pending' AND amount > 1000;
执行后发现 type列的值是ALL,走的全表扫描;key字段是NULL,没有使用任何索。接下来,可以在status和amount列上建立索引,建立索引的语句如下:
CREATE INDEX idx_orders_status ON orders (status);
CREATE INDEX idx_orders_amount ON orders (amount);
然后再次执行查询语句,可以看到查询效率有了显著提升,查询速度大大加快。
优化前的查询计划如下所示:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | orders| NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+优化后的查询计划如下所示:
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | orders| NULL | ref | idx_orders_status,idx_orders_amount | idx_orders_status | 2 | const | 5 | 50.00 | Using index condition |
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
可以看到,优化后的查询计划使用了idx_orders_status索引,查询效率大大提高。
因此,通过在status和amount列上建立索引的方式,可以提高查询效率,降低数据库的负载和响应时间。但需要注意的是,索引的建立需要根据具体情况进行选择和应用,过多的索引会影响插
入、更新和删除操作的性能,因此需要谨慎考虑索引的建立数量和方式。
以下是我收集到的比较好的学习教程资源,虽然不是什么很值钱的东西,如果你刚好需要,可以评论区,留言【777】直接拿走就好了


各位想获取资料的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~