在我们访问网站的时候,如果发现我们发布的内容有色情暴力的东西等等,会屏蔽掉,这种行为就是过滤敏感词。
从技术层面实现起来,其实比较简单,因为我们输入的内容就是一个大型的字符串,我们要调用某些api来判断这个字符串有没有敏感词,比如我们可以使用jdk自带的方法,比如String里面有个replace方法可以直接替换字符串。
但是网站在运行过程中,敏感词可能比较多,有几十个,甚至上百个。但是你发的如果是文章,字符串可能非常长,这种情况下,如果用replace一遍一遍替换,性能未免太差了,在实际开发过程中,我们往往会采用前缀树的数据结构

前缀树算法特点
- 根节点不包含任何字符,除了根节点以外的每个节点都只包含一个字符
- 从根节点到某一个节点经过的路上,经过的字符连接起来就是对应的字符串

从根节点到最末端才能算是敏感词,在我们检测的时候,需要三个指针。第一个指针指向树,默认的是指向根节点;第二个指针指向字符串,默认的是指向字符串中第一个字符;第三个指针依然指向字符串,默认的也是指向字符串中第一个字符。
这样在筛选或者过滤单词的时候,根据二三指针分别标记头尾就可以认为中间字符串是敏感词。二指针永远不回头,而第三个字符串到结尾会再次回到二字符串的新位置。最后用StringBuilder来接收
代码实现
创建存储敏感词的文件
在resources下创建txt文件,里面规定敏感词

创建工具类
为了便于使用,我们用@Component将他托管给容器,同时将数据结构封装到内部类中,因为除了这个类,别的类基本不会调用

创建前缀树

前缀树的结构其实并不复杂,下一个环节就是根据敏感词文件,与前缀树关联
添加前缀树

过滤敏感词
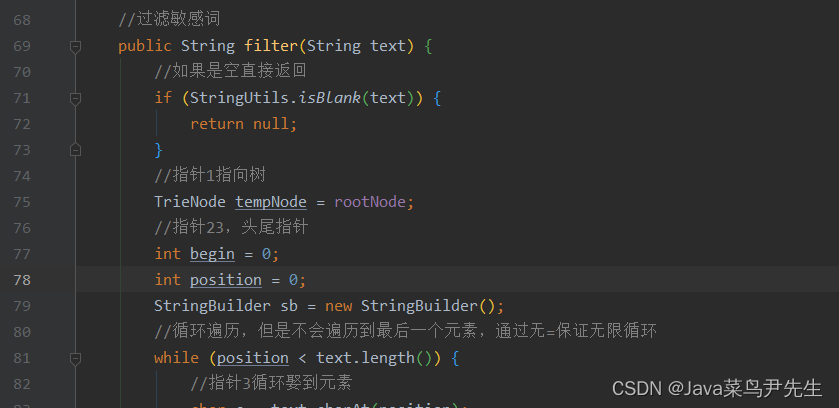
当指针3到达结尾,说明已经可以进行下一次遍历,所以应该用指针3进行遍历
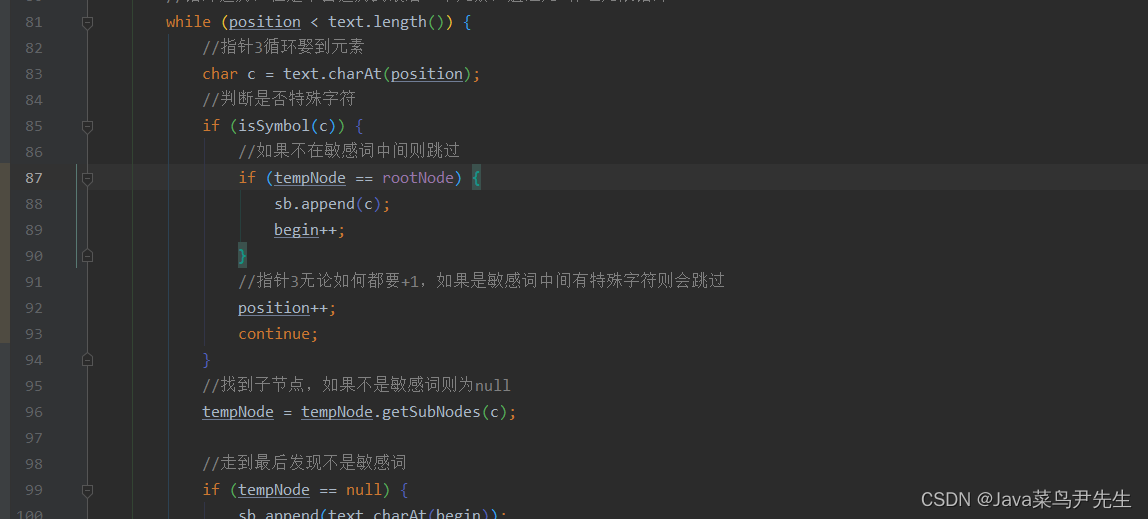
判断是否是敏感词