车云一体化系统基础理论
- 介绍
- 目标
- 正文
- 参考文档
介绍
最近在调研车云链路一体化的整套解决方案,涉及分布式消息队列(RocketMQ)、分布式存储(Doris)、离线数据处理(Spark)、用户行为日志分析(Flink);通过RocketMQ 串起车端应用和云端基础设施,通过MQTT上行车端行为,通过RocketMQ发布车端行为和整车日志,云端订阅后持久化到分布式存储系统,异步数据处理、分析日志和行为上报到看板和大数据平台,训练大模型并进行算法聚合生成可视化的结果集,再经过RocketMQ下发到APP(人)、域控(车),云端控通过MQTT下行下发结果集到车端域控;完成车云交互,人、车、云互通。
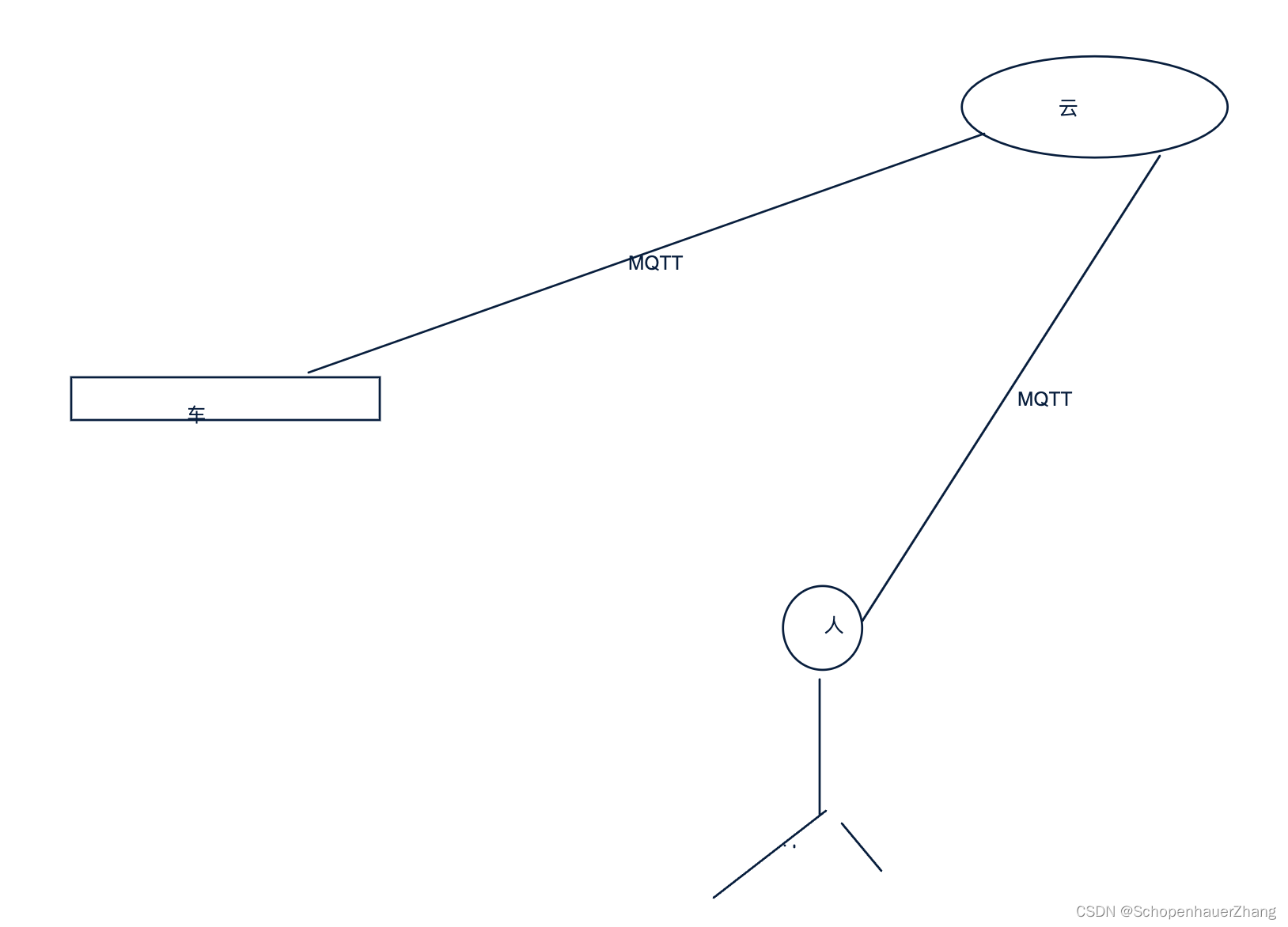
面对的难题主要是:
1)网络不可靠;
车端网络不可靠(车可能在地下停车场也可能在西伯利亚雪原,甚至可能出现在北极圈(:- )导致网络链路时断时续,车端传输00100,可能收到的是0_1_0,这种数据拿到了等于没有拿到;
2)数据量波动较大;
尤其是车的轨迹和状态上报,如果没有变化比如车停在停车场,大量的数据都是重复无效的;如果车正在行驶那么每一次上报都是重要且必须的;也就是说出行高峰阶段单台车的数据量能达到GB/h,而在晚间充电时8小时累计才几kb;
3)实时性强的同时要求离线异步处理;
正在行驶的车的状态上报和车端的智能驾驶系统(域控)需要极强的实时性,只要超过秒级的延时,数据就作废;
但是大模型和行为日志分析乃至可视化面板都需要异步离线处理,上报轨迹说此刻在天安门,10分钟响应“收到”,车可能已经上机场高速了(不堵车的话),这就无法接受;而且大模型的训练和日志分析都是需要大数据量的长时间的“总结”才能得出可靠的结果,毕竟个例不算数;就算是大数据量也不一定是可靠的,降噪是非常必须的,内部大模型就闹过笑话比如询问“中国人的家庭成员一般有谁?”,大模型出来的结果有“隔壁老王”,顿时笑倒一片;
4)“资源永远不够”;
内部技术团队3000多人,消息队列及分布式存储中间件仅我一个;问“加薪否?加人否?”答曰“资源永远不够,能否继续坚持!”,每聊至此,无不扼腕叹息;
目标
关于车、车联网云、云、人之间的关系的思考,随时补充,随时更改。
正文
结合以上场景和实际需求,目前看来比较可行的方案是:
1)摒弃网络问题;
“基站建不到北极圈”,“等马斯克的星链进入中国再说”;
2)数据量的波动大的问题拆开来解;
第一步
通过RocketMQ串行必要的信息,比如完整数据为“cid:123,trace:129Nxxxx,state:xxxxx,others”,那么车端域控集成简单的数据处理程序,将关键信息提取出来,比如状态上报“cid:123,state:xxxxx,”,行为上报:“cid:123,trace:129Nxxxx,”,同时将整条数据通过压缩异步上传到就近的分布式存储系统子节点;
第二步
云端获取到关键信息后立即开始实时处理,如果需要完整数据做detail handle,前往分布式存储系统节点读取detail或者分布式存储系统子节点讲数据进一步“汇总”到统一的存储区(Doris);
云端只要拿到关键信息后就能立刻判断是否需要进一步处理或者丢弃,一方面提高实时性,另一方面节省计算资源提高效率;
3)实时性强和异步离线处理的解决最为复杂;
对于车端,域控内是独立的子网和计算单元;数据的采集、压缩、上传都交给其agent独自负责,各个域控职责单一且独立;
云端的计算设施需要增加存量数据集,如果目标是100分,最好起步就是99,而不是从0跑到100;通过更多场景、更大的测试数据量、更多的训练资源、更快的版本迭代增强训练模型,甚至把部分模型嵌入硬件集成到车端;当然车端的软硬件升级是业界难题,就不多讲了;
根据实践经验和个人的观察思考,边缘计算在车端必定会兴起,“能够在车端做的事就不要搞到云端了”,从车到云再到车、人,这个链路做得再好也不如在车端做边缘计算节省资源,“车端自产自销永远是最高效、最快捷、最实惠的方式”;更不要说国内各大车企的云还在公有云上,上下行还要过几到网,费力不讨好。
所以车越来越像服务器,甚至车本身就是服务器。
参考文档
设计数据密集型应用