文章目录
- 一、UNDO日志格式
- 1、INSERT操作对应的UNDO日志
- 2、DELETE操作对应的undo日志
- 3、UPDATE操作对应的undo日志
- 1)不更新主键
- 2)更新主键的操作
- 3、增删改操作对二级索引的影响
- 二、UNDO页
- 三、UNDO页面链表
- 四、undo日志具体写入过程
- 五、回滚段
- 1、回滚段的结构
- 2、从回滚段申请UNDO页面链表
- 3、多个回滚段
- 4、roll_pointer
- 5、为事务分配UNDO页面链表的详细过程
- 六、undo日志在崩溃恢复时的作用
redo日志解决了事务的持久性问题,而原子性问题则是交给undo日志来保证。有时候事务执行过程中可能遇到服务器的宕机等原因导致事务中断,或者程序在事务执行过程中想取消本次事务,那么为了保证原子性(即要么事务的操作全部完成,要么什么也不做),我们需要把数据恢复为原本的样子,这个过程就成为回滚,为了回滚而记录的东西则成为undo log。在事务执行DML操作时,会先把回滚所需的东西都记下来,而对于查询语句则不会产生相应的undo日志。
一、UNDO日志格式
1、INSERT操作对应的UNDO日志
如果需要回滚一个插入操作,那么只需要把这条记录删除就好了,所以插入操作对应的undo日志会记录下这条记录的主键信息,其完整的结构如下:
-
end of record:指向本条undo日志结束的位置,即下一条日志开始时在页面中的地址
-
undo type:本条undo日志的类型,即TRX_UNDO_INSERT_REC
-
undo no:本条日志对应的编号
- undo no在一个事务中是从0开始递增的,也就是说只要事务没提交,每生成一条undo日志,那么该条日志的undo no就增加1
-
table id:本条日志对应的记录所在的表id
-
主键格列信息<len,value>列表:记录主键每个列占用的存储空间和真实值
-
start of record:指向本条undo日志开始的位置,即上一条日志结束时在页面中的地址
我们知道聚集索引的记录除了会保存完整的用户数据以外,还会自动添加名为trx_id、roll_pointer的隐藏列。那么当我们向表中插入记录之后,就会将记录中的trx_id设置为当前操作的事务id,并将roll_pointer指向产生的undo日志的头部。
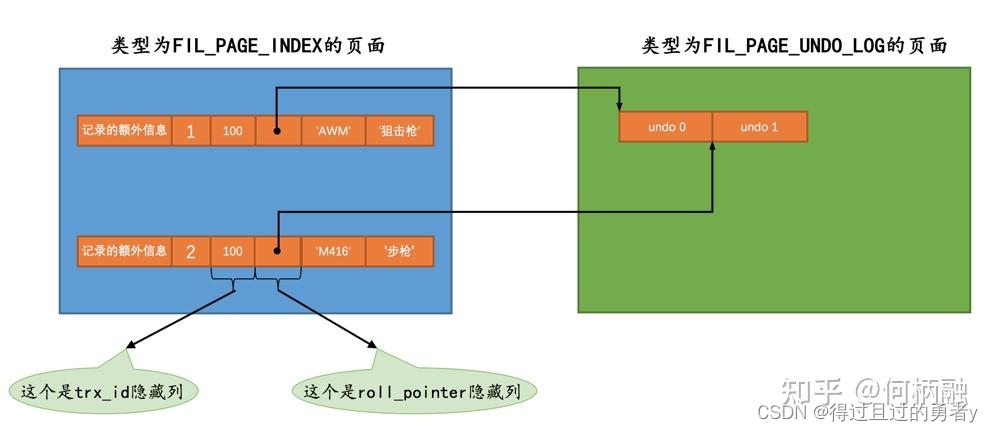
2、DELETE操作对应的undo日志
插入到页面中的记录会根据记录头信息中的next_record属性组成一个单项链表,而被删除的记录其实也会根据next_record属性组成一个垃圾链表,这个链表中记录占用的存储空间可以被重新利用。Page Header部分中有一个PAGE_FREE属性指向被删除记录组成的垃圾链表的头结点。
当我们使用DELETE语句时,记录的删除过程需要经历两个阶段:
- 仅仅将记录的deleted_flag标识置为1以及设置记录的trx_id和roll_pointerd等信息的值,这个操作被称为delete mark
- 当该删除语句所在的事务提交后,会有专门的线程来真正地把记录删除掉。这里所谓真正的删除其实就是指把该记录从正常链表中移除,并且加入到垃圾链表中。同时还回去修改页面中的一些其他信息(这里记录是添加到链表的头部,还需要更换PAGE_FREE属性)。这个操作被称为purge
**在提交事务之前,只做了delete mark操作而已,即使提交完事务,也可能因为MVCC机制,其他事务还需要看到当前这条记录,所以该undo log不会立即删除。提交时放入History链表,等待purge线程进行最后的删除。**当这两个阶段执行完后记录才算真正的被删除,这条记录占用的存储空间才可以重新利用。
从前面的描述可以看出,在执行一条删除语句的过程中,在删除语句所在事务提交之前,只会经历delete mark阶段。而一旦事务提交,则不再需要回滚这个事务了。所以设计undo日志时,只需要考虑对阶段一所做的影响进行回滚即可。InnoDB提供了一种名为TRX_UNDO_DEL_MARK_REC类型的undo日志,其结构如下:
- end of record
- undo type
- undo no
- table id
- info bits:记录头信息的前四个比特的值
- trx_id:旧记录的trx_id值
- roll_pointer:旧记录的roll_pointer值
- 主键各列信息<len,value>
- len of index_col_info:本部分和下一部分占用的存储空间大小
- 索引列各列信息<pos,len,value>:凡是被索引的列的各列信息
- start of record
delete对应的undo log中还需要记录旧的事务id和回滚指针即trx_id和roll_pointer,这样可以通过这条undo log 找到记录修改之前的undo log。insert因为是新创建的,所以肯定没有旧的事务,自然不需要这两个属性。
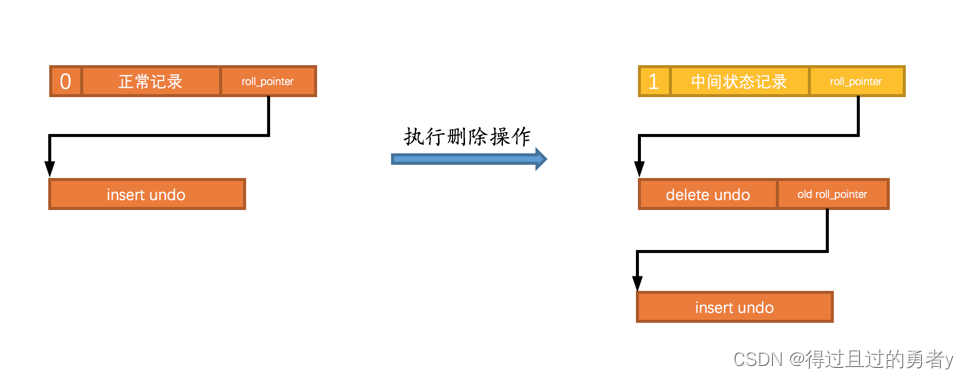
执行完delete mark操作后,undo log就和之前添加的undo log形成了一条链表,这个链表就称之为版本链。
3、UPDATE操作对应的undo日志
对于update要分两种情况讨论:更新主键的操作和不更新主键的操作。
1)不更新主键
不更新主键的操作又可以分为新的记录各列数据大小与旧记录相同或不同两种情况:
-
相同:直接更新,即在原记录上修改
-
不同:先删除后添加。此处不只是进行delete mark,而是由用户进程同步执行了完整的删除操作
- 因为主键没有变,直接删除掉旧的,再添加的记录也具有和原本一样的主键,那么其他事务同样可以根据主键找到新的这条记录,之后拿到原本的版本
- 删除操作之所以不能直接删除,是因为删除完其他事务就拿不到这条信息了,而这里是修改,有新增记录,通过它的roll_pointer指针就可以拿到其他版本的数据(不同于insert产生的undo日志,这里产生的undo日志记录也有roll_pointer)
- 进行 purge 操作的不再是删除专用的线程,而是由用户线程同步执行的
InnoDB为不更新主键的操作设计TRX_UNDO_UPD_EXIST_REC类型的undo日志,其与前面介绍的TRX_UNDO_DEL_MARK_REC类型的undo日志结构类似,不过多了一个n_updated的列来表示有多少个列被更新以及一个被更新列的更新前信息<pos,old_len,old_value>。此外如果更新的列不包含索引列,则不会有索引列各项信息这个部分。
2)更新主键的操作
如果更新了主键,意味着该记录在聚簇索引中的位置将发生改变,极有可能不在同一个页面中,更新记录的主键分为两步操作:
- 原记录delete mark(trx_undo_del_mark_rec),这里不会将记录真正删除,因为主键改变了,如果放入垃圾链表其他事务就找不到这条记录了
- 添加修改后的记录(trx_undo_insert_rec)
针对UPDATE语句更新记录主键值的这种情况,在对该记录进行delete mark操作时,会记录一条类型为TRX_UNDO_DEL_MARK_REC的undo日志,之后插入新记录时,会记录一条类型为TRX_UNDO_INSERT_REC的undo日志。
3、增删改操作对二级索引的影响
一个表可以拥有一个聚簇索引以及多个二级索引,对于二级索引记录来说,INSERT操作和DELETE操作与在聚簇索引中执行时产生的影响差不多,但是UPDATE操作稍微有点不同。如果我们的UPDATE语句涉及了索引列,那么相当于更新了二级索引记录的键值,那么需要进行以下两个操作:
- 对旧的二级索引记录执行delete mark操作
- 根据更新后的值创建一条新的二级索引记录
其实就是相当于在聚簇索引中更新主键的操作,因为更改二级索引对于二级索引页来说和更新聚簇索引页中的主键是一个道理的,都会导致记录的位置发生变化。
虽然只有聚簇索引记录才有trx_id、roll_pointer这些属性,不过每当我们增删改一条二级索引记录时,都会影响这条二级索引记录所在页面的Page Header部分中一个名为Page_MAX_TRX_ID的属性。
二、UNDO页
这些undo日志被记录到类型为FIL_PAGE_UNDO_LOG的页面中,其结构如下:
-
File Header:页的通用结构,不再赘述
-
Undo Page Header:undo页特有的结构
-
TRX_UNDO_PAGE_TYPE:本页面存放的undo日志的类型,分为两类
-
TRX_UNDO_INSERT:一般由INSERT语句产生,当UPDATE语句有更新主键的情况下也会产生此类型的日志
-
TRX_UNDO_UPDATE:除了TRX_UNDO_INSERT,其他日志都属于这个类型
之所以分为这两个大类,是因为INSERT类型的日志在事务提交之后可以直接删除掉,而其他类型的undo日志还需要为MVCC服务,不能直接删除,所以对它们的处理需要区别对待。
-
-
TRX_UNDO_PAGE_START:当前页面中从什么位置开始存储undo日志,或者说第一条undo日志在本页面中的起始偏移值(因为其实在Undo Page Header和undo日志之间还可能有其他部分,所以需要这个指针。详见下文)
-
TRX_UNDO_PAGE_FREE:当前页面中最后一条undo日志的结束时的偏移值,或者说从这个位置开始可以写入新的undo日志
-
TRX_UNDO_PAGE_NODE:代表一个链表节点结构,其中包含指向前一个和后一个节点的指针
-
-
undo日志
-
FIle Trailer:页的通用结构,不再赘述
三、UNDO页面链表
因为一个事务可能包含多个语句,而且一个语句可能会对若干条记录进行改动,而对每条记录进行改动前都需要记录1-2条undo日志,所以在一个事务执行过程中可能会产生很多undo日志。这些日志可能在一个页面中放不下,需要放到多个页面中,这些页面通过TRX_UNDO_PAGE_NODE属性连接成链表。
而在一个事务的执行过程中,可能会产生不同类型的undo日志,而一个UNDO页面要么只存储TRX_UNDO_INSERT大类的undo日志,要么只存储TRX_UNDO_UPDATE大类的undo日志,不能混着存储。所以在一个事务的执行过程中可能需要两个UNDO页面的链表,一个称为insert undo链表,一个称为update undo链表。此外,InnoDB规定普通表和临时表的记录改动所产生的的undo日志要分开记录,所以在一个事务中最多有4个以UNDO页面为节点组成的链表。当然,在事务刚开始的时候一个链表也不会分配,只有需要的时候才按需分配。
不同事务执行过程中产生的undo日志需要写入不同的UNDO页面链表中。
四、undo日志具体写入过程
InnoDB规定每一个UNDO页面链表都对应着一个段,称为Undo Log Segment,并且UNDO页面链表中的第一个页面比普通的UNDO页面还增加了一个Undo Log Segment Header部分(位于Undo Page Header下方),其结构如下:
-
TRX_UNDO_STATE:本UNDO页面链表处于什么状态
- TRX_UNDO_ACTIVE:活跃状态,也就是一个活跃的事务正在向这个链表中写入undo日志
- TRX_UNDO_CACHED:被缓存的状态,处于该状态的UNDO页面链表等待之后被其他事务重用
- TRX_UNDO_TO_FREE:等待被释放的状态,对于insert undo链表来说,如果在其他的事务提交之后,该链表不能被重用,则会处于这种状态
- TRX_UNDO_TO_PRUGE:等待被purge的状态,对于update undo链表来说,如果它对应的事务提交后,该链表不能被重用,就会处于这种状态
- TRX_UNDO_PREPARE:处于此状态的UNDO页面链表用于存储处于PREPARE阶段的事务产生的日志
-
TRX_UNDO_LAST_LOG:本UNDO页面链表中最后一个Undo Log Header的位置
-
TRX_UNDO_FSEG_HEADER:本UNDO页面链表对应的段的Segment Header信息(用于寻找INODE Entry)
-
TRX_UNDO_PAGE_LIST:UNDO页面链表的基节点
对于链表中的第一个页面,除了Undo Log Segment Header,在其下面还会有一个Undo Log Header,其结构如下:
-
TRX_UNDO_TRX_ID:生成本组undo日志的事务id(每个链表中写入的undo日志视为一个组)
-
TRX_UNDO_TRX_NO:事务提交后生成的一个序号,此序号用来标记事务的提交顺序(先提交序号小的,再提交序号大的)
-
TRX_UNDO_DEL_MARKS:标记本组undo日志中是否包含由delete mark操作产生的undo日志
-
TRX_UNDO_XID_EXISTS:本组undo日志是否包含XID信息
-
TRX_UNDO_DICT_TRANS:标记本组undo日志是不是由DDL语句产生的
-
TRX_UNDO_TABLE_ID:如果TRX_UNDO_DICT_TRANS为真,那么本属性表示DDL语句操作的表的id
-
TRX_UNDO_NEXT_LOG:下一组undo日志在页面中开始的偏移量
-
TRX_UNDO_PREV_LOG:上一组undo日志在页面中开始的偏移量
一般来说一个UNDO页面链表只存储一个事务执行过程中产生的一组undo日志。但是某些情况下可能会在一个事务提交后链表被后续事务重复利用,这就会导致一个UNDO页面中可能存放多组undo日志。这两个属性就是用来标记上下组的偏移量。
-
TRX_UNDO_HISTORY_NODE:代表一个HISTORY链表的节点
重用UNDO页面:
每个事务都会单独分配相应的UNDO页面链表,最多可能分配四个链表,这对于一些只产生很少undo日志的事务而言,会导致有些浪费。因此InnoDB决定在事务提交后的某些情况下重用该事物的UNDO页面链表,一个链表可以被重用需要满足以下条件:
- 链表中只包含一个UNDO页面:如果有很多页面的话,那么新的事务要是只产生少量的undo日志,也得去维护非常多的页面,即使后面的页面用不到也不能被别的事务所使用,这就造成了另一种浪费
- 该页面已经使用的空间小于整个页面空间的3/4:如果已经占用了绝大多数部分的空间,那么重用也得不到什么好处
此外insert undo链表和update undo链表在重用时的策略是不同的:
- insert undo链表只存储TRX_UNDO_INSERT_REC的undo日志,这种类型的undo日志在事务提交之后就没用了,可以被清除掉。因此在某个事务提交后,在重用insert undo链表时,可以直接把之前事务写入的一组undo日志覆盖掉,从头开始写新事务的一组undo日志。当然还会调整Undo Page Header、Undo Log Segment Header、Undo Log Header等,
- update undo链表中的undo日志在事务提交后是不能立即删除的,所以不能覆盖之前事务写入的undo日志,只能在后面追加写入。这样就相当于在同一个Undo页面中写入了多组undo日志,所以其中不止一个Undo Log Header。
五、回滚段
1、回滚段的结构
系统在同一时刻其实可能会有很多个UNDO页面链表,为了更好地管理这些链表,**InnoDB设计了一个名为Rollback Segment Header的页面,这个页面中存放了各个UNDO页面链表的first undo page的页号,这些页号称为undo slot。InnoDB规定每一个Rollback Segment Header页面都对应着一个段,这段就成为回滚段。与B+树叶子节点段或非叶子节点段不同的是,这种段只有一个页面。**Rollback Segment Header页面的结构如下:
- File Header:页的通用结构,不再赘述
- TRX_RSEG_MAX_SIZE:这个回滚段中管理的所有UNDO页面链表中的UNDO页面数量之和的最大值。即所有UNDO页面链表中的UNDO页面数量不能超过这个值,这个值默认为0xFFFFFFFE
- TRX_RSEG_HISTORY_SIZE:History链表占用的页面数量
- TRX_RSEG_HISTORY:History链表的基节点
- TRX_RSEG_FSEG_HEADER:这个回滚段对应的Segment Header结构
- TRX_RSEG_UNDO_SLOTS:各个UNDO页面链表的first undo page的页号集合
2、从回滚段申请UNDO页面链表
在初始情况下,由于未向任何实物分配任何UNDO页面链表,所以对于一个Rollback Segment Header页面来说,各个undo slot都指向FIL_NULL(对应0xFFFFFFFF)。当有事务需要分配UNDO链表时,就从回滚段的第一个undo slot开始,查看其是否为FIN_NULL:
- 如果是,则在表空间中新创建一个段,然后从段中申请一个页面作为UNDO页面链表的first undo page,最后把该undo slot的值设置为刚刚申请的这个页面的页号
- 如果不是,则说明这个undo slot已经被别的事务占用了,则继续遍历下一个
一个Rollback Segment Header页面中包含1024个undo slot,如果都分配完了,那么此时新的事务就无法再获得新的UNDO页面链表,这个时候就会停止这事务并向用户报错。
当一个事务提交时,它所占用的undo slot有两种命运:
-
如果该undo slot指向的UNDO页面链表符合被重用的条件,该undo slot就处于被缓存的状态,将链表的TRX_UNDO_STATE属性更改为TRX_UNDO_CACHED
- 被缓存的undo slot都会根据UNDO链表的类型被加入到一个链表中,如果是insert undo链表则该undo slot会被加入insert undo cached链表中,如果是update undo链表,则该undo slot会被加入到update undo cached链表中
- 一个回滚段对应着上述两个cached链表,如果有新事务要分配undo slot,都先从对应的cached链表中找
-
如果undo slot指向的UNDO页面链表不符合被重用的条件,则根据该undo slot对应的UNDO页面链表的不同进行不同的处理:
- 如果是insert undo链表,则该UNDO页面链表的状态会设置为TRX_UNDO_TO_FREE,之后该页面链表对应的段会被释放掉(也就是说段中的页可以被挪作他用),然后把该undo slot置为FIL_NULL
- 如果对应的UNDO页面链表是update undo链表,则该UNDO页面链表的状态会被设置为TRX_UNDO_TO_PURGE(不会释放),并将该undo slot的值设置为FIL_NULL,然后本次事务写入的一组undo日志被放到History链表中
3、多个回滚段
一个回滚段只能容纳1024个undo slot,因此InnoDB定义了128个回滚段。每个回滚段都对应着一个Rollback Segment Header页面,128个回滚段则有128个该页面。这些页面存储在了系统表空间的第五号页面中,该页面的某个区域中包含了128个8字节大小的格子,每个格子由两部分组成:
- Space ID:表空间ID
- Page number:页号
即每个格子相当于一个指针,指向某个表空间的某个Rollback Segment Header页面。
这128个回滚段可以分为两大类:
- 第0号、第33-127号回滚段属于一类。其中0号回滚段必须在系统表空间中,第33-127号段既可以在系统表空间中,也可以再自己配置的undo表空间中
- 第1-32号回滚段属于一类,这些回滚段必须在临时表空间中
之所以要针对普通表和临时表来划分不同种类的回滚段,是因为写undo日志本质上也是一个写页面的过程,因此对undo页面的改动也需要记录相应类型的redo日志。但是对于临时表来说,因为修改临时表而产生的undo日志只需要在系统运行过程中有效,系统崩溃是不需要恢复的。所以在针对临时表写undo页面时,不需要记录相应的redo日志。因此将这两种类型做了区分。
4、roll_pointer
聚集索引记录中包含一个名为roll_pointer的隐藏列,有些类型的undo日志包含一个名为roll_pointer的属性,这个属性本质上就是一个指针,它指向一条undo日志的地址。roll_pointer由7个字节组成,共包含4个属性:
- is_insert:表示该指针指向undo日志是否是TRX_UNDO_INSERT大类的undo日志
- resg id:表示该指针指向的undo日志的回滚段编号(根据编号到系统表空间的五号页面就能找到回滚段,也就知道了段是在哪个表空间)
- page number:表示该指针指向的undo日志所在页面的页号
- offset:表示该指针指向的undo日志在页面中的偏移量
根据roll_pointer就可以很轻松的定义到一条具体的undo日志
5、为事务分配UNDO页面链表的详细过程
- 事务在执行过程中对普通表的记录进行首次改动之前,首先会到系统表的第五号页面中分配一个回滚段(其实就是获取一个Rollback Segment Header页面的地址)。一旦某个回滚段被分配给了这个事务,那么之后该事务再对普通的表的记录进行改动时(UNDO页面链表的首节点记录了生成本组undo日志的事务ID),就不会再重复分配了。分配使用的是round-robin(循环使用)的方式,在0和34-127这个区间中循环
- 在分配到回滚段后,首先看一下这个回滚段的两个cached链表有没有已经缓存的undo slot。如果事务执行的是insert操作,则去insert undo cached链表中查看,否则则去update undo cached链表中查看。如果有缓存的undo slot,就把这个缓存的undo slot分配给该事务
- 如果没有缓存的undo slot,则到Rollback Segment Header页面中找一个可用的undo slot分配给当前事务
- 找到可用的undo slot后,如果其是从cached链表中获取的,则对应的Undo Log Segment已经分配了,否则需要重新分配一个Undo Log Segment,然后从该Undo Log Segment中申请一个页面作为undo页面链表的first undo page,并把该页的页号填入获取的undo slot中
- 然后事务就可以把undo日志写入到上面申请的undo链表中了
六、undo日志在崩溃恢复时的作用
服务器因为崩溃而恢复的过程中,首先需要按照redo日志将各个页面的数据恢复到崩溃之前的状态,这样可以保证已经提交的事务的持久性。但是这里仍然存在一个问题,就是那些没有提交的事务写的redo日志可能也已经刷盘,那么这些未提交的事务修改过的页面在MySQL服务器重启时可能也被恢复了。所以这个时候就需要使用undo日志来将这些未提交的修改进行回滚。
我们可以通过系统表空间的第五号页面定位到128个回滚段的位置,在每一个回滚段的1024个undo slot中找到那些值不为FIL_NULL的undo slot,每一个undo slot对应着一个UNDO页面链表。然后从UNDO页面链表的第一个页面的Undo Log Segment Header中找到TRX_UNDO_STATE属性,该属性标识当前undo页面链表所处的状态。如果该属性的值为TRX_UNDO_ACTIVE,那么意味着有一个活跃的事务正在向整个UNDO页面链表中写入undo日志。然后再在Undo Segment Header中找到TRX_UNDO_LAST_LOG属性,通过该属性可以找到本UNDO页面链表最后一个Undo Log Header的位置。从该Undo Log Header中可以找到对应事务的事务id以及一些其他信息,则该事务id对应的事务就是未提交的事务。通过undo日志中记录的信息将该事务页面所做的更改全部回滚掉,这样就保证了事务的原子性。
参考资料:
事务回滚 原子性 undo日志 回滚段 什么时候删除undo日志 - 知乎 (zhihu.com)
《MySQL是怎样运行的——从根上理解MySQL》