本讲将介绍主成分分析(Principal Component Analysis,PCA),主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息,一般来说,当研究的问题涉及到多变量且变量之间存在很强的相关性时,我们可以考虑使用主成分分析的方法来对数据进行简化。
(将多个指标转换为少数几个主成分)
问题的提出:
对于变量多,分析时难度大=>因此用较少新变量代替原来较多就变量。
数据降维的作用:
主成分分析的思想:


严谨的数学符号:

PCA的计算步骤(理论步骤):


案列1
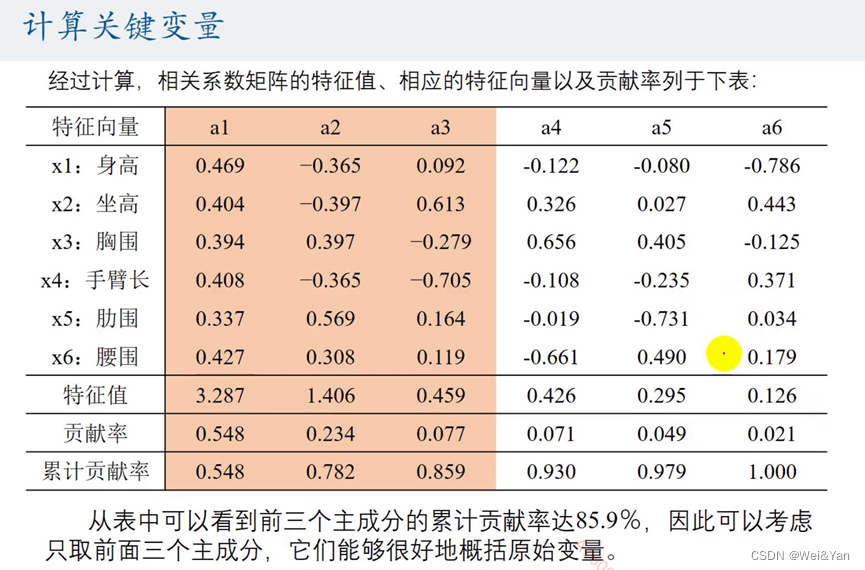
计算关键变量:
一般看累积贡献率,一般选择累积贡献率较大且所选变量少时情况。如下图的累积贡献率到第三个时已经为85.9%,后面的已经相对增加的趋势较少说明后面变量的贡献率相对较少可以不用考虑。
写出主成分并简要分析:
主成分分析的说明:
案例2:
计算关键变量: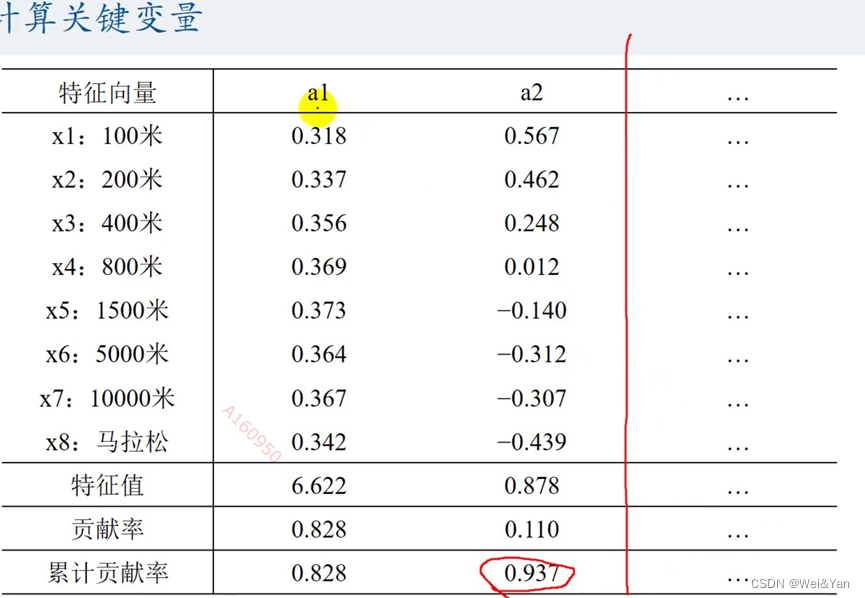
对主成分分析:
主成分分析的MATLAB代码实现:
- 标准化数据。利用函数zscore(数据)
- 计算标准化后样本的协方差。函数cov(标准化后数据)
补:在我们进行完1,2步后得到了样本相关系数矩阵,可对其相关系数进行可视化。
步骤:
a.复制相关系数矩阵->excel,调整表格的行高列宽。
b.色阶->三色表->管理规则->编辑规则->修改数字,范围->应用。

让我们继续回到matlab的操作:
3.根据PCA计算步骤,接下来计算R(相关系数矩阵)的特征值和特征向量。函数eig(R)。若eig不给返参数,默认只返回特征值。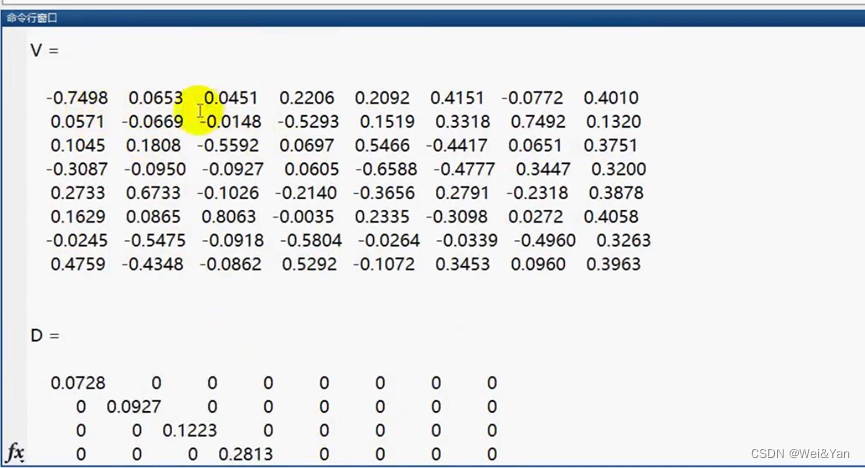
4.计算主成分贡献率和累积贡献率。(计算过程复杂,后期会有代码和注释的补充)
5.根据累积贡献率选择主成分变量的个数,并且进行主成分变量的计算。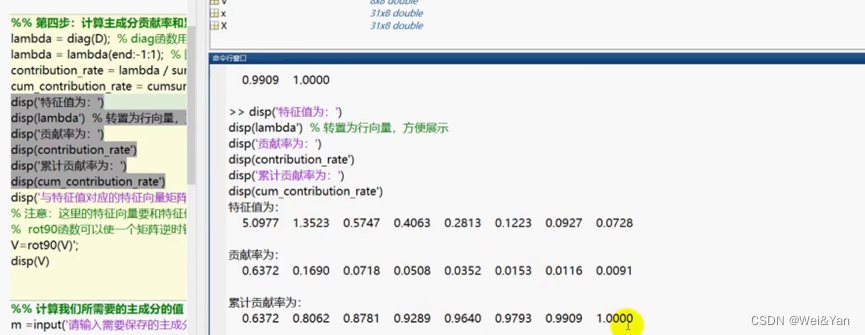
6.根据实际问题选择,如果为聚类模型则将数据复制到excel,再用spss解决;如果为主成分回归,则还需要计算标准化y值(利用函数zscore),再将得到的标准化y和主成分变量F1,F2……Fm复制到excel再导入到stata中进行分析。
Matlab进行主成分分析:
结果的解释:
主成分分析的滥用(了解):
对于聚类问题的主成分分析的使用:
将数据有导入spss中再进行聚类:
(关于聚类模型可以参考博主之前的一篇文章:【数学建模】--聚类模型_Wei&Yan的博客-CSDN博客)
分析-分类-系统聚类-导入重要变量-图-普系图-生成谱系图后根据普系图确定类的个数。
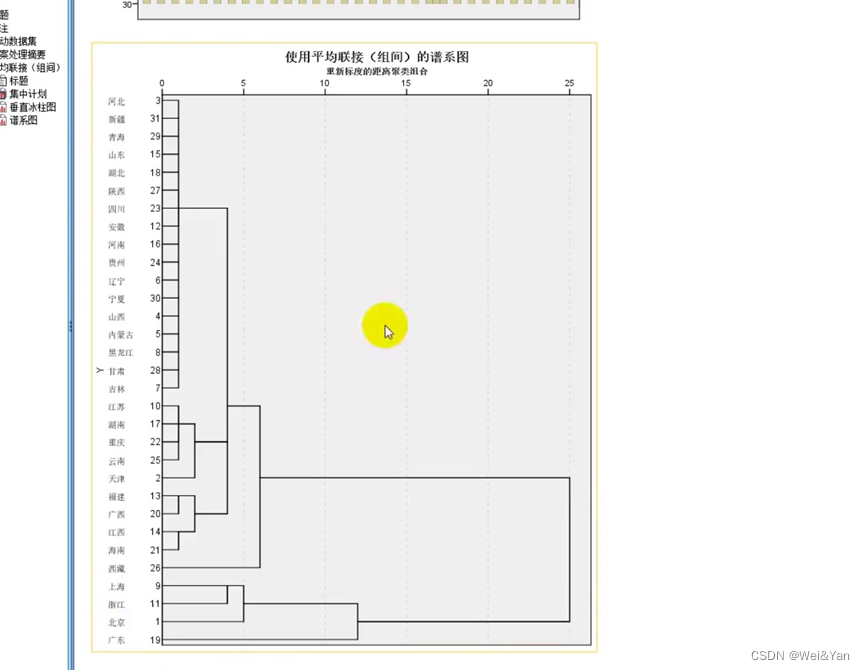
确定类的个数后再重新运行生成散点图:
(在确定类的个数后要手动输入)
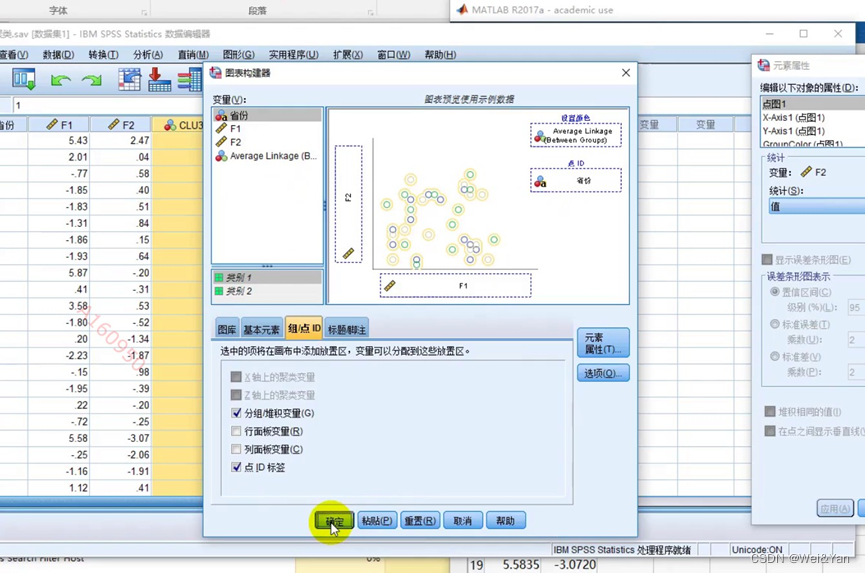

Spss聚类: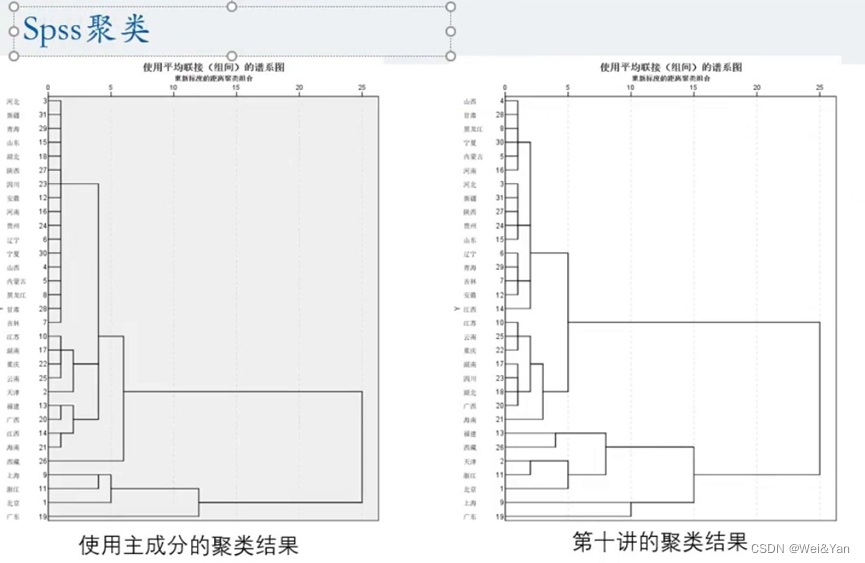
效果图:
主成分回归:
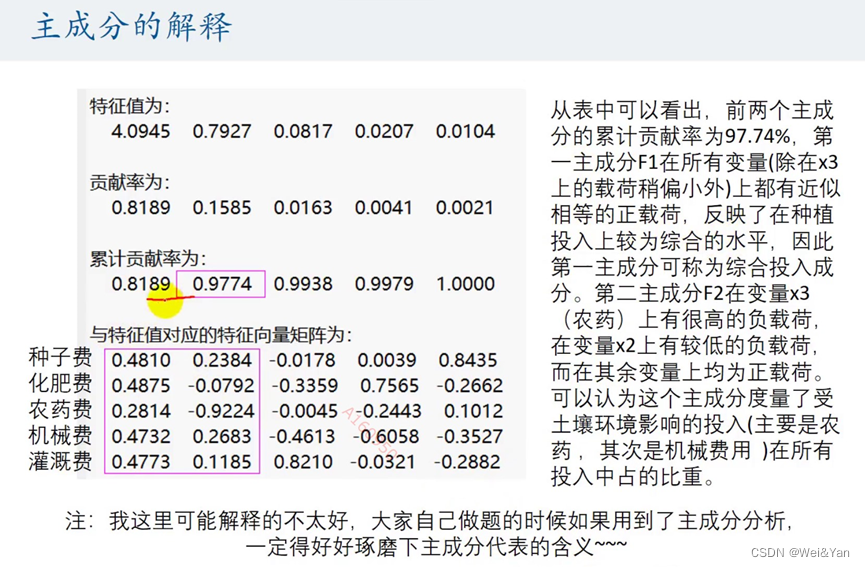
利用Stata来解决主成分回归:
关于主成分回归的看法:
课后作业:
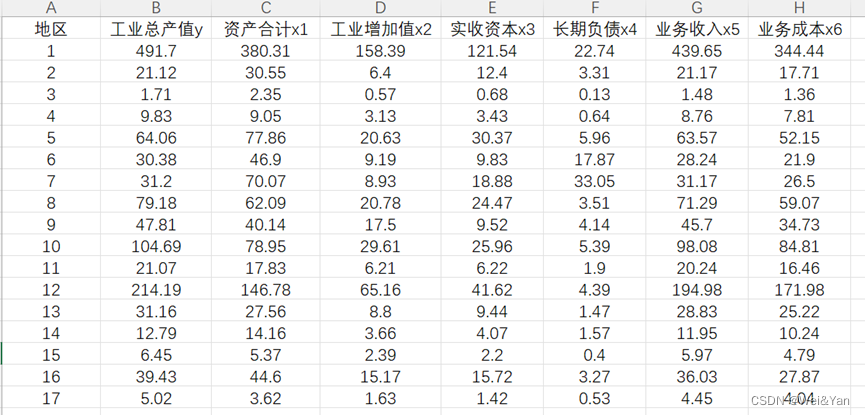
如果不了解多元回归和stata的应用可参考博主的:数学建模—多元线性回归分析(+lasso回归的操作)_Wei&Yan的博客-CSDN博客
- 直接回归,并用异方差(estat imtest,white)和多重共线性检验(estat vif):
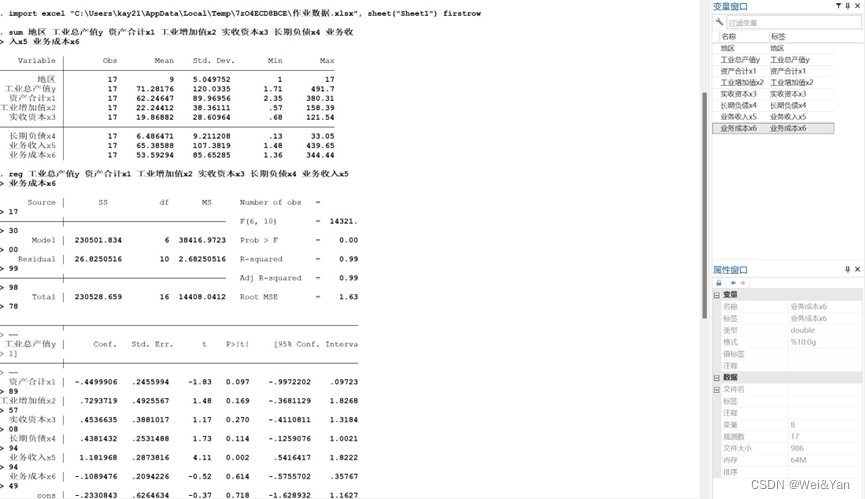

2.逐步回归分析(向后逐步):
3.主成分分析:
观察到前两项的累积贡献率已经较高,所以选择前两项为主成分自变量,得到了标准化后的主成分自变量F1,F2和Y。
将数据导出到excel再导入stata进行分析:
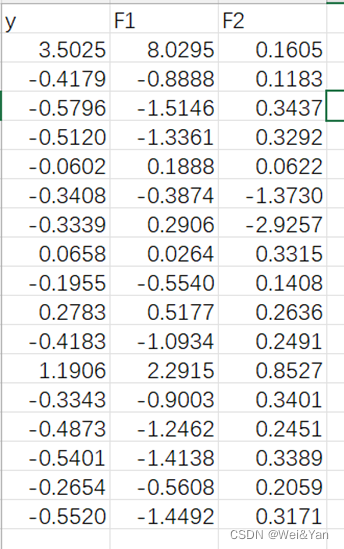
Stata运行结果:
MATLAB代码参考:
clear;clc% 主成分聚类% 主成分回归
load data3.mat%博主在作业测试中的数据。
% 注意,这里可以对数据先进行描述性统计
% 描述性统计的内容见第5讲.相关系数
[n,p] = size(x); % n是样本个数,p是指标个数%% 第一步:对数据x标准化为X
X=zscore(x); % matlab内置的标准化函数(x-mean(x))/std(x)%% 第二步:计算样本协方差矩阵
R = cov(X);%% 注意:以上两步可合并为下面一步:直接计算样本相关系数矩阵
R = corrcoef(x);
disp('样本相关系数矩阵为:')
disp(R)%% 第三步:计算R的特征值和特征向量
% 注意:R是半正定矩阵,所以其特征值不为负数
% R同时是对称矩阵,Matlab计算对称矩阵时,会将特征值按照从小到大排列哦
% eig函数的详解见第一讲层次分析法的视频
[V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵%% 第四步:计算主成分贡献率和累计贡献率
lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)
lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头
contribution_rate = lambda / sum(lambda); % 计算贡献率
cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数
disp('特征值为:')
disp(lambda') % 转置为行向量,方便展示
disp('贡献率为:')
disp(contribution_rate')
disp('累计贡献率为:')
disp(cum_contribution_rate')
disp('与特征值对应的特征向量矩阵为:')
% 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来
% rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果
V=rot90(V)';
disp(V)%% 计算我们所需要的主成分的值
m =input('请输入需要保存的主成分的个数: ');
F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)
for i = 1:mai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和
end%% (1)主成分聚类 : 将主成分指标所在的F矩阵复制到Excel表格,然后再用Spss进行聚类
% 在Excel第一行输入指标名称(F1,F2, ..., Fm)
% 双击Matlab工作区的F,进入变量编辑中,然后复制里面的数据到Excel表格
% 导出数据之后,我们后续的分析就可以在Spss中进行。%%(2)主成分回归:将x使用主成分得到主成分指标,并将y标准化,接着导出到Excel,然后再使用Stata回归
%Y = zscore(y); % 一定要将y进行标准化哦~
% 在Excel第一行输入指标名称(Y,F1, F2, ..., Fm)
% 分别双击Matlab工作区的Y和F,进入变量编辑中,然后复制里面的数据到Excel表格
% 导出数据之后,我们后续的分析就可以在Stata中进行。