刻削生千变,丹青图“万相
4月7日,阿里大模型“通义千问”开始邀请用户测试体验。现阶段该模型主要定向邀请企业用户进行体验测试,用户可通过官网申请(tongyi.aliyun.com),符合条件的用户可参与体验。


随后,在2023云峰会上,阿里巴巴集团董事会主席兼CEO、阿里云智能集团CEO张勇表示,阿里巴巴所有产品未来将接入“通义千问”大模型,进行全面改造。他认为,面向AI时代,所有产品都值得用大模型重新升级。
据悉,阿里达摩院在NLP自然语言处理等前沿科研领域早已布局多年,并于2019年启动大模型研发。“通义千问”是基于达摩院“通义”大模型技术研发的类GPT大模型,目前各项功能和体验仍在不断完善中。
“未来所有软件都值得接入大模型升级改造,我们将开放通义千问的能力,为每一家企业打造自己的专属GPT,欢迎所有人用阿里云开发自己的大模型。”阿里云方面表示,未来将提供完备的算力和大模型基础设施,让包括创业公司在内的所有企业和机构更好地实现创新,让中国整体的AI能力有全方位的提升。
达摩院是阿里巴巴集团旗下的研究机构,全名为阿里巴巴达摩院(Alibaba DAMO Academy)。它致力于推动科技创新和前沿技术的研究与应用。达摩院成立于2017年,总部位于中国杭州,同时在全球多个地区设有实验室和研发中心。
达摩院的研究领域广泛涵盖人工智能、大数据、云计算、物联网、安全等多个前沿技术领域。其目标是通过开展前瞻性研究和技术创新,为阿里巴巴集团及整个行业提供技术支持和创新驱动力。
达摩院以“Discovery, Adventure, Momentum, Outlook”为使命,通过开展前瞻性研究和跨学科创新合作,推动科技的进步和商业的发展。同时,达摩院还积极与全球各界合作伙伴建立合作关系,共同推动技术创新和产业变革。

阿里云魔搭社区
https://www.modelscope.cn/docs/%E6%A6%82%E8%A7%88%E4%BB%8B%E7%BB%8D#ModelScope%E6%98%AF%E4%BB%80%E4%B9%88
基本介绍:
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
我们希望在汇集行业领先的预训练模型,减少开发者的重复研发成本,提供更加绿色环保、开源开放的AI开发环境和模型服务,助力绿色“数字经济”事业的建设。 ModelScope平台将以开源的方式提供多类优质模型,开发者可在平台上免费体验与下载使用。
若您也和我们有相同的初衷,欢迎关注我们,我们鼓励并支持个人或企业开发者与我们联系,平台将为您构建更好的支持服务,共同为泛AI社区做出贡献。
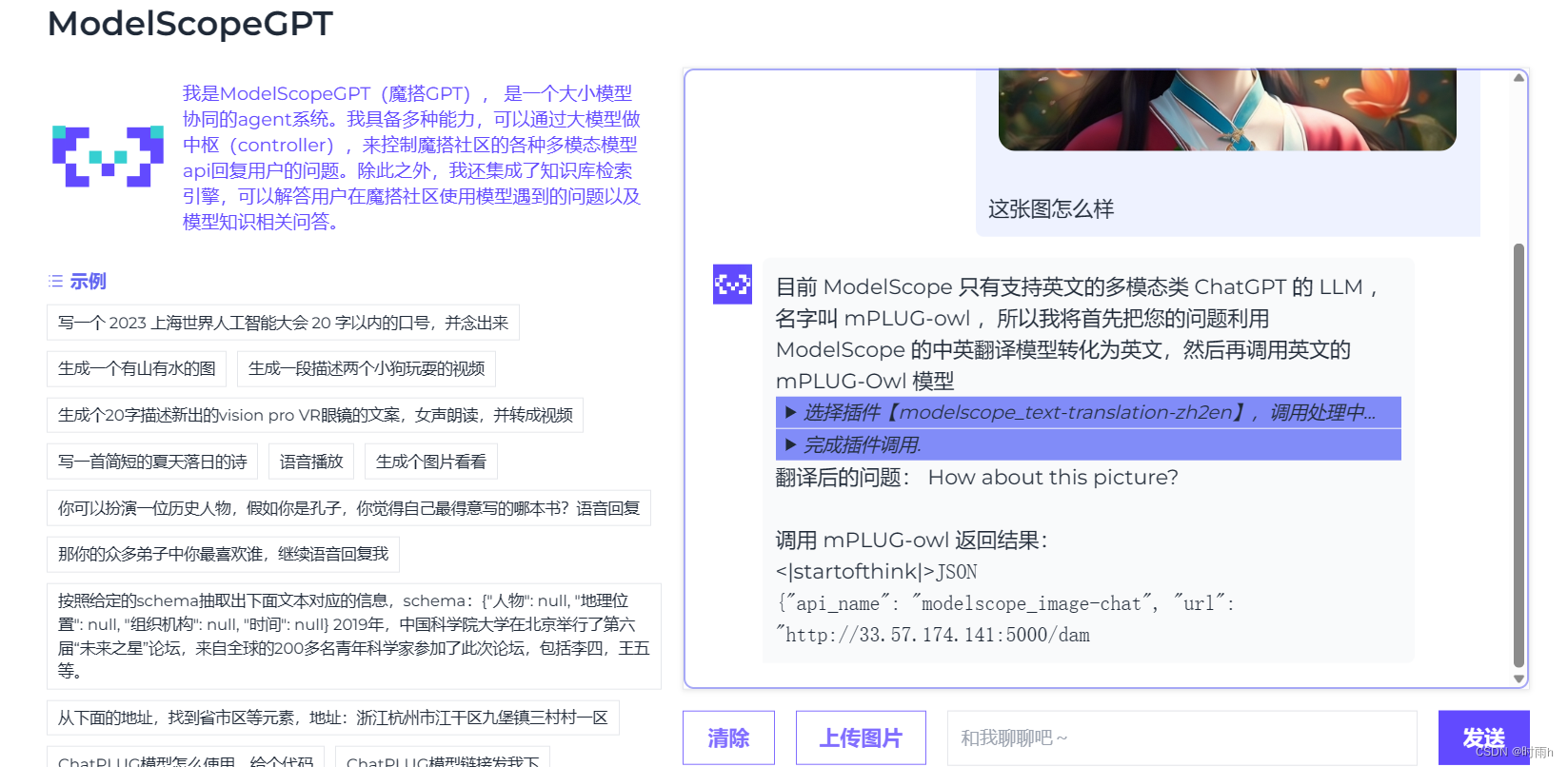
ModelScopeGPT(魔搭GPT)
ModelScope是阿里达摩院于近一年刚上线的一款开源模型平台,里面提供了很多的热门模型供使用体验,而且与阿里云服务进行联动,不需要额外部署机器进行模型的运行调试,即可自动在阿里云进行实例创建。
ModelScopeGPT(魔搭GPT), 是一个大小模型协同的agent系统。我具备多种能力,可以通过大模型做中枢(controller),来控制魔搭社区的各种多模态模型api回复用户的问题。除此之外,我还集成了知识库检索引擎,可以解答用户在魔搭社区使用模型遇到的问题以及模型知识相关问答。

AI绘画原理
AI绘画的原理基于深度学习技术,主要使用了生成对抗网络(GAN)或变分自编码器(VAE)等模型。
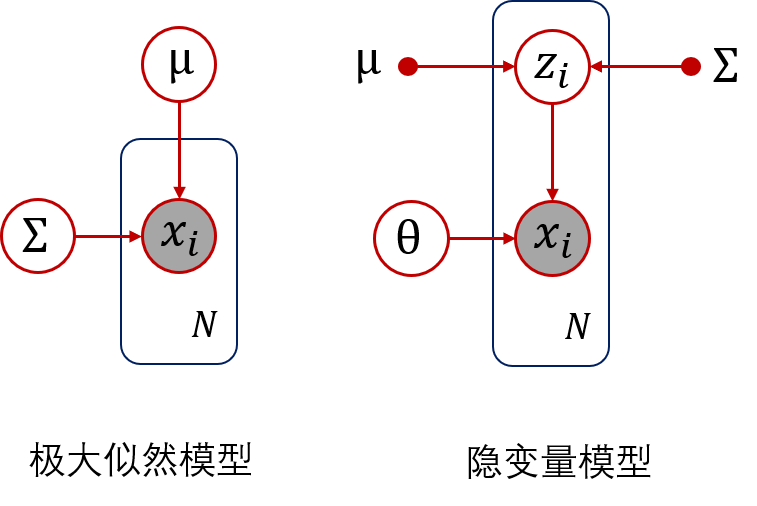
首先,AI绘画的过程通常需要大量的训练数据。这些数据可以是真实的绘画作品、艺术家的风格或其他图像资源。这些数据被用来训练深度学习模型,以学习绘画的特征和风格。
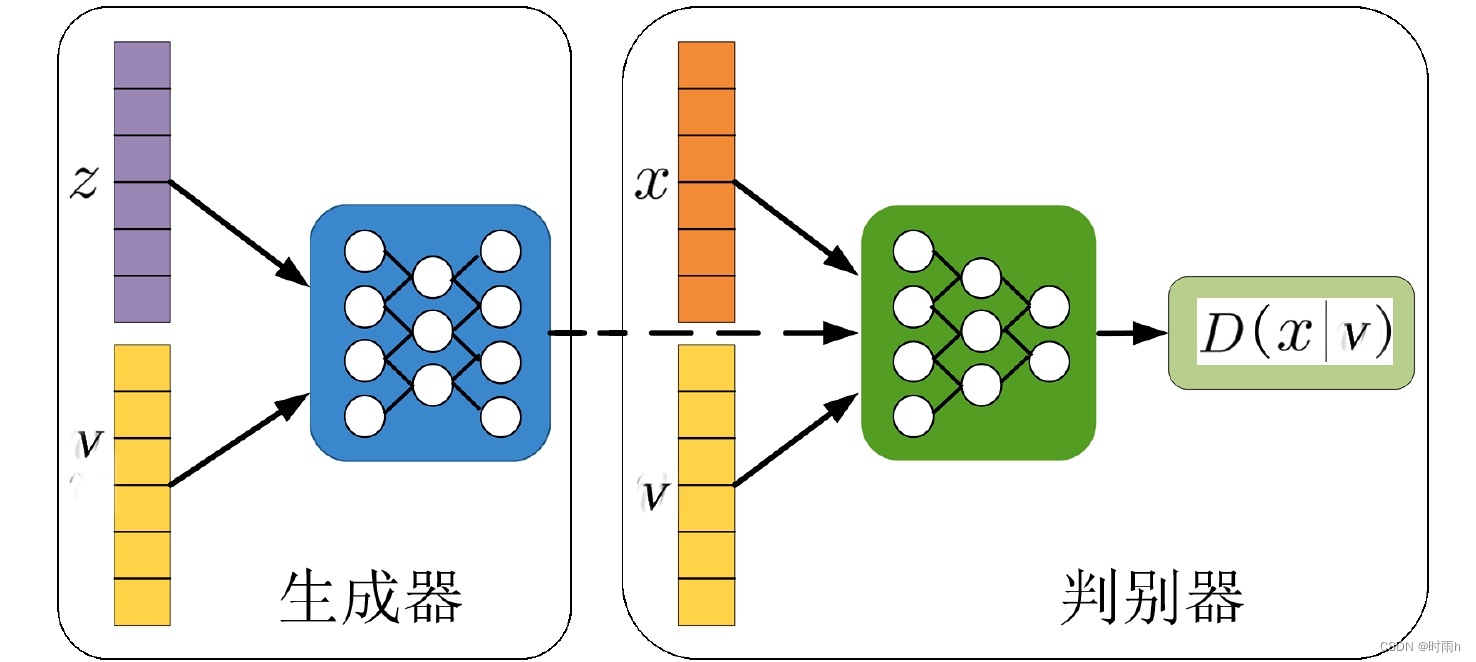
在训练阶段,生成对抗网络(GAN)经常被用来生成逼真的绘画作品。GAN由两个主要的部分组成:生成器和判别器。生成器尝试生成看起来像真实绘画的图像,而判别器则试图区分生成器生成的图像和真实的图像。通过不断的对抗训练,生成器和判别器相互协作,最终生成器能够生成高质量的绘画作品。
在生成阶段,一旦训练完成,生成器可以接受用户输入的各种指引,如风格、主题、颜色等,然后根据这些指引生成相应的绘画作品。生成器利用已学习到的知识和模式,以及对输入的理解,创造出新的图像。
需要注意的是,AI绘画并非简单的图像复制或机械式的模仿,而是通过模型对训练数据进行学习,并在生成阶段进行创造性的创作。AI绘画的结果可以根据用户的需求和输入的不同而产生差异,从而展现出一定的艺术性和创造性。
虽然AI绘画在某种程度上能够模拟人类艺术家的风格和技巧,但它仍然受限于训练数据的质量和模型的能力。因此,在生成的过程中可能会存在一些不完美或不符合期望的结果。

当涉及到AI绘画的深度学习模型时,还有其他一些方法和技巧可以用来提高生成的绘画质量和艺术效果。
-
风格迁移:通过将输入图像与已知艺术风格的图像进行结合,可以实现风格迁移,即将输入的图像按照指定的艺术风格重新绘制。这个过程可以通过卷积神经网络(CNN)来实现,并采用预训练的模型来提取图像的特征。
-
注意力机制:为了使生成的绘画更具视觉效果和细节,可以引入注意力机制,使生成的模型能够重点关注图像中的重要区域。通过学习图像的关键部分,模型可以更好地捕捉细节,并产生更加逼真的绘画效果。
-
数据增强:为了获得更多样化和丰富的绘画效果,可以使用数据增强技术扩展训练数据。数据增强技术包括图像旋转、缩放、翻转等操作,可以使模型更好地泛化并生成多样化的绘画作品。
-
模型融合:通过结合不同的深度学习模型和技术,可以改善生成的绘画质量。例如,将生成对抗网络(GAN)与变分自编码器(VAE)相结合,可以在保持细节的同时产生更具艺术感的绘画效果。
总的来说,AI绘画的原理是基于深度学习技术,通过对大量训练数据的学习和模型的优化,实现了自动生成绘画作品的能力。随着技术的不断进步和创新,AI绘画的质量和艺术性将逐渐提高,为艺术创作和创意产业带来新的可能性。
阿里云ai绘画工具通义万相测评
刻削生千变,丹青图“万相”


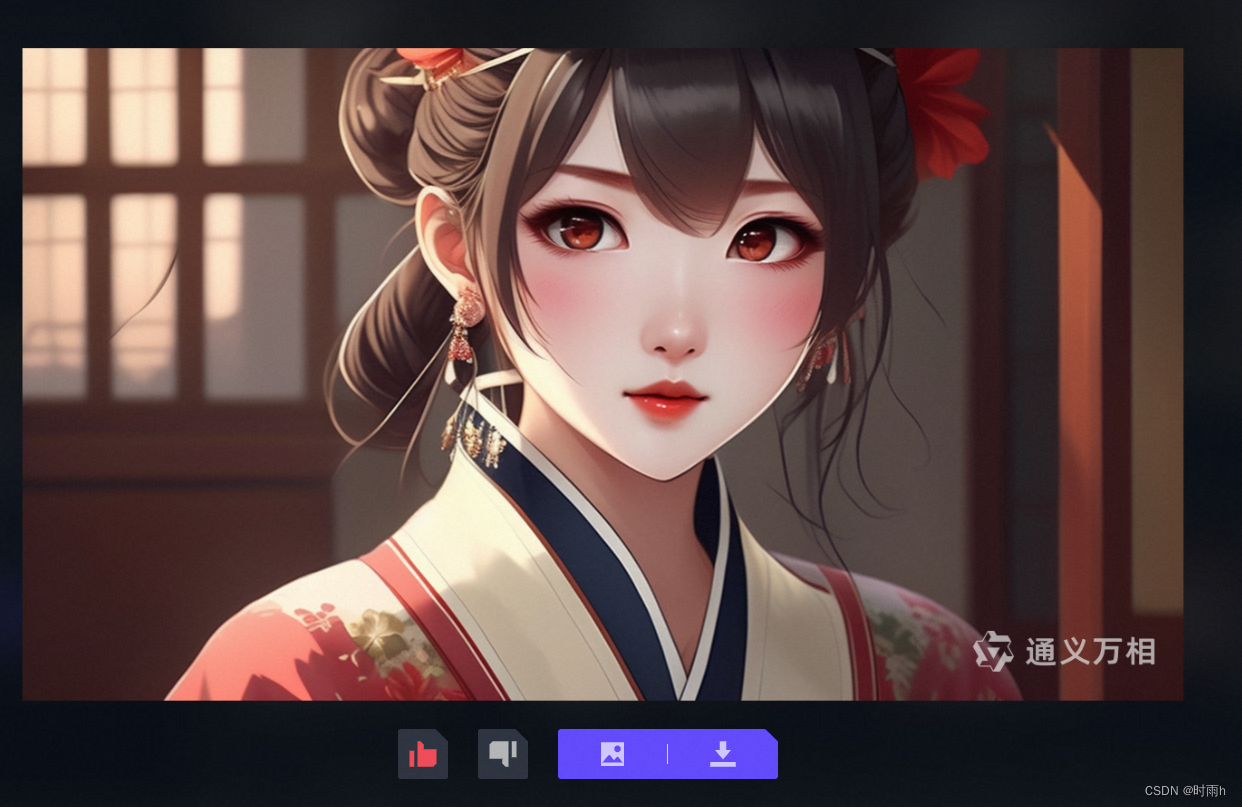
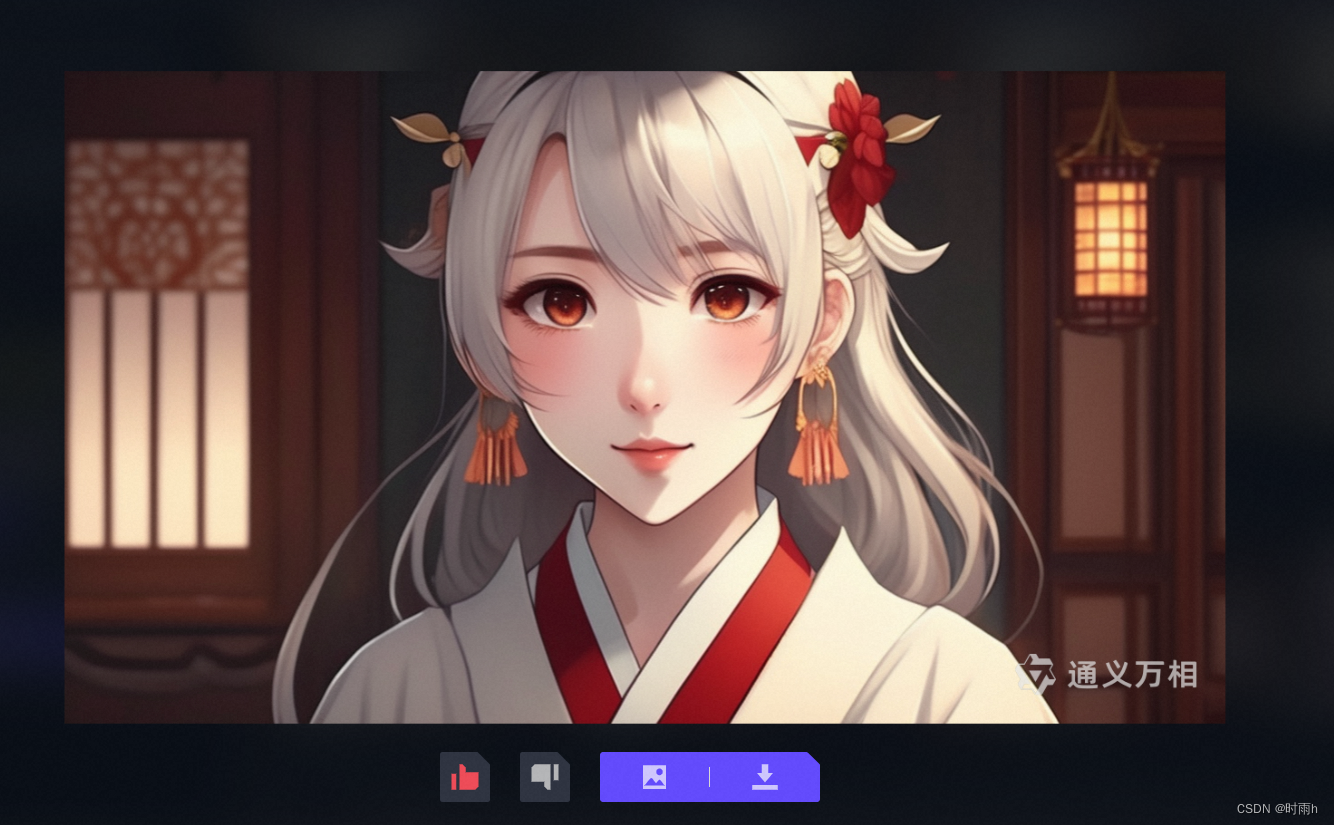
文本生成图像示例
试问闲愁都几许?一川烟草,满城风絮,梅子黄时雨。


吾家有娇女,皎皎颇白皙。小字为纨素,口齿自清历。鬓发覆广额,双耳似连璧。明朝弄梳台,黛眉类扫迹。浓朱衍丹唇,黄吻烂漫赤
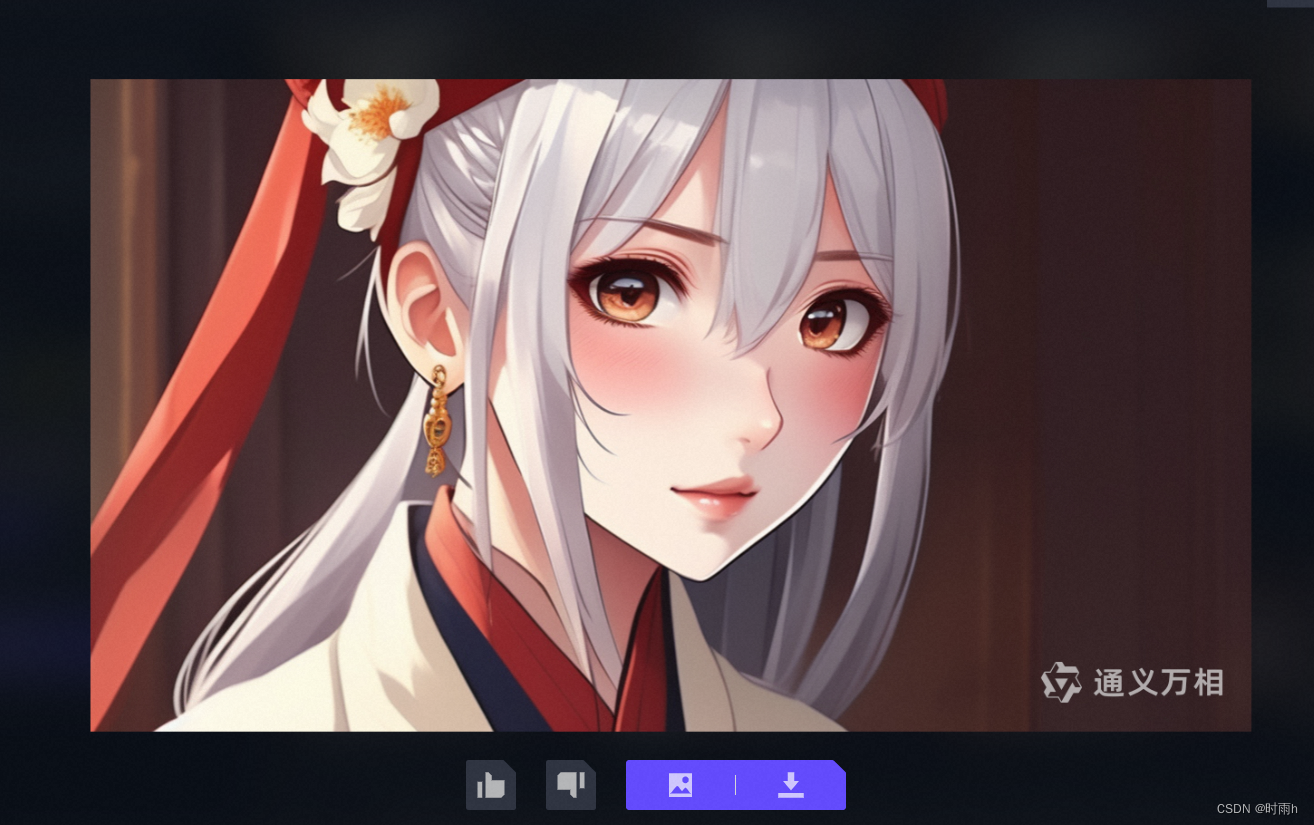
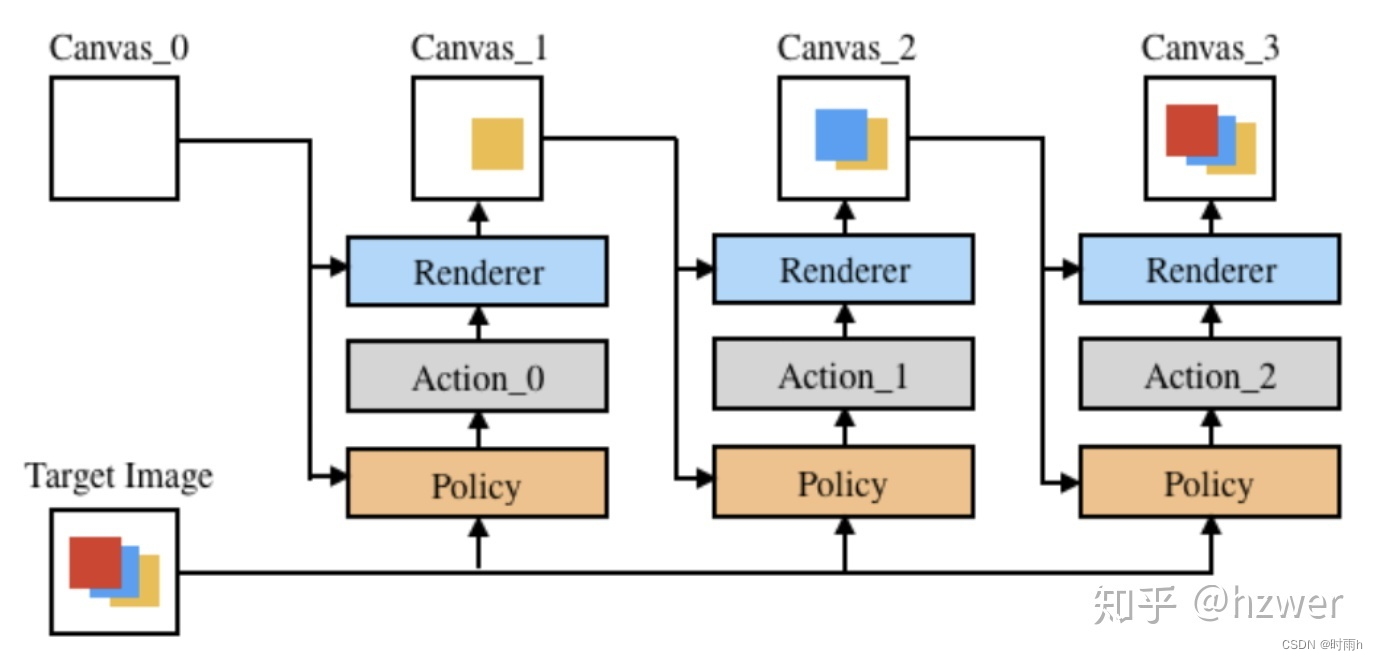
AI文本生成图像的原理可以通过以下步骤进行解释:
-
数据准备:首先,需要准备一个用于训练的数据集。这个数据集可以是包含图像和对应文本描述的配对数据,也可以是只包含文本描述的数据集。对于图像和文本配对的数据集,可以使用已有的图像识别和标注工具进行人工标注;对于仅有文本描述的数据集,可以利用自然语言处理技术对文本进行预处理和特征提取。
-
深度学习模型:接下来,需要构建一个深度学习模型,常见的模型包括循环神经网络(RNN)或变种(如长短期记忆网络 LSTM 或门控循环单元 GRU)和转换器模型。这些模型通常由编码器和解码器组成,编码器负责将文本输入转化为一个中间表示,而解码器则负责从中间表示生成图像。
-
训练过程:在训练过程中,将上一步准备好的数据集输入到深度学习模型中进行训练。训练过程中,模型会逐渐学习到文本描述与图像之间的关联性,并试图根据给定的文本生成相应的图像。
-
生成图像:在训练完成后,可以使用已经训练好的模型进行图像生成。给定一个文本描述,将其输入到训练好的解码器中,解码器会生成对应的图像。生成的图像可以根据需要进行后处理,如调整颜色、大小等。
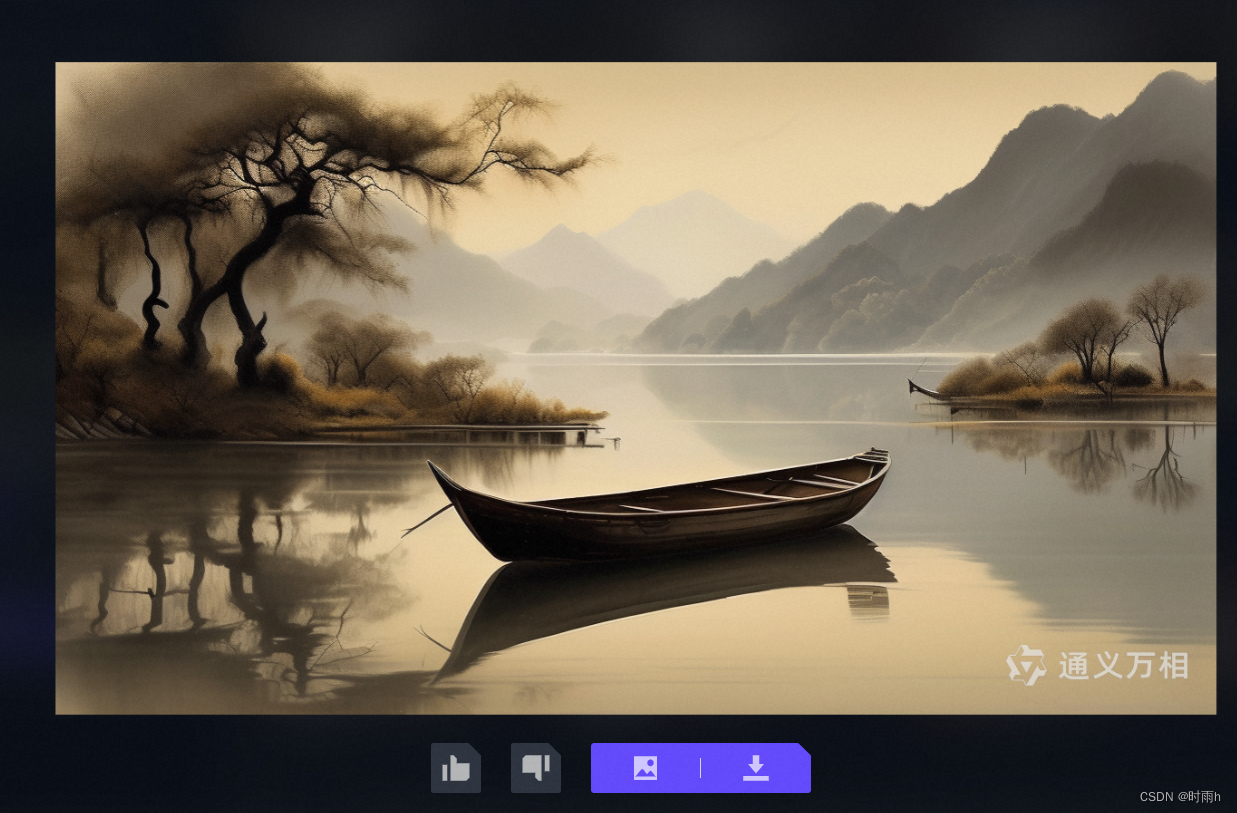
长恨此身非我有,何时忘却营营。
夜阑风静縠纹平。小舟从此逝,江海寄余生。
临江仙 · 夜归临皋 宋 ⋅ 苏轼

.三月三日天气新,长安水边多丽人,态浓意远淑且真,肌理细腻骨肉匀。(杜甫)




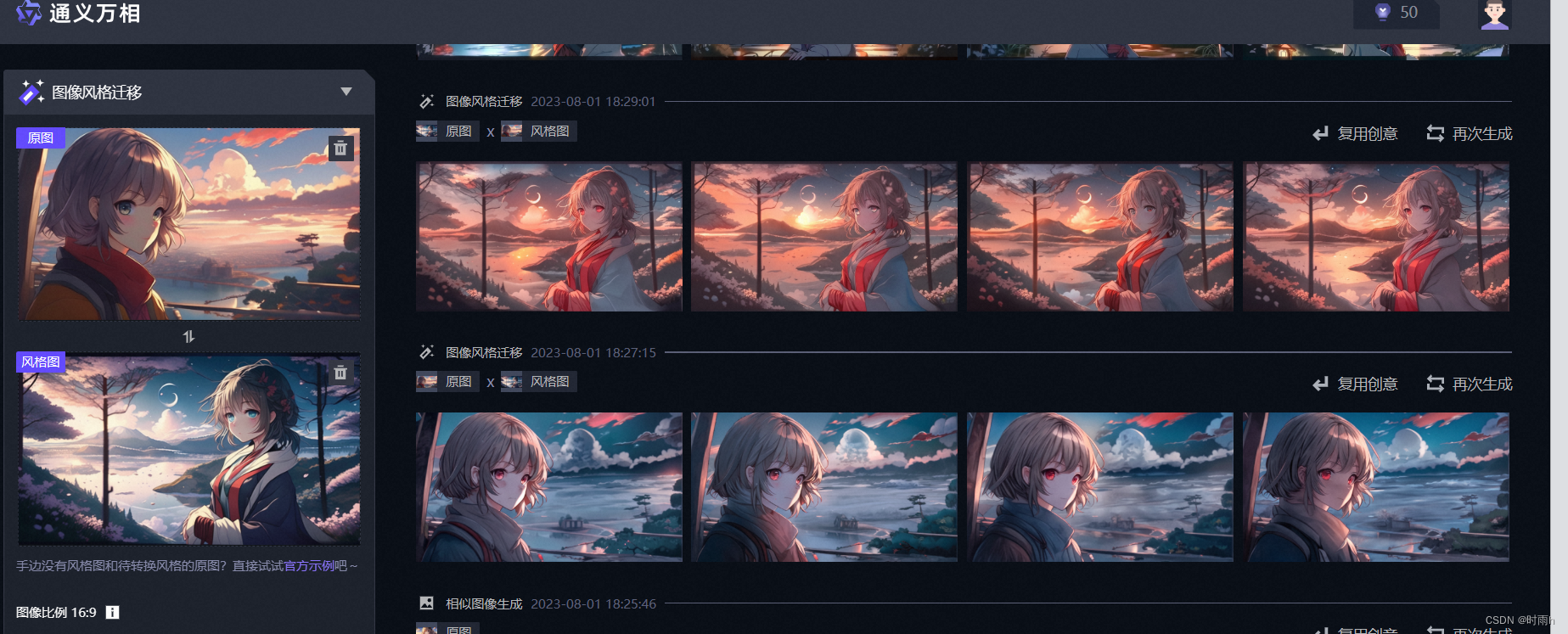
图像风格迁移示例
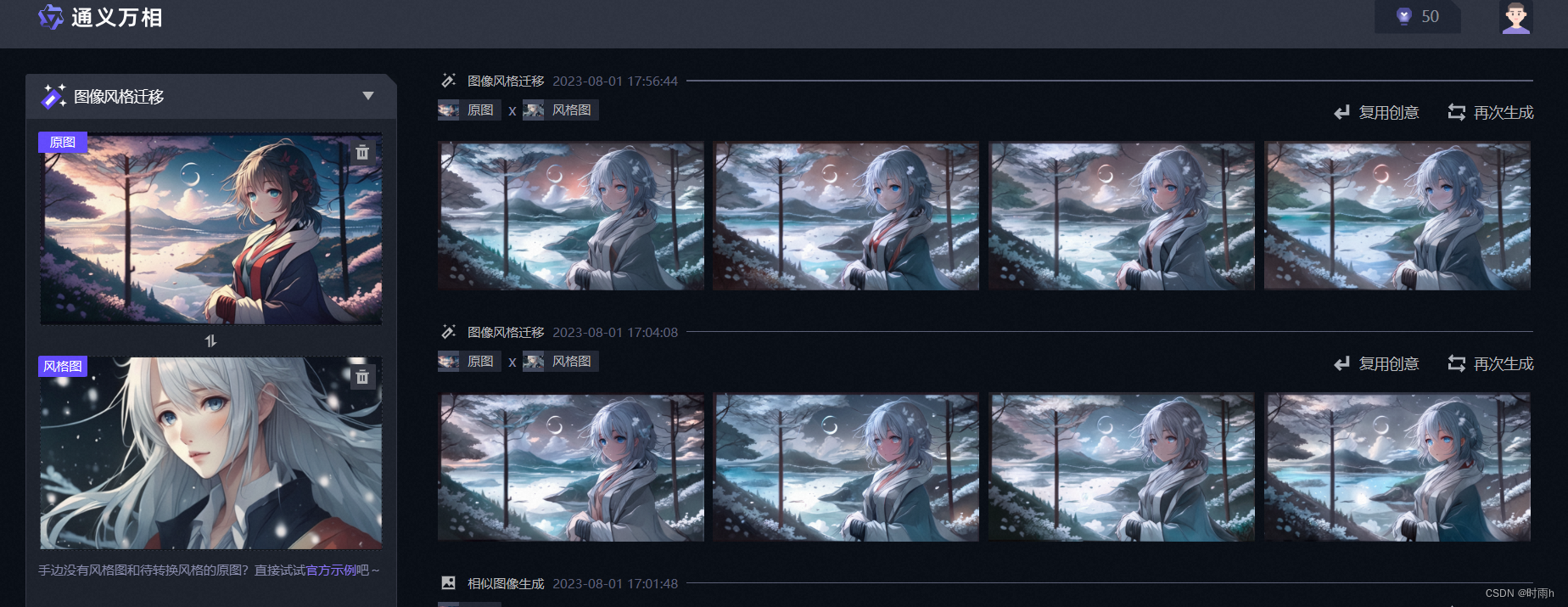
AI绘画图像风格迁移是一种基于人工智能技术的图像处理方法,通过将一张图像的风格应用到另一张图像上,从而创造出具有新风格的图像。下面是该方法的详细介绍:
-
神经网络结构:AI绘画图像风格迁移的核心是使用卷积神经网络(Convolutional Neural Network, CNN)。CNN是一种深度学习网络,它可以学习并提取图像中的特征。
-
风格损失函数:在风格迁移中,需要定义一个风格损失函数来衡量两个图像之间的风格差异。这通常使用Gram矩阵来计算,Gram矩阵描述了图像的纹理和颜色信息。
-
内容损失函数:为了保留原始图像的内容,需要定义一个内容损失函数来衡量两个图像之间的内容差异。这通常使用卷积层的输出特征来计算。
-
训练过程:在图像风格迁移中,首先需要训练一个基于CNN的模型来提取图像的特征。训练时使用大量的图像数据集,并通过反向传播算法不断调整模型的参数,使其能够准确地提取图像的特征。
-
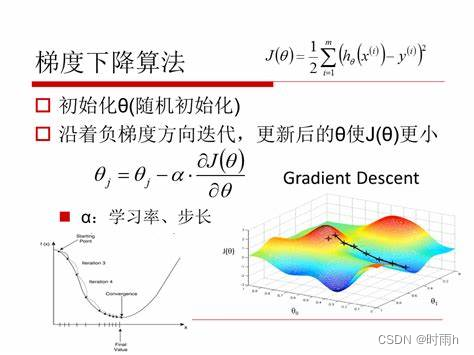
风格迁移过程:在训练完成后,使用训练好的模型来进行风格迁移。给定一张内容图像和一张风格图像,通过优化算法不断调整内容图像的像素值,使其在内容损失函数和风格损失函数的约束下,尽可能接近目标风格。
-
优化算法:通常使用梯度下降法或变种来优化风格迁移过程中的损失函数。梯度下降法通过迭代地调整像素值,使损失函数逐渐减小,从而达到最佳的风格迁移效果。
AI绘画图像风格迁移利用卷积神经网络提取图像的特征,并通过定义风格损失函数和内容损失函数来实现图像的风格迁移。这种方法可以生成具有新风格的图像,丰富了图像处理的应用领域。
相似图像生成示例
AI相似图像生成的原理可以通过以下步骤进行解释:
-
数据准备:首先,需要准备一个包含大量图像样本的数据集。这些图像可以是同一类别或相似主题的图片。对于每个图像样本,还需要提取其特征表示,常用的方法有使用卷积神经网络(CNN)提取图像的特征向量。
-
特征表示学习:接下来,使用深度学习模型进行特征表示学习。通过将图像样本输入到预训练的CNN模型中,可以获得每个图像的特征向量。这些特征向量捕捉了图像的重要信息和特征。
-
相似度度量:在得到图像的特征表示后,需要计算图像之间的相似度。常用的相似度度量方法包括欧氏距离、余弦相似度等。通过计算两个特征向量之间的距离或相似度,可以衡量它们在特征空间中的相似程度。
-
图像生成:通过选取一个或多个目标图像作为输入,可以使用特征表示和相似度度量来生成相似的图像。具体的方法可以是在特征空间中搜索与目标图像最相似的特征向量,然后利用解码器将该特征向量转换为图像。另一种方法是通过生成模型(如生成对抗网络 GAN)生成新的图像,并使用目标图像的特征向量作为条件或引导进行生成。
-
调整和优化:生成的相似图像可能需要进一步的调整和优化,以使其更加符合期望。这可以包括调整颜色、大小、纹理等图像属性,或者使用其他技术(如风格迁移)将图像的风格与目标图像匹配。

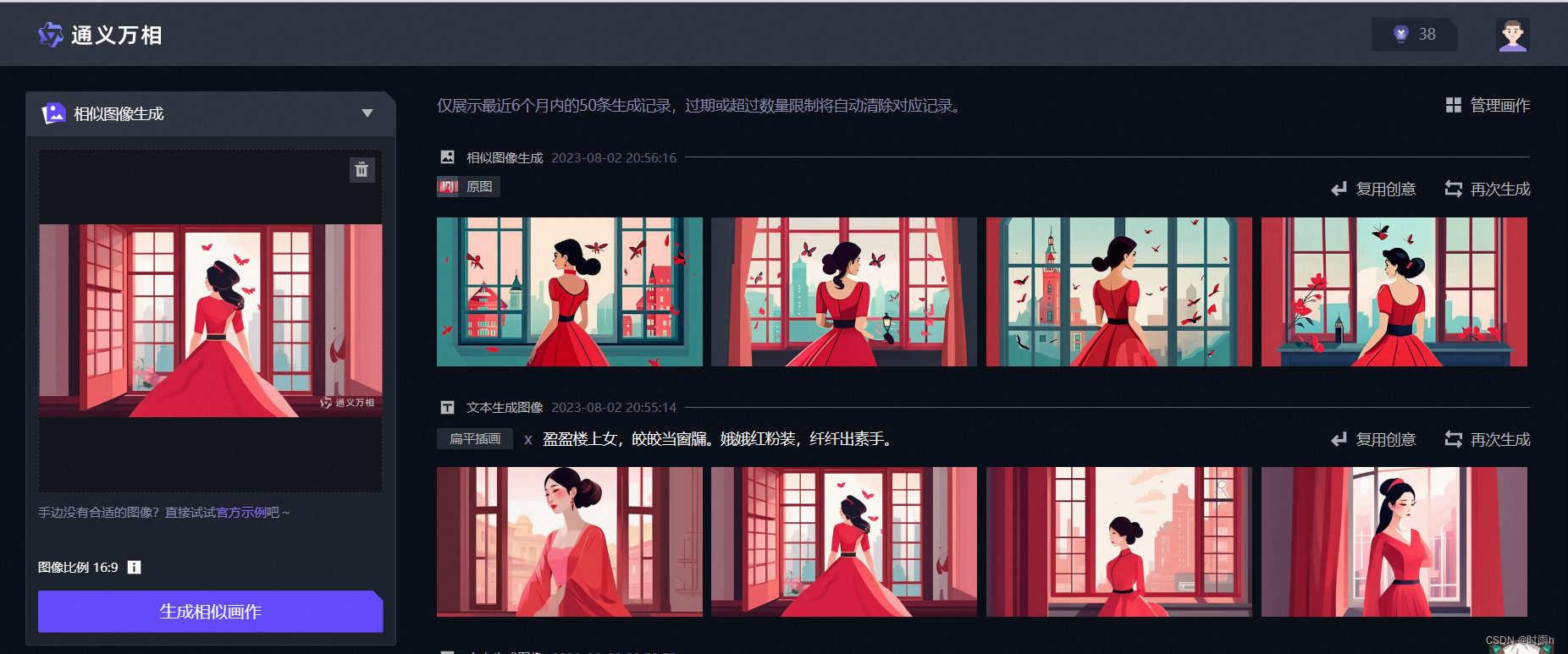

测评出现的一些问题


关键词给的不够明确时很容易出现这种很类似的画面
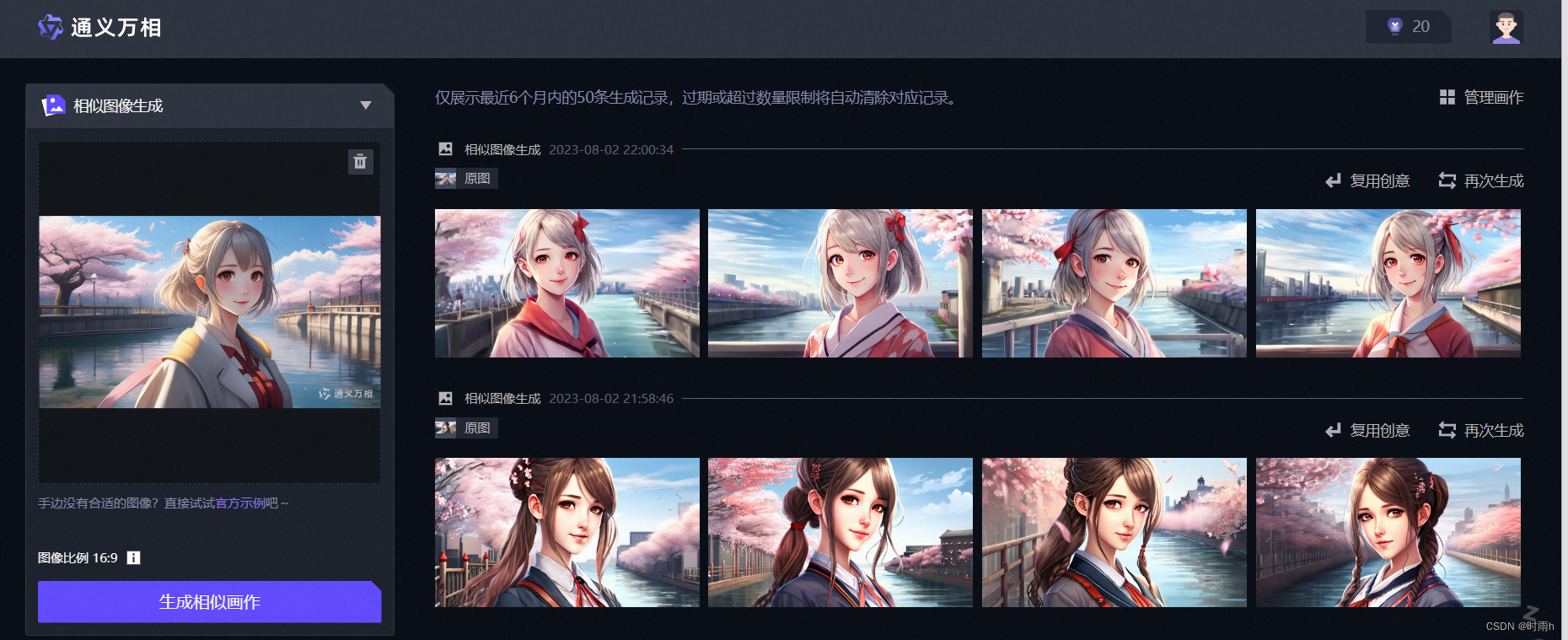
希望在进行相似图像生成时可以自由选择风格
内测地址
https://wanxiang.aliyun.com/
一天50次