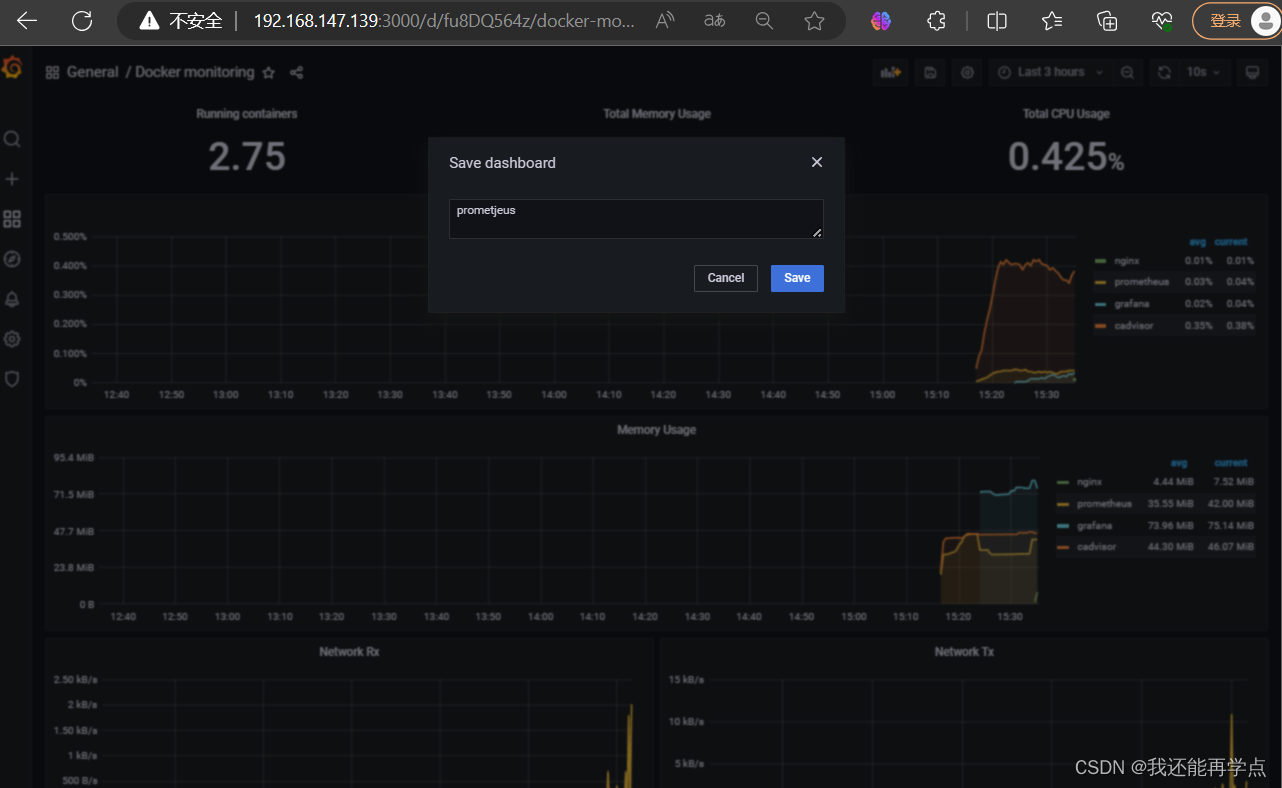
无锚框原理 TOOD:Task-aligned One-stage Object Detection
- 一 摘要
- 二 引言
- TOOD设计
- 三 具体设计
- Task-aligned Head
- 任务对齐的预测器 TAP
- 预测对齐
- TAL 任务对齐学习
- Task-aligned Sample Assignment
- 多任务损失
一 摘要
一阶段目标检测通常通过优化两个子任务来实现:对象分类和定位,使用具有两个平行分支的头部,这可能导致两个任务之间预测的空间对齐程度不一致。
提出了一种“任务对齐一阶段目标检测”方法,以学习方式明确地对齐这两个任务。首先设计了一种新颖的任务对齐头(T-head),它在学习任务交互和任务特定特征之间提供了更好的平衡,也更灵活地通过任务对齐预测器学习对齐。
其次,我们提出了任务对齐学习(TAL),通过设计的样本分配方案和任务对齐损失,在训练过程中明确地拉近(甚至统一)两个任务的最优锚点。具有更少的参数和FLOPs
二 引言
目标检测在从自然图像中定位和识别感兴趣的物体,是计算机视觉中一项基础而具有挑战性的任务。通常采用多任务学习的方式来进行问题建模,通过同时优化目标分类和定位。分类任务旨在学习着重于物体关键或显著部分的区分特征,而定位任务则在准确地定位整个物体及其边界,由于分类和定位的学习机制不同,通过两个独立分支进行预测时,所学习到的特征的空间分布可能不同,导致一定程度的错位。
一阶段物体检测器通过专注于物体中心,试图预测两个单独任务的一致输出结果,他们假设物体中心的锚点更有可能为分类和定位提供更准确的预测。
例:FCOS和ATSS都使用了一个中心度分支来增强从靠近物体中心的锚点预测的分类分数,并为相应锚点的定位损失分配更大的权重。此外,FoveaBox将物体内预定义的中心区域中的锚点视为正样本。
但是 :有缺陷
- 分类和定位的独立性。最近的一阶段检测器通过使用两个独立的分支(也就是头部)并行进行对象分类和定位。这样的两分支设计可能导致两个任务之间缺乏交互,从而在执行他们时导致预测不一致。
- 无任务特异性的样本分配。大多数无锚点检测器使用基于几何的分配方案,为了分类和定位都会选择靠近对象中心的锚点,而基于锚点的检测器通常通过计算锚框和真值之间的IOU来分配锚框。然而,用于分类和定位的最佳锚点往往不一致,并且可能根据对象的形状和特征而有很大的变化。广泛使用的样本分配方案是无任务特异性的,因此很难对这两个任务进行准确而一致的预测。在非极大值抑制期间,一个精确的边界框可能会被一个不太准确的边界框所抑制。
TOOD设计
- 任务对齐头部。与传统的单阶段目标检测中使用两个并行的分支分别实现分类和定位不同,我们设计了一个任务对齐头部(T-head)来增强两个任务之间的交互,这使得这两个任务能跟协作的工作,从而使他们的预测更加准确对齐。他通过计算任务交互特征,并通过一种新颖的任务对齐预测器(TAP)进行预测 ,然后根据任务对齐学习提供的学习信号,它根据这两个预测的空间分布进行对齐。
- 任务对齐学习。为了进一步克服不对齐问题,我们提出了任务对齐学习(TAL),来明确地拉近两个任务的最优锚点,他通过设计样本分配方案和任务对齐损失来完成。样本分配通过计算每个锚点的任务对齐程度来收集训练样本(即正负样本),而任务对齐损失在训练过程中逐渐统一用于预测分类和定位的最佳锚点。因此在推理阶段,可以保留具有高分类分数并共同具有精确定位的边界框
三 具体设计
T-head和TAL可以协同工作,改进两个任务的对齐。具体而言,T-head首先对FPN特征进行分类和定位预测,然后TAL根据一个新的任务对齐度量计算任务对齐信号。该度量衡量了两个预测之间的对齐程度。最后,在方向传播过程中,T-head根据从TAL计算得到的学习信号自动调整其分类概率和定位预测。
Task-aligned Head
设计一个高效的头部结构,以改进一阶检测器中头部的传统设计。在这项工作中,我们通过考虑两个方面来实现这一步目标:
- 增加两个任务之间的交互
- 增强检测器学习对齐的能力
TAP包括一个简单的特征提取器和两个任务对齐预测器


为了增强分类和定位之间的交互,我们使用一个特征提取器从多个卷积层中学习一个堆叠的任务交互特征,如上图蓝色部分。这个设计不仅有助于任务之间的交互,还为这两个任务提供了多层次的特征和多尺度的有效感受野。

任务对齐的预测器 TAP
我们在计算的任务交互特征上同时进行目标分类和定位,这两个任务能够很好地感知彼此的状态。然而,由于单分支的设计,任务交互特征不可避免地会在两个不同任务之间引入一定程度的特征冲突,在这种也有所讨论,直观上,目标分类和定位的目标不同,因此关注不同类型的特征(如:不同的层次或感受野)。因此,我们提出了一种层级注意力机制,通过在层级上动态计算这些任务特定的特征,鼓励任务的分解。

预测对齐
在预测步骤中,我们进一步通过调整两个预测的空间分布P和B明确地对齐这两个任务。与以往的研究不同,以往的研究使用一个中心性的分支或一个IOU分支,这些方法只能基于分类特征或定位特征之一来调整分类预测,我们通过考虑使用计算出的任务交互特征来同时对齐这两个预测任务,值得注意的是,我们在这两个任务上分别执行对齐方法。



偏移量独立地学习到每个通道,意味着物体的每个边界都有自己独立学习的偏移量。这使得四个边界能够更准确地预测,因为,每个边界都可以从其附近最精确的锚点中单独学习,因此,我们的方法不仅可以对齐两个任务,还可以通过每个边界识别一个精确的锚点来提高定位的精度。


其中Conv1和Conv3是用于将维的两个1X1卷积层,M和O的学习是通过使用提出的任务对齐学习(TAL)来完成的
TAL 任务对齐学习
我们进一步引入了任务对齐学习,用于指导我们的T-head生成任务对齐的预测。TAL与之前的方法在两个方面有所不同,首先,从任务对齐的角度来看,它根据设计的度量标准动态选择高质量的锚点。其次,他同时考虑了锚点分配和权重分配,它包括一种样本分配策略和专门用于对齐两个任务的新损失函数。
Task-aligned Sample Assignment
为了应对NMS,一个训练实例的锚点分配应该满足以下规则:
- 一个良好对齐的锚点应能够同时预测出高精度的分类分数和精确的定位
- 一个未对齐的锚点应该具有较低的分类分数,并会随后被抑制。
基于这两个目标,我们设计了一种新的锚点对齐度量方法,用于显式地测量锚点级别的任务对齐程度。该对齐度量方法被集成到样本分配和损失函数中,以动态地改进每个锚点的预测结果。
锚点对齐度量
考虑到一个分类得分和预测边界框与真实边界框之间的重叠联合(IOU)指示了两个任务的预测质量,我们使用分类得分和IOU的高阶组合来衡量任务对齐的程度。具体地,我们设计了一下度量方式来计算每个实例的锚点级别对齐度:

其中s和u分别表示分类得分和IOU值,α和β用于控制锚点对齐指标中两个任务的影响。值得注意的是,t在两个任务的联合优化中扮演了关键角色,以实现任务对齐的目标。它鼓励网络从联合优化的角度动态关注高质量的锚点。
训练样本分配
训练样本的分配对于目标检测器的训练至关重要,为了改善两个任务的对齐,我们关注任务对齐的锚点,并采取一个简单的分配规则来选择训练样本:对于每个实例,我们选择具有最大t值的m个锚点作为正样本,而将剩余的锚点作为负样本。同样,训练是通过计算机专门设计用于任务分类和定位对齐的新损失函数来进行的。
多任务损失
分类目标为了明确增加对齐锚点的分类分数,同时减少对齐不良的锚点的分数(即具有较小的t),我们在训练过程中使用t代替正锚点的二进制标签。然而,我们发现当正锚点的标签(即t)随着α和β的增加而变小时,网络无法收敛,因此,我们使用归一化的t,即^t 来代替正锚点的二进制标签,其中, 它通过一下两个属性进行归一化:
- 确保对困难实例进行有效学习(通常具有所有对应正锚点的较小t)
- 根据预测边界框的精确度保持实例之间的排序关系
因此,我们采用简单的实例级归一化来调整t的尺度:在每个实例中,t的最大值等于最大的IOU值(u),然后,对于分类任务,在正锚点上计算的二元交叉熵(BCE)可以重新表达为:

其中,i表示第i个锚点,来自于与一个实例相对应的的N个正锚点,我们使用焦点损失来进行分类,以减轻训练过程中负样本和正样本之间的不平衡问题。对于正锚点计算的焦点损失可以通过公式10进行重新表述,分类任务的最终损失函数定义为:
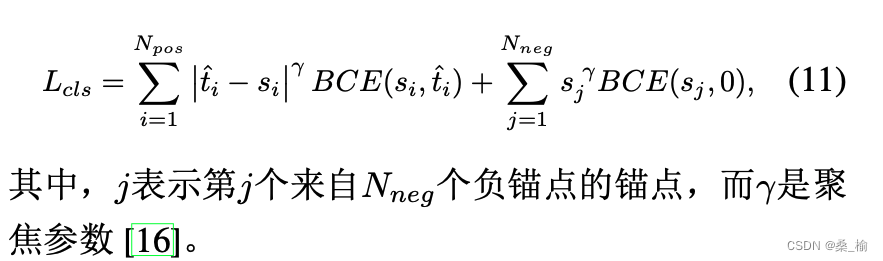
本地化目标 通常情况下,由良好对齐的锚框(即具有较大的t值)预测的边界框不仅具有较大的分类得分和准确的定位,而且这样的边界框在非极大值抑制过程中更有可能保留下来,此外,可以通过加权更谨慎的处理损失来应用t值从而选择高质量的边界框,以改善训练。从高质量的边界框中学习对模型的性能是有益的,而低质量的边界框往往通过产生大量不太有信息且冗余的信号来更新模型,对训练产生负面影响,在我们的情况下,我们应用t值来衡量边界框的质量,因此,我们通过关注良好对齐的锚框(且具有较大的t值)来改善任务对齐和回归精度,同时减少边界框回归中不良对齐的锚框(具有较小的t值)的影响,与分类目标类似,基于^t的重加权每个锚框的边界框回归损失,而GIOU损失可以重新定义为:











![[C语言]深入浅出,带你构建C语言宏观框架](https://img-blog.csdnimg.cn/7b3b2a8dece74c6ab5131ca5de08712a.png)