书写自动智慧:探索Python文本分类器的开发与应用:支持二分类、多分类、多标签分类、多层级分类和Kmeans聚类
文本分类器,提供多种文本分类和聚类算法,支持句子和文档级的文本分类任务,支持二分类、多分类、多标签分类、多层级分类和Kmeans聚类,开箱即用。python3开发。
-
Classifier支持算法
- LogisticRegression
- Random Forest
- Decision Tree
- K-Nearest Neighbours
- Naive bayes
- Xgboost
- Support Vector Machine(SVM)
- TextCNN
- TextRNN
- Fasttext
- BERT
-
Cluster
- MiniBatchKmeans
While providing rich functions, pytextclassifier internal modules adhere to low coupling, model adherence to inert loading, dictionary publication, and easy to use.
- 安装
- Requirements and Installation
pip3 install torch # conda install pytorch
pip3 install pytextclassifier
or
git clone https://github.com/shibing624/pytextclassifier.git
cd pytextclassifier
python3 setup.py install
1. English Text Classifier
包括模型训练、保存、预测、评估等
examples/lr_en_classification_demo.py:
import syssys.path.append('..')
from pytextclassifier import ClassicClassifierif __name__ == '__main__':m = ClassicClassifier(output_dir='models/lr', model_name_or_model='lr')# ClassicClassifier support model_name:lr, random_forest, decision_tree, knn, bayes, svm, xgboostprint(m)data = [('education', 'Student debt to cost Britain billions within decades'),('education', 'Chinese education for TV experiment'),('sports', 'Middle East and Asia boost investment in top level sports'),('sports', 'Summit Series look launches HBO Canada sports doc series: Mudhar')]# train and save best modelm.train(data)# load best model from model_dirm.load_model()predict_label, predict_proba = m.predict(['Abbott government spends $8 million on higher education media blitz'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')test_data = [('education', 'Abbott government spends $8 million on higher education media blitz'),('sports', 'Middle East and Asia boost investment in top level sports'),]acc_score = m.evaluate_model(test_data)print(f'acc_score: {acc_score}')
output:
ClassicClassifier instance (LogisticRegression(fit_intercept=False), stopwords size: 2438)
predict_label: ['education'], predict_proba: [0.5378236358492112]
acc_score: 1.0
2. Chinese Text Classifier(中文文本分类)
文本分类兼容中英文语料库。
example examples/lr_classification_demo.py
import syssys.path.append('..')
from pytextclassifier import ClassicClassifierif __name__ == '__main__':m = ClassicClassifier(output_dir='models/lr-toy', model_name_or_model='lr')# 经典分类方法,支持的模型包括:lr, random_forest, decision_tree, knn, bayes, svm, xgboostdata = [('education', '名师指导托福语法技巧:名词的复数形式'),('education', '中国高考成绩海外认可 是“狼来了”吗?'),('education', '公务员考虑越来越吃香,这是怎么回事?'),('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'),('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与'),('sports', '米兰客场8战不败国米10年连胜'),]m.train(data)print(m)# load best model from model_dirm.load_model()predict_label, predict_proba = m.predict(['福建春季公务员考试报名18日截止 2月6日考试','意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')test_data = [('education', '福建春季公务员考试报名18日截止 2月6日考试'),('sports', '意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'),]acc_score = m.evaluate_model(test_data)print(f'acc_score: {acc_score}') # 1.0#### train model with 1w dataprint('-' * 42)m = ClassicClassifier(output_dir='models/lr', model_name_or_model='lr')data_file = 'thucnews_train_1w.txt'm.train(data_file)m.load_model()predict_label, predict_proba = m.predict(['顺义北京苏活88平米起精装房在售','美EB-5项目“15日快速移民”将推迟'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')
output:
ClassicClassifier instance (LogisticRegression(fit_intercept=False), stopwords size: 2438)
predict_label: ['education' 'sports'], predict_proba: [0.5, 0.598941806741534]
acc_score: 1.0
------------------------------------------
predict_label: ['realty' 'education'], predict_proba: [0.7302956923617372, 0.2565005445322923]
3.可解释性分析
例如,显示模型的特征权重,以及预测词的权重 examples/visual_feature_importance.ipynb
import syssys.path.append('..')
from pytextclassifier import ClassicClassifier
import jiebatc = ClassicClassifier(output_dir='models/lr-toy', model_name_or_model='lr')
data = [('education', '名师指导托福语法技巧:名词的复数形式'),('education', '中国高考成绩海外认可 是“狼来了”吗?'),('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'),('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与'),('sports', '米兰客场8战不败国米10年连胜')
]
tc.train(data)
import eli5infer_data = ['高考指导托福语法技巧国际认可','意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜']
eli5.show_weights(tc.model, vec=tc.feature)
seg_infer_data = [' '.join(jieba.lcut(i)) for i in infer_data]
eli5.show_prediction(tc.model, seg_infer_data[0], vec=tc.feature,target_names=['education', 'sports'])
output:

4. Deep Classification model
本项目支持以下深度分类模型:FastText、TextCNN、TextRNN、Bert模型,import模型对应的方法来调用:
from pytextclassifier import FastTextClassifier, TextCNNClassifier, TextRNNClassifier, BertClassifier
下面以FastText模型为示例,其他模型的使用方法类似。
4.1 FastText 模型
训练和预测FastText模型示例examples/fasttext_classification_demo.py
import syssys.path.append('..')
from pytextclassifier import FastTextClassifier, load_dataif __name__ == '__main__':m = FastTextClassifier(output_dir='models/fasttext-toy')data = [('education', '名师指导托福语法技巧:名词的复数形式'),('education', '中国高考成绩海外认可 是“狼来了”吗?'),('education', '公务员考虑越来越吃香,这是怎么回事?'),('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'),('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与'),('sports', '米兰客场8战不败保持连胜'),]m.train(data, num_epochs=3)print(m)# load trained best modelm.load_model()predict_label, predict_proba = m.predict(['福建春季公务员考试报名18日截止 2月6日考试','意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')test_data = [('education', '福建春季公务员考试报名18日截止 2月6日考试'),('sports', '意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'),]acc_score = m.evaluate_model(test_data)print(f'acc_score: {acc_score}') # 1.0#### train model with 1w dataprint('-' * 42)data_file = 'thucnews_train_1w.txt'm = FastTextClassifier(output_dir='models/fasttext')m.train(data_file, names=('labels', 'text'), num_epochs=3)# load best trained model from model_dirm.load_model()predict_label, predict_proba = m.predict(['顺义北京苏活88平米起精装房在售','美EB-5项目“15日快速移民”将推迟'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')x, y, df = load_data(data_file)test_data = df[:100]acc_score = m.evaluate_model(test_data)print(f'acc_score: {acc_score}')
4.2 BERT 类模型
4.2.1 多分类模型
训练和预测BERT多分类模型,示例examples/bert_classification_zh_demo.py
import syssys.path.append('..')
from pytextclassifier import BertClassifierif __name__ == '__main__':m = BertClassifier(output_dir='models/bert-chinese-toy', num_classes=2,model_type='bert', model_name='bert-base-chinese', num_epochs=2)# model_type: support 'bert', 'albert', 'roberta', 'xlnet'# model_name: support 'bert-base-chinese', 'bert-base-cased', 'bert-base-multilingual-cased' ...data = [('education', '名师指导托福语法技巧:名词的复数形式'),('education', '中国高考成绩海外认可 是“狼来了”吗?'),('education', '公务员考虑越来越吃香,这是怎么回事?'),('sports', '图文:法网孟菲尔斯苦战进16强 孟菲尔斯怒吼'),('sports', '四川丹棱举行全国长距登山挑战赛 近万人参与'),('sports', '米兰客场8战不败国米10年连胜'),]m.train(data)print(m)# load trained best model from model_dirm.load_model()predict_label, predict_proba = m.predict(['福建春季公务员考试报名18日截止 2月6日考试','意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')test_data = [('education', '福建春季公务员考试报名18日截止 2月6日考试'),('sports', '意甲首轮补赛交战记录:米兰客场8战不败国米10年连胜'),]acc_score = m.evaluate_model(test_data)print(f'acc_score: {acc_score}')# train model with 1w data file and 10 classesprint('-' * 42)m = BertClassifier(output_dir='models/bert-chinese', num_classes=10,model_type='bert', model_name='bert-base-chinese', num_epochs=2,args={"no_cache": True, "lazy_loading": True, "lazy_text_column": 1, "lazy_labels_column": 0, })data_file = 'thucnews_train_1w.txt'# 如果训练数据超过百万条,建议使用lazy_loading模式,减少内存占用m.train(data_file, test_size=0, names=('labels', 'text'))m.load_model()predict_label, predict_proba = m.predict(['顺义北京苏活88平米起精装房在售','美EB-5项目“15日快速移民”将推迟','恒生AH溢指收平 A股对H股折价1.95%'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')
PS:如果训练数据超过百万条,建议使用lazy_loading模式,减少内存占用
4.2.2 多标签分类模型
分类可以分为多分类和多标签分类。多分类的标签是排他的,而多标签分类的所有标签是不排他的。
多标签分类比较直观的理解是,一个样本可以同时拥有几个类别标签,
比如一首歌的标签可以是流行、轻快,一部电影的标签可以是动作、喜剧、搞笑等,这都是多标签分类的情况。
训练和预测BERT多标签分类模型,示例examples/bert_multilabel_classification_zh_demo.py.py
import sys
import pandas as pdsys.path.append('..')
from pytextclassifier import BertClassifierdef load_jd_data(file_path):"""Load jd data from file.@param file_path: format: content,其他,互联互通,产品功耗,滑轮提手,声音,APP操控性,呼吸灯,外观,底座,制热范围,遥控器电池,味道,制热效果,衣物烘干,体积大小@return: """data = []with open(file_path, 'r', encoding='utf-8') as f:for line in f:line = line.strip()if line.startswith('#'):continueif not line:continueterms = line.split(',')if len(terms) != 16:continueval = [int(i) for i in terms[1:]]data.append([terms[0], val])return dataif __name__ == '__main__':# model_type: support 'bert', 'albert', 'roberta', 'xlnet'# model_name: support 'bert-base-chinese', 'bert-base-cased', 'bert-base-multilingual-cased' ...m = BertClassifier(output_dir='models/multilabel-bert-zh-model', num_classes=15,model_type='bert', model_name='bert-base-chinese', num_epochs=2, multi_label=True)# Train and Evaluation data needs to be in a Pandas Dataframe containing at least two columns, a 'text' and a 'labels' column. The `labels` column should contain multi-hot encoded lists.train_data = [["一个小时房间仍然没暖和", [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]],["耗电情况:这个没有注意", [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],]data = load_jd_data('multilabel_jd_comments.csv')train_data.extend(data)print(train_data[:5])train_df = pd.DataFrame(train_data, columns=["text", "labels"])print(train_df.head())m.train(train_df)print(m)# Evaluate the modelacc_score = m.evaluate_model(train_df[:20])print(f'acc_score: {acc_score}')# load trained best model from model_dirm.load_model()predict_label, predict_proba = m.predict(['一个小时房间仍然没暖和', '耗电情况:这个没有注意'])print(f'predict_label: {predict_label}, predict_proba: {predict_proba}')
5.模型验证
- THUCNews中文文本数据集(1.56GB):官方下载地址,抽样了10万条THUCNews中文文本10分类数据集(6MB),地址:examples/thucnews_train_10w.txt。
- TNEWS今日头条中文新闻(短文本)分类 Short Text Classificaiton for News,该数据集(5.1MB)来自今日头条的新闻版块,共提取了15个类别的新闻,包括旅游,教育,金融,军事等,地址:tnews_public.zip
在THUCNews中文文本10分类数据集(6MB)上评估,模型在测试集(test)评测效果如下:
| 模型 | acc | 说明 |
|---|---|---|
| LR | 0.8803 | 逻辑回归Logistics Regression |
| TextCNN | 0.8809 | Kim 2014 经典的CNN文本分类 |
| TextRNN_Att | 0.9022 | BiLSTM+Attention |
| FastText | 0.9177 | bow+bigram+trigram, 效果出奇的好 |
| DPCNN | 0.9125 | 深层金字塔CNN |
| Transformer | 0.8991 | 效果较差 |
| BERT-base | 0.9483 | bert + fc |
| ERNIE | 0.9461 | 比bert略差 |
在中文新闻短文本分类数据集TNEWS上评估,模型在开发集(dev)评测效果如下:
| 模型 | acc | 说明 |
|---|---|---|
| BERT-base | 0.5660 | 本项目实现 |
| BERT-base | 0.5609 | CLUE Benchmark Leaderboard结果 CLUEbenchmark |
- 以上结果均为分类的准确率(accuracy)结果
- THUCNews数据集评测结果可以基于
examples/thucnews_train_10w.txt数据用examples下的各模型demo复现 - TNEWS数据集评测结果可以下载TNEWS数据集,运行
examples/bert_classification_tnews_demo.py复现
- 命令行调用
提供分类模型命令行调用脚本,文件树:
pytextclassifier
├── bert_classifier.py
├── fasttext_classifier.py
├── classic_classifier.py
├── textcnn_classifier.py
└── textrnn_classifier.py
每个文件对应一个模型方法,各模型完全独立,可以直接运行,也方便修改,支持通过argparse 修改--data_path等参数。
直接在终端调用fasttext模型训练:
python -m pytextclassifier.fasttext_classifier -h
6.文本聚类算法
Text clustering, for example examples/cluster_demo.py
import syssys.path.append('..')
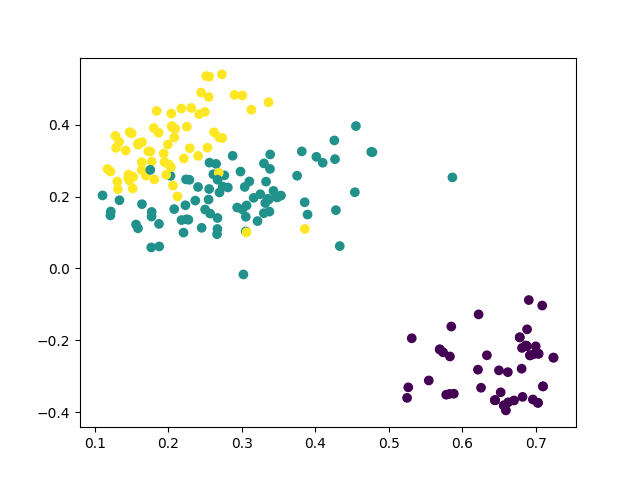
from pytextclassifier.textcluster import TextClusterif __name__ == '__main__':m = TextCluster(output_dir='models/cluster-toy', n_clusters=2)print(m)data = ['Student debt to cost Britain billions within decades','Chinese education for TV experiment','Abbott government spends $8 million on higher education','Middle East and Asia boost investment in top level sports','Summit Series look launches HBO Canada sports doc series: Mudhar']m.train(data)m.load_model()r = m.predict(['Abbott government spends $8 million on higher education media blitz','Middle East and Asia boost investment in top level sports'])print(r)########### load chinese train data from 1w data filefrom sklearn.feature_extraction.text import TfidfVectorizertcluster = TextCluster(output_dir='models/cluster', feature=TfidfVectorizer(ngram_range=(1, 2)), n_clusters=10)data = tcluster.load_file_data('thucnews_train_1w.txt', sep='\t', use_col=1)feature, labels = tcluster.train(data[:5000])tcluster.show_clusters(feature, labels, 'models/cluster/cluster_train_seg_samples.png')r = tcluster.predict(data[:30])print(r)
output:
TextCluster instance (MiniBatchKMeans(n_clusters=2, n_init=10), <pytextclassifier.utils.tokenizer.Tokenizer object at 0x7f80bd4682b0>, TfidfVectorizer(ngram_range=(1, 2)))
[1 1 1 1 1 1 1 1 1 1 1 8 1 1 1 1 1 1 1 1 1 1 9 1 1 8 1 1 9 1]
clustering plot image:
参考链接:https://github.com/shibing624/pytextclassifier
如果github进入不了也可进入 https://download.csdn.net/download/sinat_39620217/88205140 免费下载相关资料









![[C语言]深入浅出,带你构建C语言宏观框架](https://img-blog.csdnimg.cn/7b3b2a8dece74c6ab5131ca5de08712a.png)