大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用10-图片中的表格结构识别与提取实战,表格结构识别在信息处理领域中具有广泛应用,但由于表格的多样性和复杂性,以及难以准确解析的布局和格式,传统的方法往往存在一定的局限性。本项目基于深度学习技术,通过训练神经网络模型,实现了高效准确的表格结构识别。本文将详细介绍该项目的研究背景、方法、实验结果以及应用前景。
目录
表格结构提取项目介绍
表格结构提取论文介绍
表格结构步骤
代码实现
总结
表格结构提取项目介绍
图片中表格结构提取是一种计算机视觉技术,旨在识别和提取图像中的表格结构、内容和数据。其主要目的是自动化处理包含表格的图像或文档,并将表格数据转换为结构化的形式,以便进行后续的分析和处理。
表格识别的思路:
1.图像预处理:对输入的图像进行预处理,包括图像去噪、二值化、边缘检测等操作,以便更好地提取表格区域。
2.表格定位:通过使用图像分割和特征提取的方法,自动识别和定位出图像中的表格区域。
3.表格行列识别:识别表格中的行和列,并确定它们的边界位置和大小。
4.单元格分割:将表格中的每个单元格分割出来,以便进一步分析和处理。
5.文本识别:使用光学字符识别(OCR)技术,将每个单元格中的文本内容提取出来,并进行识别和字符编码。
6.数据校正和清理:对提取出的表格数据进行校正和清理,包括去除冗余空格、修正错误格式、合并合适的单元格等。
7.结构化输出:将清洗后的表格数据以结构化的形式输出,例如保存为CSV、Excel或数据库等格式。
表格结构提取论文介绍
关于表格结构提取的论文地址:
https://openaccess.thecvf.com/content/ICCV2021/papers/Long_Parsing_Table_Structures_in_the_Wild_ICCV_2021_paper.pdf
论文主要内容:
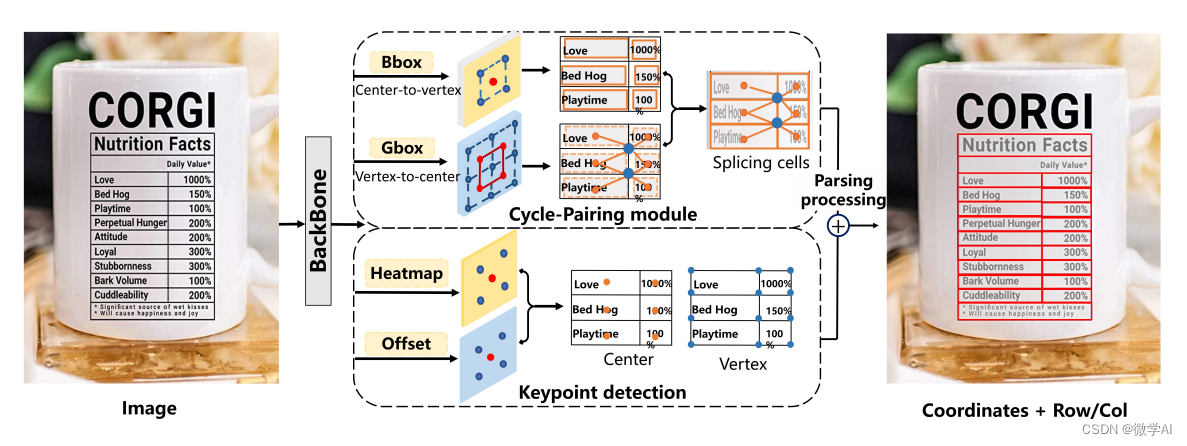
本论文主要解决了在真实环境中从图像中解析表格结构(Table Structure Parsing,TSP)的问题。与现有研究主要集中在解析来自扫描PDF文件的布局简单、对齐的表格图像不同,我们旨在为拍摄或扫描时出现弯曲、变形或遮挡的现实场景建立实用的表格结构解析系统。为了设计这样一个系统,我们提出了一种名为Cycle-CenterNet的方法,在CenterNet基础上引入了一个新颖的循环配对模块,以同时检测和分组表格单元并形成结构化表格。在循环配对模块中,我们提出了一种新的配对损失函数用于网络训练。除了Cycle-CenterNet,我们还介绍了一个大规模数据集,名为Wired Table in the Wild(WTW),其中包括多种风格的表格在照片、扫描文件、网页等场景下的结构解析的精确注释。实验证明,我们的Cycle-CenterNet在新的WTW数据集上始终以TEDS度量标准衡量的24.6%绝对改进的准确率取得最佳效果。更全面的实验分析也验证了我们提出的TSP任务方法的优势。
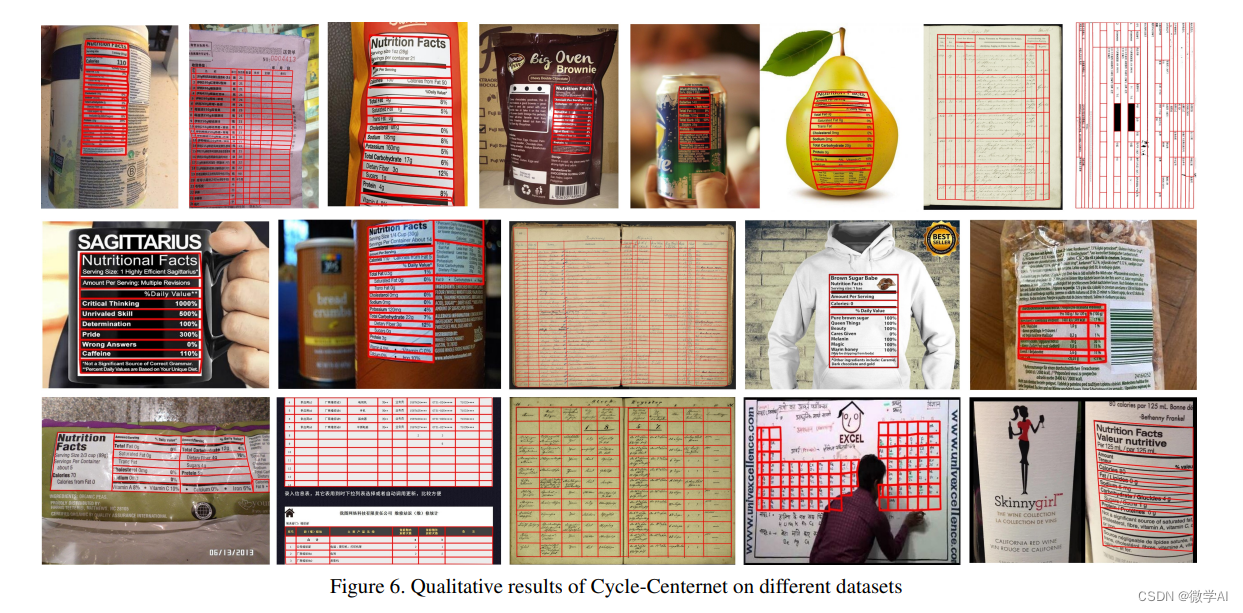
表格结构步骤
关于Cycle-CenterNet的方法,主要是基于CenterNet,并引入了新颖的循环配对模块。其主要步骤:
1.图像预处理:首先,对输入的图像进行预处理,包括去噪、增强对比度和颜色校正等操作,以提升表格区域的清晰度和可读性。
2.表格检测:利用CenterNet进行表格的检测,即定位图像中可能存在的表格区域。CenterNet是一种基于单点目标检测的网络模型,可以高效地识别表格。
3.循环配对模块:在表格检测的基础上,引入循环配对模块。该模块通过同时检测和分组表格中的单元格,将它们组成结构化的表格。循环配对模块采用新的配对损失函数进行网络训练,以提高准确性。
4.数据集:为了验证方法的有效性,研究人员还创建了一个大规模数据集,命名为Wired Table in the Wild(WTW)。该数据集包含了多种风格的表格图像,并对这些表格的结构进行了准确注释。
5.实验分析:通过在WTW数据集上进行实验,研究人员证明Cycle-CenterNet方法相比其他方法在表格结构解析方面具有显著优势。采用TEDS度量标准评估,Cycle-CenterNet的准确率相对提升了24.6%。
在这里插入图片描述
代码实现
这里代码实现过程,主要通过直接加载table_recognition模型,省略了中间辅助的表格识别操作过程,直接开箱即用。
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import cv2
from PIL import Image
from PIL import ImageDraw
import numpy as nptable_recognition = pipeline(Tasks.table_recognition)def draw_box(det_res, image):image = Image.fromarray(image)draw = ImageDraw.Draw(image)for i in range(det_res.shape[0]):p0, p1, p2, p3 = order_point(det_res[i])draw.line([*p0, *p1, *p2, *p3, *p0], fill='red', width=5)image = np.array(image)return imagedef order_point(coor):arr = np.array(coor).reshape([4, 2])sum_ = np.sum(arr, 0)centroid = sum_ / arr.shape[0]theta = np.arctan2(arr[:, 1] - centroid[1], arr[:, 0] - centroid[0])sort_points = arr[np.argsort(theta)]sort_points = sort_points.reshape([4, -1])if sort_points[0][0] > centroid[0]:sort_points = np.concatenate([sort_points[3:], sort_points[:3]])sort_points = sort_points.reshape([4, 2]).astype('float32')return sort_pointsif __name__ == '__main__':image_path = '333.png'image = cv2.imread(image_path)result = table_recognition(image_path)res= draw_box(result['polygons'], image)cv2.imwrite('result33.png', res)print('finished!')
运行结果:我们打开生成的图片看一下:
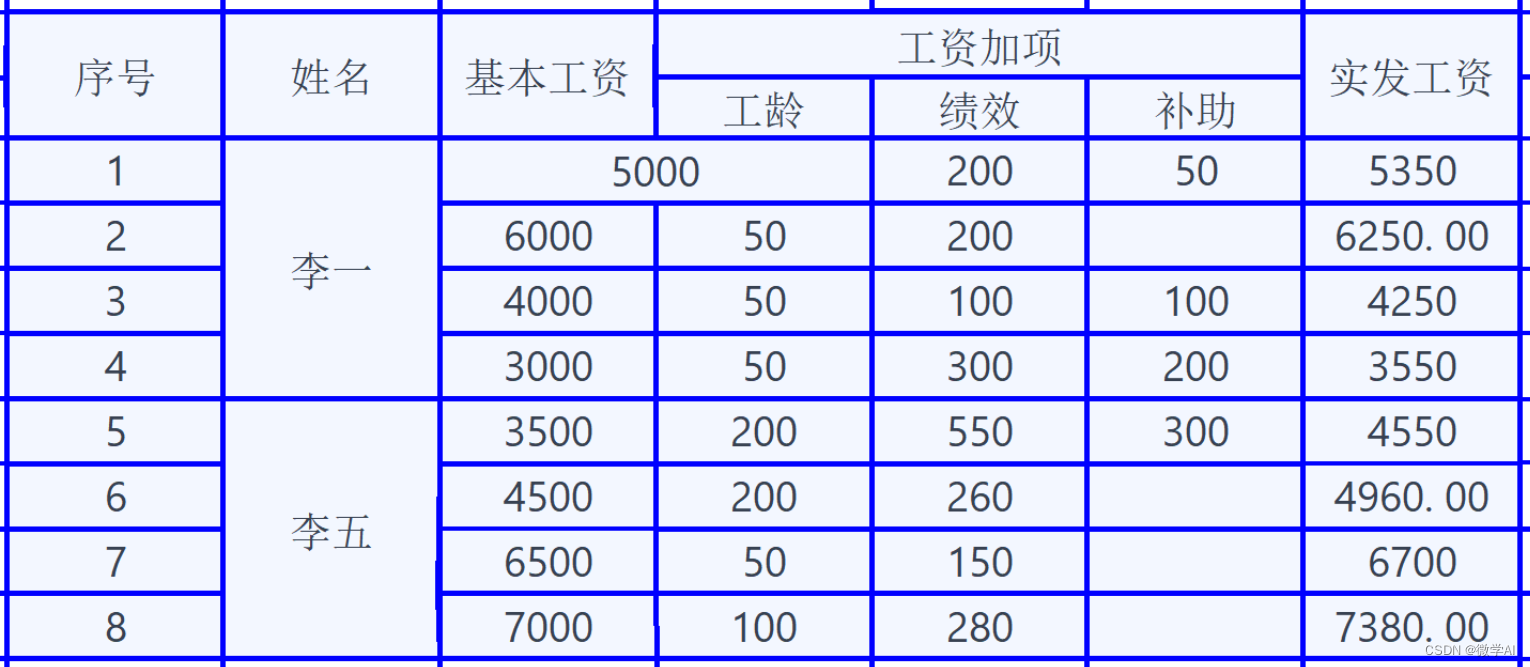
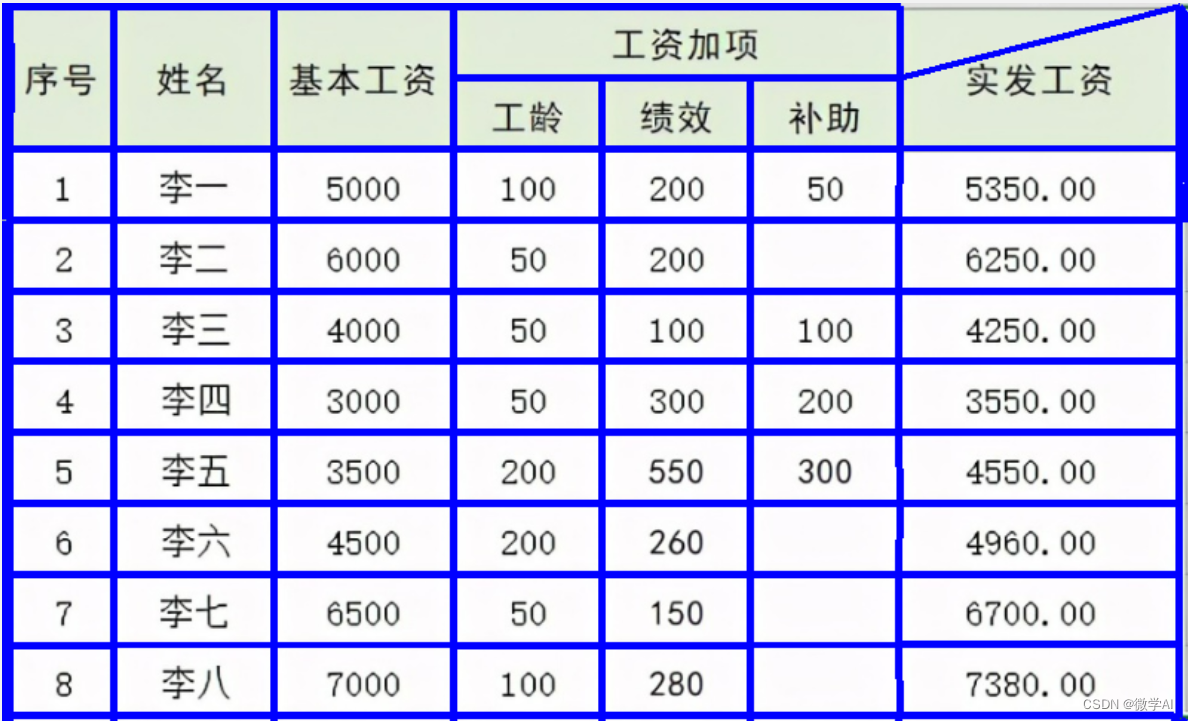
总结
在这篇论文中,主要通过提出一个新的WTW数据集和一个深度表格结构解析器Cycle-CenterNet,来解决野外环境下的表格结构解析问题。首先,我们的WTW数据集包含约14k张真实场景图像,这些图像是在野外成像条件下拍摄的,将表格结构解析的边界从数字文档图像扩展到了真实场景图像。另一方面,我们提出了一种新的野外场景表格结构识别方法,称为Cycle-CenterNet,解决了现有方法的主要弱点,包括对具有极端物理扭曲的实例的几何预测不准确以及提取不对齐表格的逻辑结构时存在的缺陷。通过全面的实验证明,所提出的方法以原则性的方式解决了上述问题,并在表格结构解析方面取得了最新的研究成果。我们希望我们提出的WTW数据集能进一步改善未来的表格识别研究。