操作系统基础
1.cpu占⽤率太⾼了怎么办? 排查思路是什么,怎么定位这个问题,处理流程
其他程序:
1.通过top命令按照CPU使⽤率排序找出占⽤资源最⾼的进程
2.lsof查看这个进程在使⽤什么⽂件或者有哪些线程
3.询问开发或者⽼⼤,是什么业务在使⽤这个进程
4.是否可以将这台机器隔离,不影响其他业务
5.然后经过同意后可以杀死或重启进程,然后再观察
2.top⻚⾯中怎么排序能快速看到进程使⽤cpu最⾼
top
-P
3.HTTP常⻅状态码有哪些?
200 正常
301 永久跳转
302 临时跳转
403 拒绝访问 ⽬录没权限 没有⾸⻚
404 ⻚⾯没找到
500 反向代理后端没有可以响应的服务器
502 反向代理后端没有可以响应的服务器
503 反向代理后端没有可以响应的服务器
4.服务的常⽤端⼝有哪些?
SSH 22
HTTP 80
Nginx 80 1.16.0
HTTPS 443
MySQL 3306 5.7
Redis 6379 5.0
Mongo 27017 4.0
Elasticsearch 9200 9300 7.9
Kibana 5601 7.9
Tomcat 8080 8
5.cpu、内存、流量、⽂件连接数等查询命令
CPU: top uptime
内存: free -h
流量: iftop
磁盘: df -h fdisk -l iotop
⽹络: netstat -lnatup
6.查看进程打开⽂件
ps
-ef #查看进程信息
lsof
-c #显示指定程序名所打开的⽂件
-i #显示符合条件的进程,IPv[46][proto][@host|addr
[:svc_list|port_list]
-p #显示指定进程pid所打开的⽂件
-u #显示指定⽤户UID的进程
+d #列出⽬录下被打开的⽂件
+D #递归累出⽬录下被打开的⽂件
7.实时显示⽹络流量
iftop
-i
-n
-t
8.删除⽂件后磁盘空间不释放
⽂件删了,但是还有进程在使⽤这个⽂件,所以需要终⽌被占⽤的进程.
9./proc⽬录都有什么内容
/proc/cpuinfo #当前CPU信息
/proc/meminfo #当前内存信息
/proc/loadavg #当前系统平均负载信息
/proc/mounts #当前设备挂载表信息
10.raid0 raid1 raid5 raid10 的区别
RAID0
最少1块
容量是所有磁盘加起来的容量
速度最快
安全性最低
RAID1
最少2块
容量是所有磁盘的⼀半
速度⼀般
安全性⾼
RAID5
最少3块
容量是所有磁盘减1块
速度⼀般
安全性较⾼
RAID10
最少4块
容量是所有磁盘⼀半
速度较快
安全性最⾼
11.shell写过什么脚本
思路:
1.先想好功能
2.有能⼒的直接写函数,先写函数名,但是不要写内容
3.最后在填充函数⾥的内容
参考:
#1.拉取代码
git_pull(){
git pull xxxxx
}
#2.构建镜像
docker_build(){
docker build -t
}
#3.上传harbor
docker_push(){
docker push xxxxx
}
#4.远程替换镜像
docker_deploy(){
for i in ip
do
ssh $i docker pull xxxx &&
docker stop app &&
docker rm app &&
docker run --name app -it xx -d xxxxx
done
}
#5.主函数
main(){
git_pull
docker_build
docker_push
docker_deploy
}
main
12.如何查看⼀个进程的端⼝?
netstat -lnatup|grep nginx
13.如何查看当前系统磁盘使⽤量?
df -h
14.给你200台服务器如何规划?
物理服务器:
1.使⽤kickstart+cobbler⾃动化批量装机安装操作系统
2.明确并规划好服务器运⾏的服务
3.编写shell脚本批量⾃动分发SSH密钥
4.使⽤ansible⻆⾊批量安装服务
5.使⽤ansible批量安装监控组件
云服务器:
1.因为云服务器不需要装系统
2.编写shell脚本批量⾃动分发SSH密钥
3.使⽤ansible⻆⾊批量安装服务
15.你们公司服务器的配置是什么?
node节点:
16C 32G
系统盘RAID1 1T SATA
数据盘SSD 500G
不做RAID
数据库:
16C 64G
系统盘RAID1 1T SATA
数据盘RAID10 2T SSD 4块
代码上线:
8C 16G
系统盘RAID1 1T SATA
数据盘RAID10 1T SATA 4块
prometheus:
8C 16G
系统盘RAID1 1T SATA
数据盘RAID10 1T SATA 4块
16.AWK提取⽇志信息,最⾼的IP,排名前10的IP
awk '{nums[$1]+=1;} END{for(i in nums){print nums[i],i}}' access_log | sort | tail
17.编写脚本停⽌正在运⾏的程序
问开发这个程序的停⽌命令是什么?或者是否有停⽌的接⼝地址
停⽌之前确定还是否有其他的服务在使⽤这个程序
我的思路是⾸先⽤ps加grep查出这个进程号,然后使⽤kill 进程号命令结束进程
最后脚本检查程序是否安全退出,然后给出⼀个状态码
kill $(ps -ef|grep nginx|awk ‘{print $2}’)
web服务
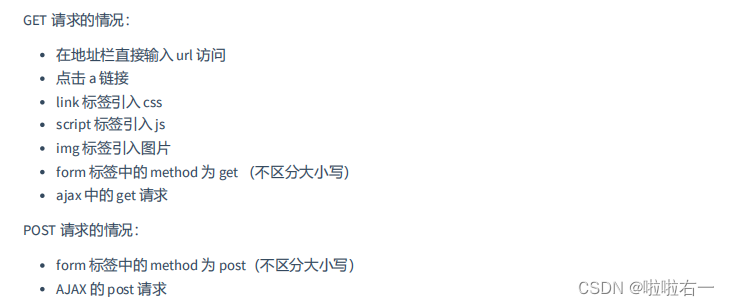
1.HTTP常⽤状态码有哪些?分别代表什么意思?
200 正常
301 永久跳转
302 临时跳转
403 拒绝访问 ⽬录没权限 没有⾸⻚
404 ⻚⾯没找到
499 数据库没有响应超时
500 反向代理后端没有可以响应的服务器
502 反向代理后端没有可以响应的服务器
503 反向代理后端没有可以响应的服务器
2.如何保证反向代理服务器的⾼可⽤?
使⽤keepalived的VIP保证⾼可⽤
3.常⽤服务的端⼝ http https ssh mysql redis mongo elasticsearch
http 80
https 443
ssh 22
mysql 3306
redis 6379
mongo 27017
elasticsearch 9200
4.⽤过哪些web服务组件?
nginx
haproxy
tomcat
5.Nginx⽤过哪些模块?作⽤是什么?
ngx_http_core_module 核⼼模块 localtion
ngx_http_rewrite_module 重写模块
ngx_http_proxy_module 反向代理
ngx_http_upstream_module 负载均衡
ngx_http_autoindex_module 索引模块
ngx_http_stub_status_module 状态监控
ngx_http_access_module ⽩名单⿊名单
ngx_http_auth_basic_module 简单认证
ngx_http_limit_req_module 请求限速
6.Nginx如何实现反向代理?反向代理和负载均衡什么关系?
⾸先使⽤反向代理模块将请求发送到后端服务器地址池
然后使⽤负载均衡模块将流量平均负载到后端服务器
通过反向代理实现了流量平均负载到后端服务器
7.web⽹⻚访问慢如何排查?经典问题
现象:
⽤户反映打开⽹⻚速度慢
思路:
1.是某些⽤户慢,还是所有的⽤户都反映慢
2.打开监控,查看服务器内存/CPU/磁盘负载情况
3.打开ELK,查看关键连接的响应时间,是否能查看出规律,⽐如突然某个时间段升⾼,或者间歇性的
4.如果发现某个服务器负载变⾼,导致流量转发到这台服务器的时候慢,那么先把这台服务器从反向代理⾥摘掉,
然后在具体的分析排查问题.
5.如果web服务器负载正常,但是访问慢,那么⼜可能是数据库响应不了或者负载变⾼.
6.通过分析⽇志发现,昨天正常,今天变慢,有可能是因为发布了新版本的代码,数据库语句有变化,可能导致索引
失效
7.查看数据库是否存在慢语句,是否有语句执⾏卡死被锁
8.通过分析慢语句的执⾏计划查看语句是否⾛索引,如果没做索引,可能是因为开发发版了新代码,数据库语句有
变化,可能导致索引失效
9.将执⾏分析结果汇报给⽼⼤,决定是否建⽴合适的索引或者回滚⽼版本,然后再分析问题
10.CDN缓存失效导致请求转发了服务器上
11.DNS解析是否有问题
8.Nginx⽇志怎么处理?多久切割⼀次?
使⽤logrotate定期滚动切割⽇志,每天切割⼀次
我们使⽤了ELK⽇志收集分析平台
9.你们公司并发量有多⼤?PV多少?
PV ⻚⾯访问量 30万-50万 – 150万/天 100M 公⽹带宽 CDN分布式缓存
UV 独⽴访问量 运营那边才能看
10.nginx七层和四层代理的区别
四层代理解析的是端⼝号
七层代理解析的是http的报⽂
四层代理应⽤场景是⾼速转发,不解析http
七层代理的应⽤场景根据解析的域名匹配转发到后端合适的服务器
11.Nginx怎么限流
根据每个IP的请求数基于请求限速模块进⾏限制
12.Nginx有哪些负载均衡算法?
RR 平均轮询
权重轮询
URL
IP_HASH
⽹络
1.TCP和UDP区别?
TCP是可靠传输,有错误重传机制,可以保证数据包有序完整的发送和接受,虽然安全,但是⽹络开销⼤
UDP是不可靠传世,没有确认机制,虽然不安全,但是速度快
2.三次握⼿与四次挥⼿过程
3.如果ping不通⼀个IP有什么排查思路?
公⽹IP: 按照TCP/IP四层协议从底层往上排查
1.⾸先排查⽹线和交换机是否正常⼯作
2.检查IP和⼦⽹掩码是否写错
3.ping⽹关看看是否正常
4.检查DNS是否配置正确
5.联系IDC⼈员协助排查,看看是不是机房⽹络抖动
内⽹IP:
1.⾸先排查⽹线和交换机是否正常⼯作
2.检查IP和⼦⽹掩码是否写错
3.ping⽹关看看是否正常
4.检查是否IP冲突
5.什么是⽹关和⼦⽹掩码
⽹关:
数据包发给谁,⽹关就是路由器的地址
⼦⽹掩码:
定义⽹络分类的,区分开⽹络位和主机位 8/16/24/32
255.0.0.0/8
255.255.0.0/16
255.255.255.0/24
255.255.255.255/32
10.0.0.100/24
255.255.255.0
6.IP地址如何分类?应⽤场景
A 10.0.0.0/8 ⽹络位少,主机位最多
B 172.16.0.0/16
C 192.168.1.0/24 ⽹络位最多,主机位最少,每个⽹络能容纳253台主机
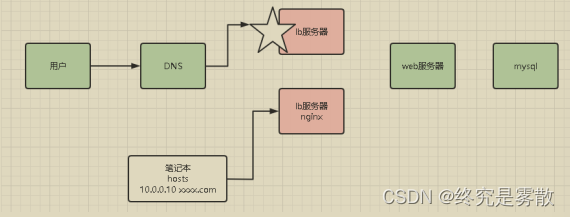
7.⽹站打不开,有什么排查思路?
传统架构
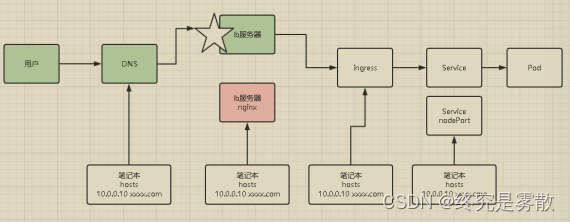
K8s架构
数据库
MySQL
1.说⼀下主从复制原理
主库的更新SQL(update、insert、delete)被写到binlog
从库发起连接,连接到主库。
此时主库创建一个 binlog dump thread,把 bin log 的内容发送到从库。
从库启动之后,创建一个 I/O 线程,读取主库传过来的 bin log 内容并写到 relay log
从库还会创建一个SQL线程,从 relay log 里面读取内容,从 ExecMasterLog_Pos 位置开始执行读取到的更新事件,将更新内容写入到 slave 的db
2.主从复制有延迟是什么原因?
1.主库操作语句本来就慢,从库当然也很慢
2.主库系统负载繁忙或⽹络拥塞
3.从库机器性能低不如主库,导致回放语句速度慢
4.未开启GTID,导致dump传送数据是串⾏的
5.7 版本中GTID模式下,可以开启多个SQL线程,真正实现了并性回放
3.主从复制需要监控什么?
show slave status \G
线程状态、报错信息、主从延时情况
4.你们公司数据库数据量有多⼤?每天有多少增⻓
100G 备份半⼩时
10-20m 增⻓
5.数据库如何备份?有哪些备份策略?多久备⼀次?
100G 30分钟
mysql --master-data --single-transaction
6.mysql主从复制有⼏种模式?
binlog
GTID
延迟复制
过滤复制
7.数据库语句慢如何监控?如何排查?如何解决?思路是什么?
开启慢语句记录⽇志
ELK收集慢⽇志
使⽤执⾏计划查看慢语句是否⾛索引
将执⾏结果汇报给⽼⼤,或者询问开发决定是否增加索引
8.数据库都需要监控哪些内容?
#主从复制状态
show slave status \G
#监控锁状态
show status like ‘innodb_rows_lock%’
select * from information_schema.innodb_trx;
select * from sys.innodb_lock_waits;
select * from performance_schema.threads;
select * from performance_schema.events_statements_current;
select * from performance_schema.events_statements_history;
#参数指标
内存、事务、线程、QPS、TPS、锁、等待、参数的评估指标。
9.数据库遇到过什么故障?如何解决的?
连接信息有误
⽹络故障
防⽕墙
最⼤连接数上线
10.MySQL MHA了解吗?说说原理,故障后如何切换,如何恢复?
搭建流程:
1.主2从独⽴节点、GTID
2. 互信
3.软连接
4.建⽤户5. 软件安装(perl\mananger\node)6. 启动检查: ssh repl7. 配置⽂件8. 启动9. vip\binlogserver\sendreport
Manager⼯具包主要包括以下⼏个⼯具:
masterha_manger 启动MHA
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_master_monitor 检测master是否宕机
masterha_check_status 检测当前MHA运⾏状态
masterha_master_switch 控制故障转移(⾃动或者⼿动)
masterha_conf_host 添加或删除配置的server信息
Node⼯具包主要包括以下⼏个⼯具:
这些⼯具通常由MHA Manager的脚本触发,⽆需⼈为操作
save_binary_logs 保存和复制master的⼆进制⽇志
apply_diff_relay_logs 识别差异的中继⽇志事件并将其差异的事件应⽤于其他的
purge_relay_logs 清除中继⽇志(不会阻塞SQL线程)
11.MySQL数据误删除如何恢复?流程是什么?如何防⽌此类事情发⽣?
全备+binlog
0.前端⻚⾯挂上维护信息
1.全备数据库时指定参数记录POST位置点
2.查看全备数据库的位置点,在测试环境恢复全备数据
3.截取binlog数据,提取出上⼀次全备到误删除命令之间的所有数据并导出
4.将binlog数据发送到测试恢复库并导⼊
5.验证恢复的数据是否完整,然后从测试库上将恢复数据导出并发送给主库
6.主库导出恢复数据
7.验证数据是否完整
12.你对MySQL做过哪些优化
1、主机、存储、⽹络、OS
2、实例: 参数
3、应⽤: SQL、索引、锁
4、架构: ⾼可⽤、读写分离、分布式
公司/业务/沟通
1.在公司遇到问题解决不了怎么办?

2.你在上架公司是如何展开⼯作的?

3.你们公司新项⽬从讨论到上线经历过哪些流程?
项⽬⽴项 --> 项⽬技术选型 --> 分配任务 --> 开发本地开发代码 --> 运维部署测试环境 --> 代码上线到
测试环境测试 --> 代码上线到预发布环境压测 --> 代码上线到⽣产环境 --> 持续监控
4.你们公司技术部有多少⼈?职位分别是什么?

5.刚进⼊⼀家公司你是如何展开⼯作的?


6.你的薪资都有哪些组成
1.基础⼯资
2.绩效⼯资
3.年终奖 1薪
4.五险⼀⾦
7.你为什么会离职?
离职的内⼼想法:
1.提升⾃⼰/学不到东⻄
2.钱不到位/加班严重
3.上家公司不正规,⽐如五险⼀⾦,谋求更好的机遇与发展,展现⾃⼰的平台
4.公司是旅游⾏业 疫情影响开不了⻔
5.疫情影响 停岗降薪
6.内⼼受到委屈/不喜欢领导/同事
7.⽗⺟身体不好离家近⼀点站在⾯试官⻆度,为什么会问这个问题?
1.看这个⼈稳不稳定,以后会不会以同样理由离职
2.公司不想要⼀个频繁跳槽的⼈
3.看你情商在不在线,会不会说上家公司或领导的坏话
如何体现稳不稳定?看简历上的⼯作经历
1.与其1年 2家公司,不如写1年1家公司
2.最好每家公司⾄少⼲满1年
3.毕业不到⼀年的,直接说整个⼤三都在实习。
回答的思路:
原则:不要抱怨,不要发牢骚,不要说上家公司坏话
1.公司战略转移,总部要搬到xx去了,但是我还想留在北京发展
2.想去⼤城市发展,⼩地⽅太安逸,趁着年轻,想出来闯⼀闯
3.你陪着公司从0发展,⼀步⼀步⻅证了公司的架构从⼏台服务器发展到⼏⼗台,经历多次调整,架构已经稳定
了,运维流程也已经固定,短期内不会有⼤的变动
我想挑战更⾼难度的架构和复杂的应⽤场景,趁着年轻,想多经历⼀些不同⾏业的架构。
4.我在上⼀家公司积累了丰富的经验,我从⼩就有⼀个梦想,希望能进⼊xx⾏业,最近⼏年xx⾏业发展很好
5.因为疫情影响,公司决定放弃xx项⽬,战略性裁员,我们部⻔整体被裁/资产重组/投资⼈换⾎




![【LeetCode】数据结构题解(13)[设计循环链表]](https://img-blog.csdnimg.cn/ff2fb1c912194d748ab01f8ad1bdf91d.png)