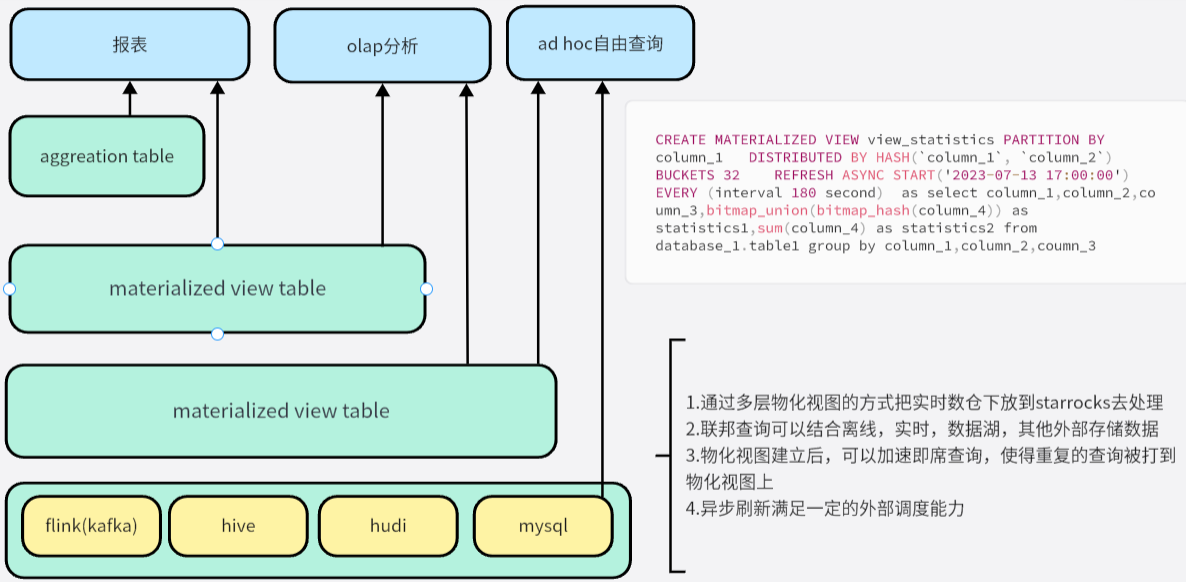
一、什么是特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
1、降维
降低维度
ndarry
维数:嵌套的层数
0维:标量,具体的数0 1 2 3...
1维:向量
2维:矩阵
3维:多个二维数组嵌套
n维:继续嵌套下去
2、特征降维降的是什么
降的是二维数组,特征是几行几列的,几行有多少样本,几列有多少特征
降低特征的个数(就是列数)
二、降维的两种方式
1、特征选择
2、主成分分析(可以理解一种特征提取的方式)
三、什么是特征选择
1、定义
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征
2、例子:想要对鸟进行类别的区分
特征?
(1)羽毛颜色
(2)眼睛宽度
(3)眼睛长度
(4)爪子长度
(5)体格大小
比如还有的特征:是否有羽毛、是否有爪子,那这些特征就没有意义
3、方法
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
(1)方差选择法:低方差特征过滤,过滤掉方差比较低的特征
(2)相关系数:特征与特征之间的相关程度
(3)方差选择法在文本分类中表现非常不好,对噪声的处理能力几乎为0,还删除了有用的特征
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
(1)决策树:信息熵、信息增益
(2)正则化:L1、L2
(3)深度学习:卷积等
(4)对于Embedded方式,只能在讲解算法的时候再进行介绍,更好的去理解
4、模块
sklearn.feature_selection
四、低方差特征过滤
1、删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度
(1)特征方差小:某个特征大多样本的值比较相近
(2)特征方差大:某个特征很多样本的值都有差别
2、API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
删除所有低方差特征,设置一个临界值,低于临界值的都删掉
Variance:方差
Threshold:阈值
3、Variance.fit_transform(X)
X:numpy array格式的数据[n_samples, n_features]
返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征
4、数据计算
我们对某些股票的指标特征之间进行一个筛选,数据在factor_returns.csv文件当中,除去index、date、return列不考虑(这些类型不匹配,也不是所需要的指标)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
import jieba
import pandas as pddef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()
运行结果:
data:pe_ratio pb_ratio market_cap return_on_asset_net_profit du_return_on_equity ev earnings_per_share revenue total_expense
0 5.9572 1.1818 8.525255e+10 0.8008 14.9403 1.211445e+12 2.0100 2.070140e+10 1.088254e+10
1 7.0289 1.5880 8.411336e+10 1.6463 7.8656 3.002521e+11 0.3260 2.930837e+10 2.378348e+10
2 -262.7461 7.0003 5.170455e+08 -0.5678 -0.5943 7.705178e+08 -0.0060 1.167983e+07 1.203008e+07
3 16.4760 3.7146 1.968046e+10 5.6036 14.6170 2.800916e+10 0.3500 9.189387e+09 7.935543e+09
4 12.5878 2.5616 4.172721e+10 2.8729 10.9097 8.124738e+10 0.2710 8.951453e+09 7.091398e+09
... ... ... ... ... ... ... ... ... ...
2313 25.0848 4.2323 2.274800e+10 10.7833 15.4895 2.784450e+10 0.8849 1.148170e+10 1.041419e+10
2314 59.4849 1.6392 2.281400e+10 1.2960 2.4512 3.810122e+10 0.0900 1.731713e+09 1.089783e+09
2315 39.5523 4.0052 1.702434e+10 3.3440 8.0679 2.420817e+10 0.2200 1.789082e+10 1.749295e+10
2316 52.5408 2.4646 3.287910e+10 2.7444 2.9202 3.883803e+10 0.1210 6.465392e+09 6.009007e+09
2317 14.2203 1.4103 5.911086e+10 2.0383 8.6179 2.020661e+11 0.2470 4.509872e+10 4.132842e+10[2318 rows x 9 columns]
data_new:[[ 5.95720000e+00 1.18180000e+00 8.52525509e+10 ... 1.21144486e+122.07014010e+10 1.08825400e+10][ 7.02890000e+00 1.58800000e+00 8.41133582e+10 ... 3.00252062e+112.93083692e+10 2.37834769e+10][-2.62746100e+02 7.00030000e+00 5.17045520e+08 ... 7.70517753e+081.16798290e+07 1.20300800e+07]...[ 3.95523000e+01 4.00520000e+00 1.70243430e+10 ... 2.42081699e+101.78908166e+10 1.74929478e+10][ 5.25408000e+01 2.46460000e+00 3.28790988e+10 ... 3.88380258e+106.46539204e+09 6.00900728e+09][ 1.42203000e+01 1.41030000e+00 5.91108572e+10 ... 2.02066110e+114.50987171e+10 4.13284212e+10]] (2318, 8)
五、相关系数
1、皮尔逊相关系数(Pearson Correlation Coefficient)
反映变量之间相关关系密切程度的统计指标
2、公式计算案例
(1)公式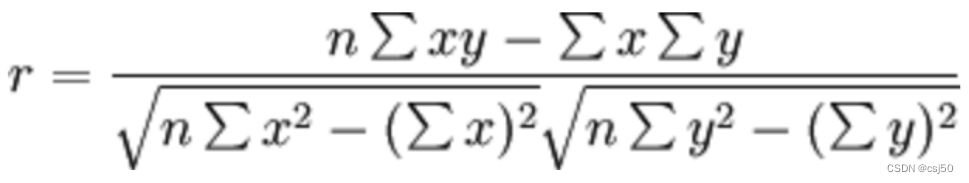
(2)比如说我们计算年广告费投入与月均销售额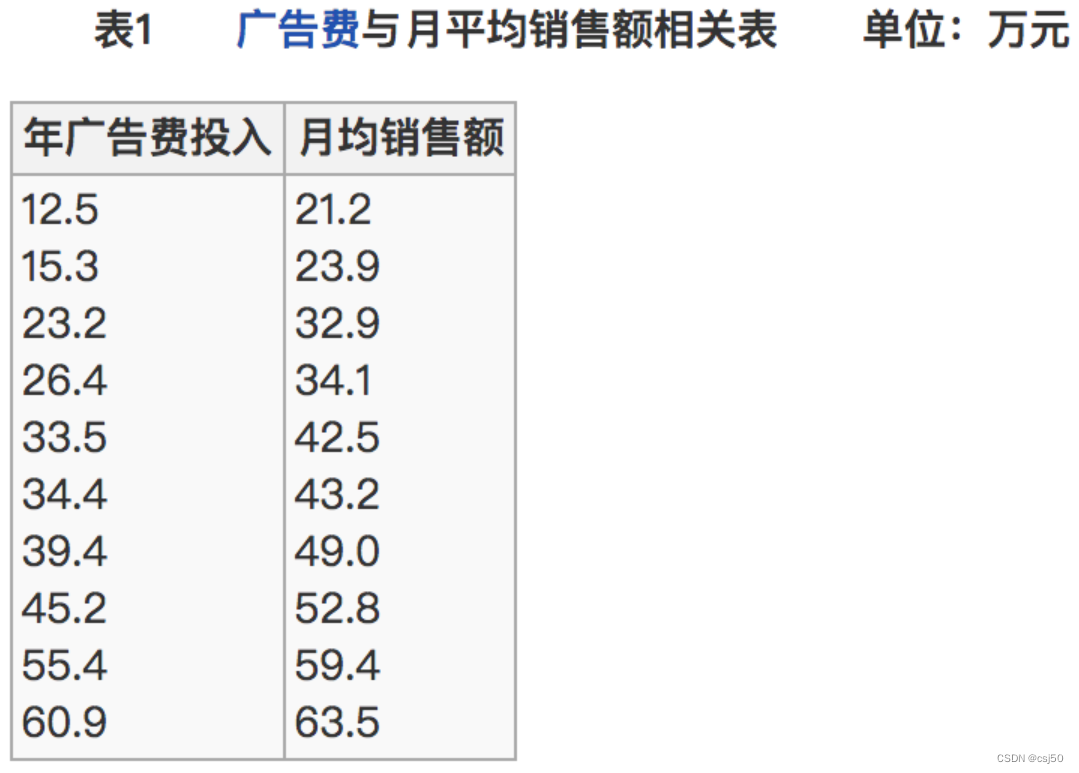
(3)那么之间的相关系数怎么计算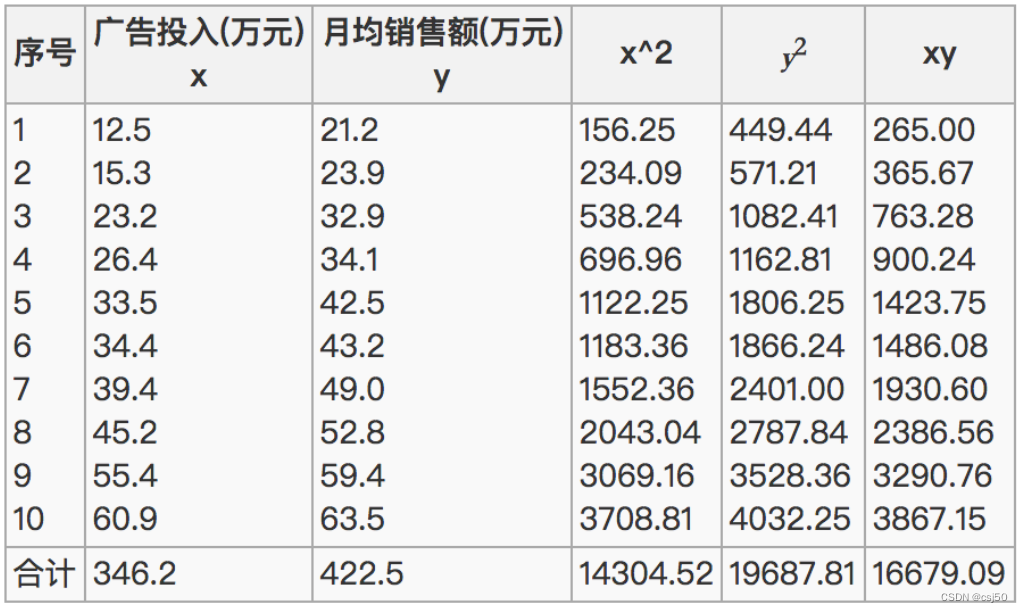
(4)最终计算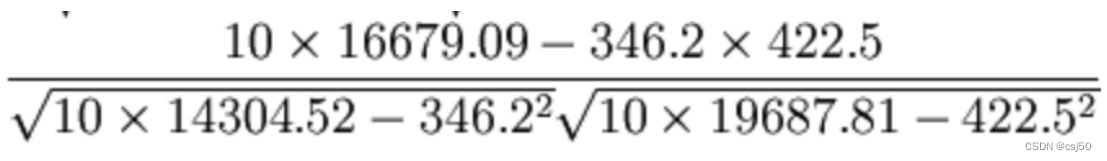
(5)结果=0.9942
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系
4、API
from scipy.stats import pearsonr
X:(N,) array_like
Y:(N,) array_like
Returns:(Pearson’s correlation coefficient, p-value),返回值是两个
注:pandas上面也有这个求相关系数的方法
5、案例:股票的财务指标相关性计算
计算某两个变量之间的相关系数
data [ ] 里面的关键字要用你自己表里面的列名
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import jieba
import pandas as pddef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()运行结果:
data:pe_ratio pb_ratio market_cap return_on_asset_net_profit du_return_on_equity ev earnings_per_share revenue total_expense
0 5.9572 1.1818 8.525255e+10 0.8008 14.9403 1.211445e+12 2.0100 2.070140e+10 1.088254e+10
1 7.0289 1.5880 8.411336e+10 1.6463 7.8656 3.002521e+11 0.3260 2.930837e+10 2.378348e+10
2 -262.7461 7.0003 5.170455e+08 -0.5678 -0.5943 7.705178e+08 -0.0060 1.167983e+07 1.203008e+07
3 16.4760 3.7146 1.968046e+10 5.6036 14.6170 2.800916e+10 0.3500 9.189387e+09 7.935543e+09
4 12.5878 2.5616 4.172721e+10 2.8729 10.9097 8.124738e+10 0.2710 8.951453e+09 7.091398e+09
... ... ... ... ... ... ... ... ... ...
2313 25.0848 4.2323 2.274800e+10 10.7833 15.4895 2.784450e+10 0.8849 1.148170e+10 1.041419e+10
2314 59.4849 1.6392 2.281400e+10 1.2960 2.4512 3.810122e+10 0.0900 1.731713e+09 1.089783e+09
2315 39.5523 4.0052 1.702434e+10 3.3440 8.0679 2.420817e+10 0.2200 1.789082e+10 1.749295e+10
2316 52.5408 2.4646 3.287910e+10 2.7444 2.9202 3.883803e+10 0.1210 6.465392e+09 6.009007e+09
2317 14.2203 1.4103 5.911086e+10 2.0383 8.6179 2.020661e+11 0.2470 4.509872e+10 4.132842e+10[2318 rows x 9 columns]
data_new:[[ 5.95720000e+00 1.18180000e+00 8.52525509e+10 ... 1.21144486e+122.07014010e+10 1.08825400e+10][ 7.02890000e+00 1.58800000e+00 8.41133582e+10 ... 3.00252062e+112.93083692e+10 2.37834769e+10][-2.62746100e+02 7.00030000e+00 5.17045520e+08 ... 7.70517753e+081.16798290e+07 1.20300800e+07]...[ 3.95523000e+01 4.00520000e+00 1.70243430e+10 ... 2.42081699e+101.78908166e+10 1.74929478e+10][ 5.25408000e+01 2.46460000e+00 3.28790988e+10 ... 3.88380258e+106.46539204e+09 6.00900728e+09][ 1.42203000e+01 1.41030000e+00 5.91108572e+10 ... 2.02066110e+114.50987171e+10 4.13284212e+10]] (2318, 8)
相关系数:(-0.004389322779936261, 0.8327205496564927)相关系数:
(-0.004389322779936261, 0.8327205496564927)
前面一个是相关系数,比较接近于0,说明这两者不太相关
后面是p-value,假设H0:x,y不相关,p-value越大,H0成立的概率越大。p-value值表示显著水平,越小越好
所以这里是说明前面的相关系数成立的可能性很大
6、特征与特征之间相关性很高怎么办
(1)选取其中一个
(2)加权求和
比如revenue和total_expense相关性高,各占50%
(3)主成分分析
7、用图片展示相关性
安装matplotlib
(1)先安装Pillow
参考资料:https://pillow.readthedocs.io/en/latest/installation.html
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade Pillow
(2)再安装matplotlib
pip3 install matplotlib
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import jieba
import pandas as pd
import matplotlib.pyplot as pltdef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data["revenue"], data["total_expense"])print("revenue与total_expense之间的相关性:\n", r2)#用图片展示相关性plt.figure(figsize=(20, 8), dpi=100)plt.scatter(data['revenue'], data['total_expense'])plt.show()return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤variance_demo()
六、主成分分析
1、什么是主成分分析(PCA)
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息
应用:回归分析或者聚类分析当中
2、如何最好的对一个立体的物体二维表示
现实中是一个水壶,拍成照片就是平面的
相当于将三维降到二维,在这个过程中可能就会有信息的损失
如何去衡量信息损失有多少,直观的检验方法是能不能通过二维的图像,能够还原出它还是一个水壶
从这四个图片中可以看到,最后一个能识别出是水壶,也就是说最后一个从三维降到二维它损失的信息是最少的
3、PCA计算过程
找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果
PCA是一种数据降维的技术,它并不是将数据拟合到一个模型中,而是通过线性变换将原始的高维数据投影到一个低维的子空间中,使得投影后的数据仍然尽可能地保留原始数据的信息,同时减少了特征的数量和减少了冗余性
4、API
sklearn.decomposition.PCA(n_components=None)
将数据分解为较低维数空间
n_components:
如果传小数:表示保留百分之多少的信息
如果传整数:减少到多少特征
5、PCA.fit_transform(X)
X:numpy array格式的数据[n_samples, n_features]
返回值:转换后指定维度的array
6、数据计算
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
from sklearn.decomposition import PCA
import jieba
import pandas as pd
import matplotlib.pyplot as pltdef datasets_demo():"""sklearn数据集使用"""#获取数据集iris = load_iris()print("鸢尾花数据集:\n", iris)print("查看数据集描述:\n", iris["DESCR"])print("查看特征值的名字:\n", iris.feature_names)print("查看特征值几行几列:\n", iris.data.shape)#数据集的划分x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)print("训练集的特征值:\n", x_train, x_train.shape)return Nonedef dict_demo():"""字典特征抽取"""data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]# 1、实例化一个转换器类transfer = DictVectorizer(sparse=False)# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字:\n", transfer.get_feature_names())return Nonedef count_demo():"""文本特征抽取"""data = ["life is short,i like like python", "life is too long,i dislike python"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray())print("特征名字:\n", transfer.get_feature_names()) return Nonedef count_chinese_demo():"""中文文本特征抽取"""data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]# 1、实例化一个转换器类transfer = CountVectorizer()# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new.toarray());print("特征名字:\n", transfer.get_feature_names())return Nonedef cut_word(text):"""进行中文分词"""return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串def count_chinese_demo2():"""中文文本特征抽取,自动分词"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = CountVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef tfidf_demo():"""用tf-idf的方法进行文本特征抽取"""# 1、将中文文本进行分词data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(data_new)# 2、实例化一个转换器类transfer = TfidfVectorizer()# 3、调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字:\n", transfer.get_feature_names())return Nonedef minmax_demo():"""归一化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = MinMaxScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef stand_demo():"""标准化"""# 1、获取数据data = pd.read_csv("dating.txt")#print("data:\n", data)data = data.iloc[:, 0:3] #行都要,列取前3列print("data:\n", data)# 2、实例化一个转换器transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return Nonedef variance_demo():"""过滤低方差特征"""# 1、获取数据data = pd.read_csv("factor_returns.csv")#print("data:\n", data)data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=3)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 4、计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data["revenue"], data["total_expense"])print("revenue与total_expense之间的相关性:\n", r2)#用图片展示相关性plt.figure(figsize=(20, 8), dpi=100)plt.scatter(data['revenue'], data['total_expense'])plt.show()return Nonedef pca_demo():"""PCA降维"""data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]# 1、实例化一个转换器类transfer = PCA(n_components=3)# 2、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)# 1、实例化一个转换器类transfer2 = PCA(n_components=0.9)# 2、调用fit_transformdata_new2 = transfer2.fit_transform(data)print("data_new2:\n", data_new2)return Noneif __name__ == "__main__":# 代码1:sklearn数据集使用#datasets_demo()# 代码2:字典特征抽取#dict_demo()# 代码3:文本特征抽取#count_demo()# 代码4:中文文本特征抽取#count_chinese_demo()# 代码5:中文文本特征抽取,自动分词#count_chinese_demo2()# 代码6: 测试jieba库中文分词#print(cut_word("我爱北京天安门"))# 代码7:用tf-idf的方法进行文本特征抽取#tfidf_demo()# 代码8:归一化#minmax_demo()# 代码9:标准化#stand_demo()# 代码10:低方差特征过滤#variance_demo()# 代码11:PCA降维pca_demo()运行结果:
data_new:[[ 1.28620952e-15 3.82970843e+00 5.26052119e-16][ 5.74456265e+00 -1.91485422e+00 5.26052119e-16][-5.74456265e+00 -1.91485422e+00 5.26052119e-16]]
data_new2:[[ 1.28620952e-15 3.82970843e+00][ 5.74456265e+00 -1.91485422e+00][-5.74456265e+00 -1.91485422e+00]]