MySQL
1、数据库技术概述
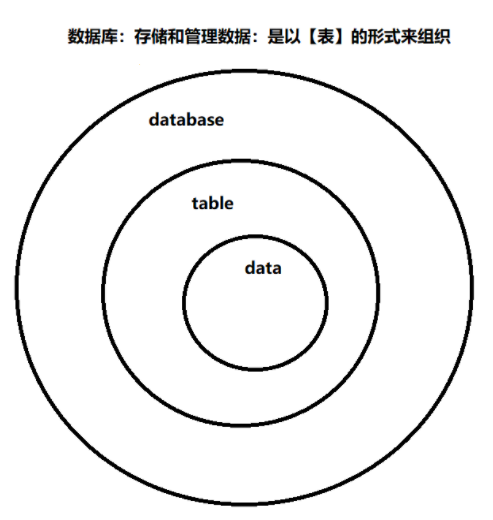
- 数据库database:存放和管理各种数据的仓库,操作的对象主要是【数据data】,科学的组织和存储数据,高效的获取和处理数据
- SQL:结构化查询语言,专为**关系型数据库而建立的操作语言,用户在使用SQL语句时,只需要发出“做什么”**的命令,具体“怎么做”是不用参与的。
解释:关系型数据库:指的是这一类数据库,对于数据的存储和管理方式:都是以【表】的形式来组织的,关系:表
比如:MySQL,Oracle,SQL Server系统的数据库——>关系型数据库——>都是以【表】的形式来存储和管理数据
- MySQL数据库特征
- 体积小:消耗资源较少
- 速度快:处理数据的速度较快
- 成本低:开源免费,技术成本投入比较便宜
- 可移植性:又被称为跨平台性,可以在多个操作系统中进行使用
2、MySQL数据库的安装与配置
- MySQL安装:参考安装文档
- 验证:MySQL数据库安装完毕后,可以借助于自带的【命令行工具】,进行操作
- MySQL数据库的卸载:控制面板——>卸载程序——>找到MySQL组件(两个)——>右键选择卸载
- MySQL数据库的连接操作:
- 自带的【命令行工具】进行连接使用
- 连接MySQL数据库的工具:HeiDiSQL
3、MySQL数据库的创建与删除
- 创建数据库的语法:
creat database 数据库名;
例:创建一个testdb01的数据库
create database testdb01;
- 查看现有的数据库:
show databases;
- 删除数据库语法:
drop database 数据库名字;
- MySQL注释:解释说明作用,不参与执行
单行注释:- - 单行注释的内容
多行注释:/* 多行注释的内容 */
4、MySQL数据库表的操作
- 创建表语法:
create table 表名(
列名1 数据类型,
列名2 数据类型,
列名3 数据类型,
…
列名n 数据类型
);
注意:最后一个列不需要加逗号
-
MySQL支持的数据类型:
-
数值型
整数类型:tinyint:微整型 smallint:小整型 int:整型,MySQL默认 bigint:大整型
小数类型:又被称为“浮点型”,decimal(总位数,小数位),MySQL默认
例:价格 decimal(5,2) 999.99 float(总位数,小数位) double(总位数,小数位)
-
日期时间类型
date 年月日yyyy–mm–dd
time 时间hh:mm:ss
year 年份yyyy
datetime 日期时间,MySQL默认
-
字符串类型
char(长度):定长字符串类型,如果传递的数据值长度未达到指定长度,系统会用空格给占用,不会做释放
例:name char(10)——>tom:3个字符,还有7个字符长度空间未利用,系统直接给空格占用
varchar(长度):变长字符串类型,如果传递的数据值长度未达到指定长度,系统直接释放,不会占用
例:name varchar(10)——>tom:3个字符,剩下7个字符长度空间,直接释放
-
-
创建表的操作:
-
每一张表的创建,一定找好它所属的数据库
-
切换数据库语法:use 数据库名字;
经过切换之后,就来到了指定的数据库下进行操作
-
表创建:创建一个学生信息表(学号 字符串15,姓名 字符串20,年龄 整数,入学年份 year)
练习:a.创建一个学校的数据库:schooldb
b.切换到学校的数据库,进行以下列表的创建
b.1创建student表(sno 字符串类型15,sname 字符串10,sage 微整型,入学时间 日期时间类型)
b.2创建选课表(学号 字符串类型15,课程号 字符串类型5,成绩 整型)
b.3创建教师表(教师编号 字符串10,教师姓名 字符串类型10,专业 字符串类型8,薪资 小数类型8,2,入职年份year)

-
-
删除表语法:
drop table 表名1,表名2…;
-
修改表结构:alter table 系列语句
-
添加列
alter table 表名 add 列名 数据类型;
-
删除列
alter table 表名 drop 列名;
-
修改列的数据类型
alter table 表名 modify 列名 新的数据类型;
-
修改列名
alter table 表名 change 旧列名 新列名 数据类型(新的数据类型);
-
-
显示表结构:desc 表名;
-
数据库常见的专业名词
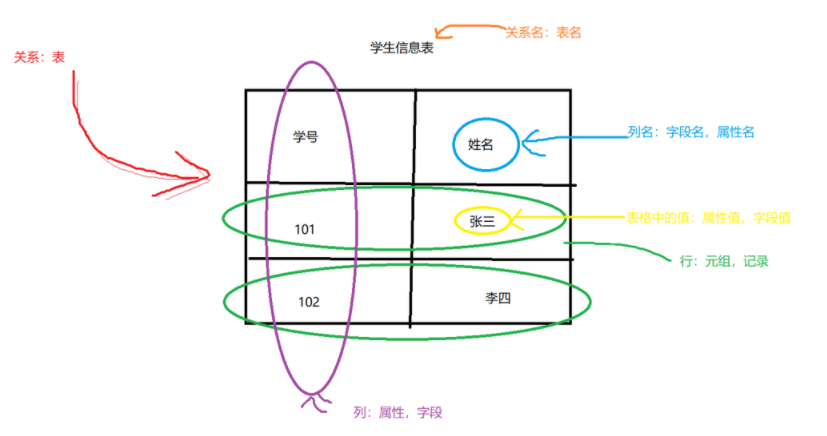
关系:表 例:一个关系——>一张表
关系名:表名
表中的行:元组,记录 例:表中有3个元组——>3行数据/3条记录
表中的列:属性,字段 例:表中有3个字段——>3个属性/3个列
表中的列名:属性名,字段名
表中的值:属性值,字段值
SQL:结构化查询语言
库的操作:
创建:create database 数据库名字;
查看:show databases;
删除:drop database 数据库名字;
切换:use 数据库名字;
表的操作:
创建:create table 表名(
列名1 数据类型,
…
列名n 数据类型
);
删除:drop table 表名;
修改:alter table 表名; 系列语句
添加:add 列名 数据类型;
删除列 drop 列名;
修改列的数据类型 modify 列名 新的数据类型;
修改列名 change 旧列名 新列名 新的数据类型;
显示表结构:desc 表名;
5、表中约束的使用
约束:(给一张表添加)限制,要求,规则……
-
为了保证数据库表中数据的完整性(指的是存储在数据库表中的数据是准确的和可靠的),就引入了约束的应用。
-
关系的完整性约束
-
为了实现表结构以及表中数据的完整性,约束可以从三个角度来考虑(约束的分类):实体完整性约束,域完整性约束,参照完整性约束。
-
实体完整性约束:
-
思想:保证表中数据的唯一性,至少不会出现重复的数据
-
提供的两个约束:主键约束,唯一约束
-
主键约束 primary key 最多有一个
①思想:唯一,不重复,不为空
②创建表的同时关联主键约束
格式一:
create table 表名(
列名1 数据类型 primary key,
列名2 数据类型
);
格式二:
create table 表名(
列名1 数据类型,
列名2 数据类型,
constraint 主键约束的名字 primary key(列名1)
);
备注:主键约束的名字:如果需求给了,我们直接照搬使用;如果没给名字,名字自定义:PK_列名
constraint:约束
格式三:
create table 表名(
列名1 数据类型,
列名2 数据类型,
primary key(列名1)
);
③针对已经存在的表关联主键约束
格式一:alter table 表名 add primary key(列名);
格式二:alter table 表名 add constraint 主键约束的名字 primary key(列名);
格式三:alter table 表名 modify 列名 数据类型 primary key;
④删除主键约束
格式:alter table 表名 drop primary key;
-
联合主键
①思想:本质上还属于主键约束,只不过primary key变成修饰两个列的操作,把这两个列,看成是一个整体,共同遵守主键约束的特性:唯一,不重复,不为空
②创建表的同时关联联合主键
格式二:
create table 表名(
列名1 数据类型,
列名2 数据类型,
constraint 主键约束的名字 primary key(列名1,列名2)
);
格式三:
create table 表名(
列名1 数据类型,
列名2 数据类型,
primary key(列名1,列名2)
);
③针对已经存在的表关联联合主键
格式一:alter table 表名 add primary key(列名1,列名2);
格式二:alter table 表名 add constraint 主键约束的名字 primary key(列名1,列名2);
注意:一个表中,不管是单列的主键约束,还是联合主键,有且只能有一个(它俩是互斥的)
练习:
a.创建选课表(学号,姓名,课程号,课程名,课时,其中学号和课程号设置为联合主键,主键名为PK_NO)
b.创建考勤表(学号,出勤时间,上课时长,其中学号和出勤时间设置为联合主键)
c.针对已经存在的任意两张表,选择任意两列,添加联合主键
d.删除任意两张表中的联合主键

-
唯一约束 unique
①思想:保证数据的唯一性,不允许有重复的值,但是可以有空值;一个表中可以有多个唯一约束;如果不给唯一约束起名字,默认和列名保持一致
②创建表的同时关联唯一约束
格式一:
create table 表名(
列名1 数据类型 unique,
列名2 数据类型 unique,
列名3 数据类型
);
格式二:
create table 表名(
列名1 数据类型,
列名2 数据类型,
列名3 数据类型,
constraint 唯一约束的名字 unique(列名1),
constraint 唯一约束的名字02 unique(列名2)
);
备注:唯一约束的名字:如果需求给了,我们直接照搬使用;如果没给可以自定义:UN_列名
③针对已经存在的表关联唯一约束
格式:alter table 表名 add unique(列名);
④删除唯一约束
格式:alter table 表名 drop index 唯一约束的名字;
练习:
a.创建一个电影表(电影编号 主键约束,电影片名 唯一约束,时长,类别 唯一约束)
b.创建一个商品表(商品编号 主键约束:PK_编号,商品名称 唯一约束:UN_名称,价格)
c.针对已经存在的表,任意选择两个找出合适的列,添加唯一约束
d.删除任意两张表的唯一约束
-
-
-
域完整性约束
思想:保证表中不会输入无效的值,提供了两个约束:默认约束,非空约束
-
默认约束 default
①思想:表中的列如果设置有默认约束,那么该列不进行填充数据时,就会把默认值直接补上;一个表中可以有多个默认约束
②创建表的同时关联默认约束
create table 表名(
列名1 数据类型 default 默认值,
列名2 数据类型 default 默认值,
列名3 数据类型
);
备注:如果默认的值是数字,就直接写数据;是字符串或日期时间,需要加上引号(单双引号都可)
③针对已经存在的表关联默认约束
格式:alter table 表名 modify 列名 数据类型 default 默认值;
④删除默认约束
格式:alter table 表名 modify 列名 数据类型;
练习:
a.创建一张表tempStudent,包括sno,sname,sdept,sage四 列,为sno添加主键、sname唯一、sdept默认”软件测试” , sage非空约束
b.找到任意一张表,给任意一个列,添加默认约束
c.删除tempStudent表的sdept默认约束

-
非空约束 not null
思想:不能有空的情况;一个表中可以有多个非空约束
①创建表的同时关联非空约束
create table 表名(
列名1 数据类型 not null,
列名2 数据类型 not null,
列名3 数据类型
);
②针对已经存在的表关联非空约束
格式:alter table 表名 modify 列名 数据类型 not null;
③删除非空约束
格式:alter table 表名 modify 列名 数据类型;
练习:
a.创建一个订单表(订单编号 主键约束,订单名称 非空约束,手机号 唯一约束,收货地址 默认是河南)
b.针对已有的表,找到其中一个列,设置为非空约束
c.删除任意一个表中的非空约束

-
-
主键约束:primary key:唯一,不重复,不为空——>最多只能有一个
唯一约束:unique:不允许有重复的值,可以有空值
默认约束:default:默认值会进行填充
非空约束:not null:不能有空值
- 参照完整性约束:外键约束 foreign key
①思想:针对两张表来进行的操作,他会把其中的一张表看成是【主表】,另外一张表看成是【从表】,从表参照主表;主表与从表之间建立参照关系,实质上是通过两个表中公有的列来完成的:通过从表中的列,参照引用主表中的列,建立起联系;列名可以不一致,但是列的数据类型和内容保持一致;外键约束是建立在从表的列中;主表中被参照引用的列,必须是主键约束或唯一约束;
主表与从表一旦建立起外键约束,对从表的限制:从表如果想要进行数据的插入操作,首先得“询问主表的意见”,主表有关联的数据,才能允许从表做插入的操作;
==对主表的限制:主表如果想要删除数据,需要“询问从表的意见”,主表数据被从表正在参照引用,那么该数据主表是无法删除的;==从表中的外键约束也可以有多个:一个从表可以参照引用多个主表,或者,一个主表也可以被多个从表参照引用
加强表与表之间的联系
②创建表的同时关联外键约束
create table 主表表名(
列名1 数据类型 primary key,
列名2 数据类型
);
create table 从表表名(
列名1 数据类型,
列名2 数据类型,
列名3 数据类型,
constraint 外键约束的名字 foreign key(从表列名1) references 主表表名(主表列名1),
constraint 外键约束 的名字2 foreign key(从表列名2) references 主表表名2(主表列名2)
);
备注:外键约束的名字,如果需求给了,我们就照搬使用;如果没有给,自定义名字:FK_列名
练习:
a.创建工人表(工人编号 主键约束,姓名,年龄)
b.创建薪资表(工人编号,部门,薪资,其中工人编号参照引用工人表的工人编号)
c.创建一张表,让该表参照引用已经建立好的任意两张表,建立外键约束关系

③针对已经存在的表来关联外键约束
格式:alter table 从表表名 add constraint 外键约束的名字 foreign key(从表列名) references 主表(主表列名);
④删除外键约束
格式:alter table 表名 drop foreign key 外键约束的名字;
练习:
a.找到其中任意一张表,设置外键约束,关联另外一张主表
b.删除其中两张表的外键约束
6、插入数据
- SQL语言分类:
DDL语言:数据定义语言:create语句,alter语句,drop语句——实现对库或表的创建,修改,删除操作
DML语言:数据操作/操纵语言:insert语句,delete语句,update语句——实现对表中数据的增删改操作
DQL语言:数据查询语言:select语句——实现对表中数据的查询操作
- insert语句:实现对表中数据的插入操作(增加数据):值和列名一定是匹配的(一一对应)
格式一:insert into 表名(列名1,列名2,列名3…) values(值1,值2,值3…);
格式二:insert into 表名 values(值1,值2,值3…);
格式三:insert into 表名 values(值1,值2,值3…),(值1,值2,值3…),(值1,值2,值3…);
备注:如果插入的数据是:字符串或日期时间,需要加引号;数字直接写
7、删除数据
delete语句:删除表中的数据
- 删除表中所有的数据:delete from 表名;
- 有条件的删除:delete from 表名 where 条件;
条件中可以用到的比较运算符:
= 例:性别=‘男’
> 例:年龄>18
< 例:年龄<30
>= 例:成绩>=80
<= 例:成绩<=50
!= <> 不等于 例:籍贯 !=‘北京’
多条件的删除操作:
①多个条件同时满足:and——>where 条件1 and 条件2 and 条件3…;
②多个条件只需要满足其中任意一个:or——>where 条件1 or 条件2 or 条件3….;
8、更新数据
update语句:实现表中数据修改操作
- 格式一:
update 表名 set 列名=新值;
- 格式二:
update 表名 set 列名1=新值,列名2=新值,列名3=新值…;
- 格式三:有条件的更新
update 表名 set 列名1=值,列名2=值 where 条件;
update student set sage=18 where ssex=‘女’ or sage>20;
场景:在更新数据的过程中,也可以进行计算的操作
- 外键约束 foreign key:实现两个表之间的参照关系:从表:插入数据,主表:删除数据——>加强表与表之间的联系
- 数据的增删改
增:insert into 表名 values(值1,值2…);
删:delete from 表名 where 条件;
改:update 表名 set 列名=值 where 条件;
9、查询的基本操作
- 查询select:针对数据库表中的数据按照特定的组合,条件,次序进行检索查看的操作
- 查询的基本语法:
select 列名1,列名2,列名3… from 表名;
select字句:写的是要查询的列,告诉要“查什么”
from字句:写的是查询用到的表,告诉“从哪查”
查看表中所有的数据:select * from 表名; *任意,所有
- 别名查询:针对查询结果的标题,进行另起名字的操作
格式一:
select 列名1 别名1,列名2 别名2,列名3 别名3… from 表名;
格式二:as关键字
select 列名1 as 别名,列名 as 别名… from 表名;
- 去重复查询:针对列中重复的数据,去重后进行查看显示(将查询的结果去重复之后再显示)
格式:select distinct 列名 from 表名;
- 在查询的过程中,也可以进行查询结果的计算操作
格式:select 计算公式 别名 from 表名;
- 选择查询(条件查询):where子句
格式:select 列名 from 表名 where 条件;
①比较搜索条件:比较运算符 = > < > = <= <> !=
②逻辑运算符:and or
③范围搜索条件查询:
1.在范围之内的数据:between 开始值 and 结束值;
格式:select 列名 from 表名 where 列名 between 开始值 and 结束值;
2.排除在范围之内的数据:not between 开始值 and 结束值;
格式:select 列名 from 表名 where 列名 not between 开始值 and 结束值;
备注:开始值和结束值,也会参与查询的过程
④列表搜索条件查询:
1.匹配列表中的数据(任意一个):in(值1,值2,值3…)
格式:select 列名 from 表名 where 列名 in(值1,值2,值3…);
思想:只要条件中的列,匹配到列表中任意一个值,就会有相关的查询结果(记录)
2.排除列表中的数据:not in(值1,值2,值3…)
格式:select 列名 from 表名 where 列名 not in(值1,值2,值3…);
思想:只要是列表中的值,都把他们排除在外
⑤模糊查询:字符串匹配查询
1.匹配和字符模板相关的数据:like ‘字符模板’
格式:select 列名 from 表名 where 列名 like ‘字符模板‘;
2.排除和字符模板相关的数据:not like ‘字符模板’
格式:select 列名 from 表名 where 列名 not like ‘字符模板’;
通配符:
% 任意个字符(零个或多个)
_ 单个字符
⑥空值查询:
1.查询记录中有为空的信息:is null
格式:select 列名 from 表名 where 列名 is null;
2.查询记录中不为空的信息:is not null
格式:select 列名 from 表名 where 列名 is not null;
⑦聚合函数:实现对列中数据的计算操作
sum(列名) 求和
avg(列名) 求平均值
max(列名) 最大值
min(列名) 求最小值
count(*) 统计元组的个数(行数)
count(列名) 统计该列中值的总个数
备注:除了count(*)之外,其他聚合函数操作时,均忽略空值
格式:select 聚合函数 from 表名 where 条件;
⑧行数限定查询:limit
格式一:select 列名 from 表名 limit 行数; ——–>默认从第一行开始查看
格式二:select 列名 from 表名 limit 开始位置下标,行数;
⑨分组查询:针对查询的结果,按照某个列来进行划分(分组) group by
格式:select 列名,聚合函数 from 表名 group by 列名;
⑩having:针对分组后的数据,进行条件筛选的操作
备注:having的使用,必须搭配group by; having后面大部分都是聚合函数当条件,where后面不能直接写聚合函数
格式:select 列名,聚合函数 from 表名 group by 列名 having 分组的条件;
⑪.排序:order by :针对查询的结果,按照某个列进行排序:升序asc 默认,降序desc
格式:select 列名 from 表名 order by 列名 asc|desc;
备注:聚合函数(distinct 列名):对列中的值,进行去重复后,再来进行计算操作
例:sum(distinct grade):先对成绩去重,然后再来进行求和
select 列名
from 表名
where 条件
group by 分组的列名
having 分组条件(聚合函数当条件)
order by 排序列名 asc|desc;
去重复:distinct
聚合函数:sum(列名) avg(列名) max(列名) min(列名) count(*):行的总数量 count(列名):值的总个数
行数限定:limit
10、MySQL常用的函数(了解)
- 字符串函数
length() 统计字符串的字节长度
char_length() 统计字符串长度
mid(字符串数据,开始的位置,截取的字符个数)
统计字符串字节长度 一个汉字占3个字节,一个字母占1个字节
- 数学函数
round():四舍五入
round(数字,保留小数位) 指定保留小数位的四舍五入
round(数字) 保留整数
least(值1,值2,值3…) 求最小值
greatest(值1,值2,值3…) 求最大值
- 日期时间函数
now() 获取当前日期时间
current_date() 获取当前日期
current_time() 获取当前时间
to_days() 计算总天数(从0开始计算)
dayofyear() 计算该年已过的天数
week() 统计日期所在的周数
- 控制函数
if(布尔表达式,参数一,参数二) true:执行参数一,false:执行参数二
if(null,参数一,参数二) 直接执行参数二
ifnull(参数一,参数二) 参数一有值,直接查询,如果为null,就查参数二
11、多表查询操作
- 概述:在实际操作过程中,我们所需要的数据,可能会来源于多张表,这个时候就需要进行多表连接,实现查询的操作
- 多表查询的实现方式:表连接
- 表连接查询的分类:内连接查询,外连接查询
- 内连接:思想:只有表与表之间匹配到的数据,才会被查询出来
①格式一:通过where实现连接
select 表名1.列名1,表名1.列名2,表名2.列名1,表名3.列名1,表名4.列名1…
from 表名1,表名2,表名3,表名4,…
where 表名1.列名=表名2.列名 and 表名2.列名=表名3.列名 and 表名3.列名=表名4.列名… and 其他条件;
②格式二:通过**(inner) join on**实现连接 inner可以省略 inner join:内连接
select 表名.列名
from 表名1 inner join 表名2
on 表名1.列名=表名2.列名 inner join 表名3
on 表名2.列名=表名3.列名 inner join 表名4
on 表名3.列名=表名4.列名…
where 其他的条件;
备注:表与表之间建立连接的列:列名可以不一致,但是列的数据类型和内容保持一致;
可以利用别名对表名进行重命名做替代的操作:表明 别名;
如果查询的列只在其中的一张表出现,那么可以省略表名,直接写列名;如果查询的列,多张表都有,一定要加上表名:表名.列名;条件中的列名前方应该也加上表名:表名.列名,但是同样遵守以上原则
③多表连接查询做题思想:
(1)确定表:根据题意描述,确定会用到的表
(2)确定表与表之间能够建立连接的列
(3)确定要查询的列
(4)确定是否有额外的条件,如果有,就关联其他的条件
多表查询:表连接:
内连接:思想:只有表与表之间匹配到的数据,才会被查询出来
select 表名.列名
from 表名1,表名2,表名3…
where 表名1.列=表名2.列 and 表名2.列=表名3.列 and 其他条件;
[inner] join in
select 表名.列名
from 表名1 inner join 表名2
on 表名1.列名=表名2.列名 inner join 表名3
on 表明2.列名=表名3.列名…
where 其他条件;
备注:针对inner join on连接方式:可以分为:等值连接查询和非等值连接查询,判定方式:就看条件中除了等号以外,是否还有其他的比较运算符
- 外连接:思想:至少会返回一个表的所有内容
- 左外连接:会返回左表的所有内容;左表的数据在右表中匹配不到,默认位置就为空null
- 区分左右表:先写的表是:左表;后写的表是:右表
select 表名.列名
from 表名1 left [outer] join 表名2
on 表名1.列名=表名2.列名
3.右外连接:会返回右表的所有内容;右表的数据在左表中匹配不到,默认位置就为空null
select 表名.列名
from 表名1 right [outer] join 表名2
on 表名1.列名=表名2.列名
12、子查询
- 子查询:指的是查询语句中,嵌套查询语句,一般出现在where后面,表示条件的
- 子查询的应用场景:
①看似题上给了条件,但是条件的结果并没有明说,需要给查询出来
②where后面不能直接写聚合函数,那么就可以通过子查询把聚合函数的结果给查出来,拿上结果值做操作即可
- 子查询语法:
格式一:通过in匹配子查询的结果 嵌套子查询
select 列名 from 表名 where 列名 in(select 列名 from 表名 where 条件);
备注:假如子查询语句前面使用not in,相当于把子查询的结果排除在外
格式二:通过“=”匹配子查询的结果 相关(单值)子查询
select 列名 from 表名 where 列名=(select 列名 from 表名 where 条件);
注意:①==外查询的条件要什么,子查询就查什么,一定做好匹配,比如:条件要学号,子查询就只能查学号;②“=”匹配的子查询结果只能有一个==,而in匹配子查询结果是可以有任意个,很多时候我们无法把控子查询结果的个数,就可以优先考虑in
格式三:通过比较运算符匹配子查询的结果
select 列名 from 表名 where 列名 比较运算符(select 列名 from 表名 where 条件);
- insert和select结合使用
- 思想:把查询的结果,插入到指定的表中
- 格式:insert into 表名 select语句:
- update和select结合使用
格式:update 表名 set 列名=值 where 列名 in(select 列名 from 表名 where 条件);
备注:参考select语句中嵌套select语句的套路,都是放在where后面,表示条件
- delete和select结合使用
格式:delete from 表名 where 列名 in(select 列名 from 表名 where 条件);
备注:也是放在where后面,表示条件
子查询:嵌套查询语句
select语句+子查询
delete语句+子查询
update语句+子查询
——>都是放在where后面,表示条件
insert语句+子查询
13、视图的概述
- 定义:视图基于某个查询结果的虚表:视图(虚表)——>对实表进行查询;视图的结构,取决于对实表的查询过程和结果;对表进行增删改查的操作,放在视图中同样成立,把表名换成视图的名字。
- 注意:视图<——>增删改insert,update,delete操作<——>实表(基表),互为影响
- 作用:方便用户实现对数据的操作
14、视图(view)的操作
- 创建视图:
create view 视图的名字 as select语句;
-
修改视图结构
-
视图插入数据:参考insert语法
insert into 视图名字 values(值1,值2,值3…);
-
修改结构
alter view 视图的名字 as select语句;
-
修改视图数据:参考update语法
update 视图的名字 set 列名=值 where 条件;
-
-
删除视图
-
删除视图的数据:参考delete语句
delete from 视图的名字 where 条件;
-
删除视图
drop view 视图的名字;
-
15、索引概述
- 描述:索引是针对表中的列来进行设置的;一个表中索引的设置没有个数限制;索引能够快速定位获取表中的数据;设置索引的列会自动给插入的数据进行排序;索引技术服务于查询操作,提高查询效率
例:如果把一张表看成是一本书,索引就相当于书本的目录
- 索引的作用(优点)
①加快数据的检索(查看,查询)——>最根本的作用
②保证数据的唯一性——>唯一索引
③实现表与表之间的参照完整性——>加强表与表之间的联系
④减少group by分组,order by排序的时间
- 索引的缺点
①创建索引需要花费时间和消耗数据空间
②索引的存在会减慢数据的增删改的速度
③对小表(数据少)建立索引不会产生优化的效果
④表中数据量越大,索引的优势就越明显
- 优先考虑建立索引的列:
- 定义有主键或外键约束的列
- 频繁查询的列
- 连接中频繁使用的列——>表连接的列,子查询的列
- 分组或排序的列
16、索引(index)的操作
- 创建普通索引:
create index 索引的名字 on 表名(列名);
- 创建唯一索引:
create unique index 索引的名字 on 表名(列名);
- 删除索引:
drop index 索引的名字 on 表名;
- 视图——>基于某个实表的查询结果——>虚表
创建视图:create view as select语句;
修改视图结构:alter view 视图名字 as select语句;
增删改查——>insert,delete,update,select——>视图
删除视图:drop view 视图名字;
- 索引:作用(优点),缺点,优先考虑建立索引的列
create [unique] index 索引的名字 on 表名(列名);
drop index 索引的名字 on 表名;