A Survey for In-context Learning
摘要:
随着大语言模型(LLMs)能力的增长,上下文学习(ICL)已经成为一个NLP新的范式,因为LLMs仅基于几个训练样本让内容本身增强。现在已经成为一个新的趋势去探索ICL来评价和extrapolate LLMs的能力。在这篇文章中,我们目的是调查并总结ICL的过程,挑战和未来的工作。我们首先呈现了一个ICL正式的定义和阐明了它和相关研究的关系。然后,我们组织并讨论了关于ICL先进的技术,包括训练策略,提示策略等等。最后,我们展示了ICL的挑战和提供了未来研究的潜在方向。我们希望我们的工作在未来可以鼓励更多的研究在发掘ICL是如何工作和提升ICL性能上。
1. 引言
随着模型规模和语料库规模的缩放(Devlin等人,2019;Radford等人,2019;布朗等人,2020年;Chowdhery et al., 2022),大型语言模型(LLMs)展示了一种上下文内学习(ICL)能力,即从上下文中的几个例子中学习。许多研究表明,llm可以通过ICL执行一系列复杂的任务,例如解决数学推理问题(Wei et al., 2022c)。这些强大的能力已被广泛验证为大型语言模型的新兴能力(Wei et al., 2022b)。
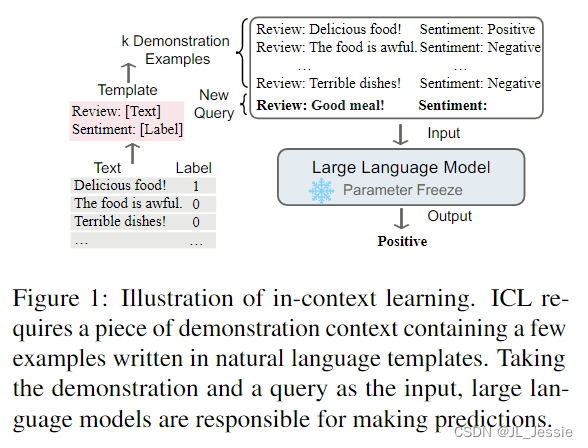
上下文学习的关键思想是从类比中学习。图 1 给出了一个例子,描述了语言模型如何使用 ICL 做出决策。首先,ICL 需要几个例子来形成演示上下文。这些示例通常以自然语言模板编写。然后,ICL 将查询问题和一段演示上下文连接在一起形成一个提示,然后将其输入语言模型进行预测。与需要使用后向梯度更新模型参数的训练阶段的监督学习不同,ICL 不进行参数更新,直接对预训练的语言模型进行预测。期望该模型能够学习隐藏在演示中的模式,并据此做出正确的预测。
作为一种新的范式,ICL 具有多种吸引人的优势。首先,由于演示是用自然语言编写的,因此它提供了一个可解释的界面来与 LLM 进行通信(Brown 等人,2018 年)。这种范式通过改变演示和模板将人类知识融入 LLM 变得更加容易(Liu et al., 2022; Lu et al., 2022; Wu et al., 2022; Wei et al., 2022c)。其次,上下文内学习类似于人类通过学习类比的决策过程(Winston,1980)。第三,与监督训练相比,ICL 是一个无训练学习框架。这不仅可以大大降低使模型适应新任务的计算成本,还可以使语言模型作为服务(Sun et al., 2022)成为可能,并且可以很容易地应用于大规模的现实世界任务。
尽管ICL很有前途,但也有一些有趣的问题和有趣的性质需要进一步研究。虽然普通GPT-3模型本身显示出有希望的ICL能力,但一些研究发现,通过预训练期间的适应,这种能力可以显著提高(Min等人,2022b;Chen et al., 2022c)。此外,ICL的性能对特定设置很敏感,包括提示模板、上下文示例的选择、示例的顺序等(Zhao et al., 2021)。此外,ICL的工作机制虽然直观合理,但尚不清楚,很少有研究提供初步解释(Dai et al., 2022;von Oswald et al., 2022)。
随着ICL研究的快速增长,我们的调查旨在提高社区对当前进展的认识。具体而言,我们提供了一份详细的论文调查和一份将不断更新的论文列表,并对ICL的相关研究进行了深入讨论。我们强调了挑战和潜在的方向,并希望我们的工作可以为对这一领域感兴趣的初学者提供一个有用的路线图,并为未来的研究提供帮助。
2. Overview
ICL的强大性能依赖于两个阶段:(1)培养LLM的ICL能力的训练阶段,以及(2)LLM根据任务特定演示进行预测的推理阶段。就训练阶段而言,LLM直接针对语言建模目标进行训练,例如从左到右生成。尽管这些模型没有专门针对上下文学习进行优化,但它们仍然表现出ICL的能力。现有的ICL研究基本上是以训练有素的LLM为骨干,因此本次调查不会涵盖预训练语言模型的细节。在推理阶段,由于输入和输出标签都用可解释的自然语言模板表示,因此有多个方向可以提高ICL的性能。本文将进行详细的描述和比较,例如选择合适的示例进行演示,并为不同的任务设计具体的评分方法.
我们按照上面的分类法组织ICL中的当前进展(如图2所示)。通过ICL的正式定义(§3),我们对热身方法(§4)、演示设计策略(§5)和主要评分函数(§6)进行了详细讨论。§7深入讨论了当前关于揭开ICL背后秘密的探索。我们进一步为ICL提供了有用的评估和资源(§8),并介绍了ICL显示其有效性的潜在应用场景(§10)。最后,我们总结了挑战和潜在的方向(§11),并希望这能为该领域的研究人员铺平道路。

3. Definition and Formulation
遵循 GPT-3 (Brown et al., 2020) 的论文,我们提供了上下文学习的定义:上下文学习是一种范式,它允许语言模型以演示的形式仅给出几个例子来学习任务。本质上,它通过使用训练有素的语言模型来估计以演示为条件的潜在答案的可能性。
形式上,给定查询输入文本 x 和一组候选答案 Y = {y1,., ym}(Y 可以是类标签或一组自由文本短语),预训练的语言模型 M 将得分最高的候选答案作为预测条件演示集 C。C 包含一个可选的任务指令 I 和 k 个演示示例;因此,C = {I, s(x1, y1),., s(xk, yk)} 或 C ={s(x1, y1),., s(xk, yk)},其中 s(xk, yk, I) 是根据任务用自然语言文本编写的示例。候选答案 yj 的可能性可以用模型 M 的整个输入序列的评分函数 f 表示:
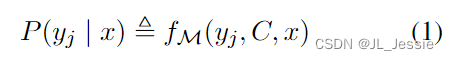
最终预测标签 ^y 是概率最高的候选答案:
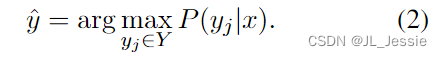
评分函数f估计给出演示和查询文本的当前答案的可能性。例如,我们可以通过比较否定和肯定的标记概率来预测二元情感分类中的类标签。对于不同的应用,有许多f变体,这将在§6中详述。
根据定义,我们可以看到ICL与其他相关概念的区别。(1) 提示学习:提示可以是鼓励模型预测期望输出的离散模板或软参数。严格来说,ICL可以被视为提示调优的一个子类,其中演示是提示的一部分。刘等(2021)对prompt learning进行了深入调查。但是,ICL不包括在内。(2) Fewshot Learning:few shot learning是一种通用的机器学习方法,它使用参数自适应,以有限数量的监督示例学习任务的最佳模型参数(Wang和Yao,2019)。相比之下,ICL不需要参数更新,直接在预训练的LLM上执行。
4. Model Warmup (模型预热)
尽管 LLM 显示出有希望的 ICL 能力,但许多研究也表明 ICL 能力可以通过预训练和 ICL 推理之间的持续训练阶段进一步改进,我们称之为模型预热很短。Warmup 是 ICL 的可选程序,它在 ICL 推理之前调整 LLM,包括修改 LLM 的参数或添加额外的参数。与微调不同,预热的目的不是针对特定任务训练LLM,而是增强了模型的整体ICL能力。
4.1 有监督的上下文训练
为了提高 ICL 能力,研究人员通过构建上下文训练数据和多任务训练提出了一系列有监督的上下文微调策略。由于预训练目标没有针对上下文学习进行优化(Chen et al., 2022a),Min 等人。 (2022b) 提出了一种方法 MetaICL 来消除预训练和下游 ICL 使用之间的差距。使用演示示例在广泛的任务上不断训练预训练的 LLM,这提高了其fewshot 能力。为了进一步鼓励模型从上下文中学习输入标签映射,Wei 等人。 (2023a) 提出了符号调整。这种方法在上下文输入标签对上微调语言模型,用任意符号(例如,“foo/bar”)替换自然语言标签(例如,“正/负面情绪”)。因此,符号调整展示了一种增强的能力,以利用上下文信息来覆盖先前的语义知识。
- Lamda: Language models for dialog applications.
- Scaling Instruction-Finetuned Language Models
- Jason Wei:
-
Finetuned Language models are zero-shot learners. -
Emergent abilities of large language models. -
Chain of though prompting elicits reasoning in large language models. -
symbol tuning improves in-context learning in language models.
4.2 自监督上下文训练
利用原始语料库进行预热,Chen 等人。 (2022a) 提出了在下游任务中构建与 ICL 格式对齐的自监督训练数据。他们将原始文本转换为输入输出对,探索了四个自监督目标,包括掩码标记预测和分类任务。或者,PICL (Gu et al., 2023) 也使用了原始语料库,但采用了简单的语言建模目标,基于上下文促进任务推理和执行,同时保留预训练模型的任务泛化。因此,PICL 在有效性和任务泛化性方面优于 Chen 等人。 (2022a) 的方法
- Mingda chen 2022a: Improving In-Context Few-Shot Learning via Self-Supervised Training
- Yuxian Gu: Pre-Training to Learn in Context
要点:
(1)监督训练和自我监督训练都建议在 ICL 推理之前训练 LLM。关键思想是通过引入接近上下文学习的目标来弥合预训练和下游 ICL 格式之间的差距。与涉及演示的上下文微调相比,没有几个例子的指令微调更简单、更受欢迎。
(2)在一定程度上,这些方法都是通过更新模型参数来提高ICL能力,这意味着原始llm的ICL能力有很大的改进空间。因此,虽然 ICL 并不严格要求模型预热,但我们建议在 ICL 推理之前添加一个预热阶段。
(3) 当训练数据越来越大时,热身带来的性能提升会遇到一个平稳期。这种现象既出现在有监督的上下文训练中,也出现在自我监督的上下文训练中,这表明LLM只需要少量的数据就可以适应在热身期间从上下文中学习。
5. 演示样例设计 Demonstration Designing
许多研究表明,ICL 的性能强烈依赖于演示设计,包括演示格式、演示示例的顺序等(Zhao et al., 2016; Lu et al., 2022)。由于演示在 ICL 中起着至关重要的作用,在本节中,我们调查演示设计策略并将它们分为两类:演示组织和演示格式,如表 1 所示。
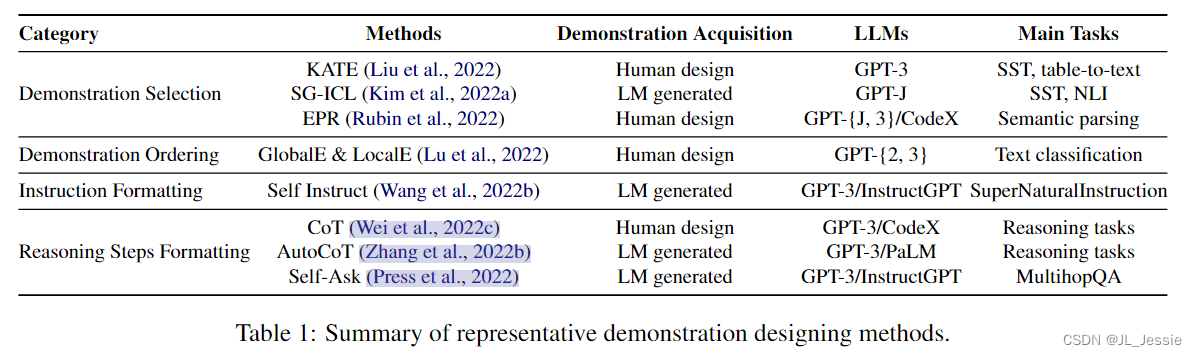
5.1 演示的组织方式
在给定一个训练示例池的情况下,演示组织的重点是如何选择一个示例子集以及所选示例的顺序。
5.1.1 演示选择
示范选择旨在回答一个基本问题:哪些例子是ICL的好例子?我们将相关研究分为两类,包括基于预定义指标的无监督方法和有监督方法。
无监督方法: 刘等人(2022)表明,选择最近的邻居作为上下文示例是一个很好的解决方案。距离度量是基于句子嵌入的预定义L2距离或余弦相似性距离。他们提出了KATE,一种基于kNN的无监督检索器,用于选择上下文示例。除了距离度量外,互信息也是一个有价值的选择度量(Sorensen等人,2022)。类似地,可以为多语言ICL检索k-NN跨语言演示(Tanwar等人,2023),以加强源-目标语言对齐。互信息的优点在于,它不需要标记的示例和特定的LLM。此外,Gonen等人(2022)试图选择困惑度较低的提示。Levy等人(2022)考虑了演示的多样性,以提高构图的泛化能力。他们选择不同的演示来涵盖不同类型的培训演示。与这些从人类标记数据中选择实例的研究不同,Kim等人(2022a)提出从LLM本身生成演示。
其他一些方法利用 LM P (y|C, x) 的输出分数作为无监督指标来选择演示。Wu等人(2022)根据数据传输的代码长度选择了kNN示例的最佳子集排列,以压缩给定x和C的标签y。Nguyen 和 Wong (2023) 通过计算演示子集 {C|xi ∈ C} 和 {C|xi /∈ C} 的平均性能之间的差异来衡量演示 xi 的影响。此外,Li 和 Qiu (2023a) 使用 infoscore,即验证集中所有 (x, y) 对的 P (y|xi, yi, x) - P (y|x) 的平均值具有多样性正则化。
- What Makes Good In-Context Examples for GPT-3?
- Groundtruth labels matter: A deeper look into inputlabel demonstrations.
有监督方法: Rubin等人(2022)提出了一种两阶段检索方法来选择演示。对于特定的输入,它首先构建了一个无监督检索器(例如 BM25)来回忆与候选者相似的示例,然后构建一个有监督的检索器 EPR 从候选者中选择演示。评分 LM 用于评估每个候选示例和输入的串联。高分的候选者被标记为正例,得分低的候选者是硬负例。Li et al.(2023f)通过采用统一的演示检索器来统一不同任务的演示选择,进一步增强了EPR。Ye等人(2023a)检索了整套演示,而不是单个演示来模拟演示之间的相互关系。他们训练了一个 DPP 检索器,通过对比学习与 LM 输出分数对齐,并在推理时获得了具有最大后验的最佳演示集。
基于提示调优,Wang 等人。 (2023e) 将 LLM 视为主题模型,可以从很少的演示中推断出概念 θ,并根据概念变量 θ 生成标记。他们使用与任务相关的概念标记来表示潜在概念。学习概念标记以最大化 P (y|x, θ)。他们选择最有可能基于 P (θ|x, y) 推断概念变量的演示。此外,Zhang 等人介绍了强化学习。 (2022a) 例如选择。他们将演示选择制定为马尔可夫决策过程(Bellman,1957),并通过 Q 学习选择演示。动作是选择一个示例,奖励定义为标记验证集的准确性。
- Large language models are implicitly topic models: Explaining and finding good demonstrations for in-context learning.
- Active example selection for in-context learning
5.1.2 演示顺序 Demonstration Ordering
对选定的演示示例进行排序也是演示组织的一个重要方面。Lu等人(2022)已经证明,顺序敏感性是一个常见问题,并且总是存在于各种模型中。为了解决这个问题,以前的研究已经提出了几种无训练的方法来对演示中的示例进行排序。Liu等人(2022)根据示例到输入的距离对示例进行了不错的排序,因此最右边的演示是最接近的示例。Lu等人(2022)定义了全局和局部熵度量。他们发现熵度量与 ICL 性能之间存在正相关。他们直接使用熵度量来选择示例的最佳排序。
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
5.2 演示格式 Demonstration Formating
格式化演示的常用方法是连接示例(x1, y1),……, (xk, yk)直接使用模板T。然而,在一些需要复杂推理的任务中(例如,数学应用题,常识推理),仅用k个演示就能学会从xi到yi的映射并不容易。虽然已经在提示中研究了模板工程(Liu et al., 2021),但一些研究人员旨在通过使用指令I(§5.2.1)描述任务,并在xi和yi之间添加中间推理步骤(§5.2.2),为ICL设计更好的演示格式。
- Pengfei Liu: Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.
5.2.1 指令格式 Instruction Formatting
除了精心设计的演示示例外,准确描述任务的良好指令也有助于推理性能。然而,与传统数据集中常见的演示示例不同,任务指令在很大程度上依赖于人工书写的句子。Honovich等人(2022)发现,给定几个演示示例,LLM可以生成任务指令。根据LLM的生成能力,周等人(2022c)提出了用于指令自动生成和选择的自动提示工程师。为了进一步提高自动生成指令的质量,Wang等人(2022b)提出使用LLM来引导自己的生成。现有的工作在自动生成指令方面取得了良好的效果,这为未来将人类反馈与自动生成指令相结合的研究提供了机会。
- Instruction Induction: From Few Examples to Natural Language Task Descriptions
- Large language models are human-level prompt engineers
- Self-Instruct: Aligning Language Model with Self Generated Instructions
5.2.2 推理步骤格式 Reasoning Steps Formating
Wei等人(2022c)在输入和输出之间添加了中间推理步骤,以构建演示,称为思想链(CoT)。使用CoT,LLM预测推理步骤和最终答案。CoT提示可以通过将输入输出映射分解为许多中间步骤来学习复杂的推理。关于CoT提示策略的研究有很多(Qiao et al.,2022),包括提示设计和过程优化。在本文中,我们主要关注CoT的设计策略。
- Chain of thought prompting elicits reasoning in large language models
- Reasoning with language model prompting: A survey
与示范选择类似,CoT设计也考虑了CoT的选择。与Wei等人(2022c)手动编写CoT不同,AutoCT(Zhang等人,2022b)使用LLM和Let’s think逐步生成CoT。此外,Fu等人(2022)提出了一种基于复杂性的演示选择方法。他们选择了具有更多推理步骤的演示来进行CoT提示。
- Automatic chain of thought prompting in large language models.
- Complexity-based prompting for multi-step reasoning.
由于输入输出映射被分解为逐步推理,一些研究人员将多阶段ICL应用于CoT提示,并为每个步骤设计CoT演示。多阶段ICL在每个推理步骤中使用不同的演示来查询LLM。Self Ask(Press et al.,2022)允许LLM为输入生成后续问题,并问自己这些问题。然后,问题和中间答案将被添加到CoT中。iCAP(Wang et al.,2022a)提出了一种上下文感知提示器,该提示器可以动态调整每个推理步骤的上下文。最少到最多提示(Zhou et al.,2022a)是一个两阶段的ICL,包括问题减少和子问题解决。第一阶段将复杂的问题分解为子问题;在第二阶段,LLM依次回答子问题,之前回答的问题和生成的答案将被添加到上下文中。
- Ofir Press 2022: Measuring and Narrowing the Compositionality Gap in Language Models
- Boshi Wang 2022a: Iteratively prompt pre-trained language models for chain of thought.
- Denny Zhou 2022a: Least-to-most prompting enables complex reasoning in large language models
Xu等人(2023b)将特定任务上的小LMs作为插件进行微调,生成伪推理步骤。给定一个输入输出对(xi, yi), SuperICL通过连接(xi, y 'i, ci, yi),将输入xi的小lm的预测y 'i和置信度ci 作为推理步骤。
-Canwen Xu: 2023b: Small models are valuable plug-ins for large language models.
要点:
(1)演示选择策略提高了 ICL 性能,但大多数都是实例级。由于 ICL 主要在少样本设置下进行评估,因此语料库级别的选择策略更为重要但尚未得到充分探索。
(2) LLM的输出分数或概率分布在实例选择中起着重要作用。
(3) 对于 k 个演示,排列的搜索空间大小为 k!.如何有效地找到最佳顺序或如何更好地逼近最优排名也是一个具有挑战性的问题。
(4) 添加思维链可以有效地将复杂的推理任务分解为中间推理步骤。在推理过程中,应用多阶段演示设计策略来更好地生成 CoTs。如何提高llm的CoT提示能力也值得探索。
(5)除了人工编写的演示外,llm的生成性质还可以用于演示设计。LLM 可以生成指令、演示、探测集、思维链等。通过使用 LLM 生成的演示,ICL 可以在很大程度上摆脱人类对编写模板的努力。
6. Scoring Function
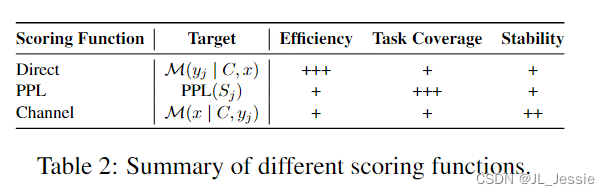
评分函数决定我们如何将语言模型的预测转换为对特定答案可能性的估计。直接估计方法(Direct)采用候选答案的条件概率,可以用语言模型词汇表中的标记表示(Brown et al., 2020)。选择概率较高的答案作为最终答案。然而,该方法对模板设计提出了一些限制,例如,答案标记应该放在输入序列的末尾。Perplexity (PPL) 是另一种常用的度量,它计算整个输入序列 Sj = {C, s(x, yj , I)} 的句子困惑度由演示示例 C、输入查询 x 和候选标签 yj 的标记组成。由于 PPL 评估整个句子的概率,它消除了标记位置的限制,但需要额外的计算时间。请注意,在机器翻译等生成任务中,ICL 通过解码具有最高句子概率的标记以及波束搜索或 Top-p 和 Top-k (Holtzman et al., 2020) 采样算法等促进多样性的策略来预测答案。
- The Curious Case of Neural Text Degeneration
不同于以往在给定输入上下文的情况下估计标签概率的方法,Min等人(2022a)提出利用信道模型(Channel)以相反的方向计算条件概率,即估计给定标签的输入查询的可能性。通过这种方式,语言模型需要为输入中的每个标记生成,从而提高不平衡训练数据机制下的性能。我们在表 2 中总结了所有三个评分函数。由于 ICL 对演示很敏感(有关更多详细信息,请参见第 5 节),因此通过减去具有空输入的模型相关先验来对获得的分数进行归一化对于提高稳定性和整体性能也很有效(Zhao et al., 2021)。
另一个方向是将上下文长度约束之外的信息纳入以校准分数。结构化提示 (Hao et al., 2022b) 提出用特殊的位置嵌入分别对演示示例进行编码,然后使用重新缩放的注意力机制提供给测试示例。kNN Prompting (Xu et al., 2023a) 首先使用训练数据查询 LLM 以进行分布式表示,然后通过简单地将最近邻与存储的锚表示关闭表示来预测测试实例。
- Structured Prompting: Scaling In-Context Learning to 1,000 Examples
- k nn prompting: Learning beyond the context with nearest neighbor inference.
要点:
(1)我们在表2中总结了三种广泛使用的评分函数的特征。尽管直接采用候选答案的条件概率是有效的,但这种方法仍然对模板设计造成了一些限制。困惑也是一个简单而广泛的评分函数。该方法具有通用性,包括分类任务和生成任务。然而,这两种方法仍然对演示表面敏感,而Channel是一种补救措施,尤其适用于不平衡的数据制度。
(2) 现有的评分函数都直接根据LLM的条件概率来计算分数。通过评分策略校准偏差或减轻敏感性的研究有限。例如,一些研究添加了额外的校准参数来调整模型预测(赵等人,2021)。
7. Analysis
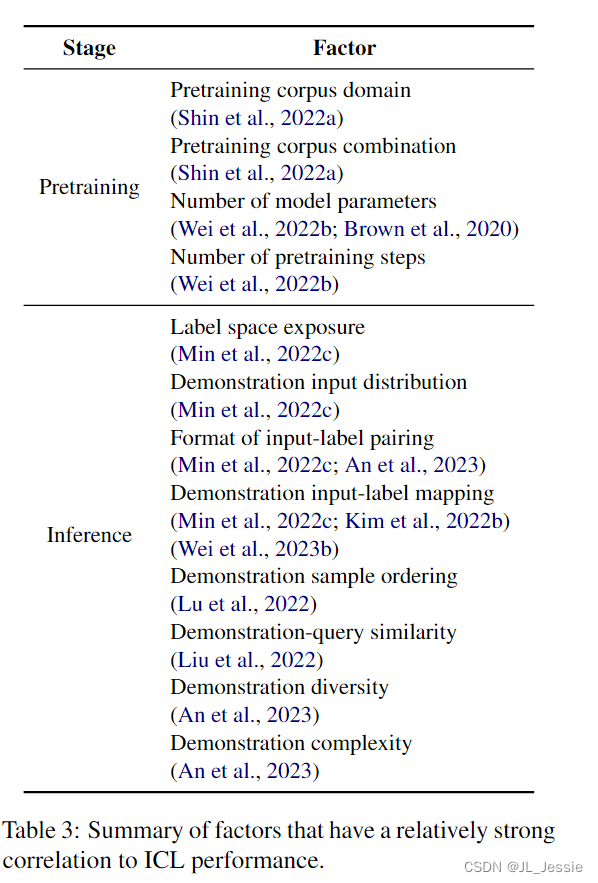
为了理解ICL,许多分析研究试图调查哪些因素可能影响性能,并旨在找出ICL工作的原因。我们在表3中总结了与ICL性能具有相对较强相关性的因素,以便于参考。
7.1 What Influences ICL Performance
预训练阶段: 我们首先介绍LLM预训练阶段的影响因素。Shin等人(2022a)研究了预训练语料库的影响。他们发现,领域来源比语料库大小更重要。将多个语料库放在一起可能会产生突发ICL能力,对与下游任务相关的语料库进行预训练并不总是能提高ICL性能,困惑度较低的模型在ICL场景中也不总是表现得更好。Wei等人(2022b)研究了许多大型模型在多个任务上的涌现能力。他们认为,当预训练的模型达到大规模的预训练步骤或模型参数时,它会突然获得一些突发的ICL能力。Brown等人(2020)还表明,随着LLM参数从1亿增加到1750亿,ICL能力也在增长。
- On the effect of pretraining corpora on in-context learning by a large-scale language model.
- Language models are few-shot learners.
**推理阶段:**在推理阶段,演示样本的特性也会影响ICL的性能。Min等人(2022c)研究了演示样本的影响来自四个方面:输入标签配对格式、标签空间、输入分布和输入标签映射。他们证明了所有的输入标签配对格式、标签空间的暴露和输入分布对ICL性能有很大贡献。与直觉相反,输入标签映射对ICL来说无关紧要。就输入标签映射的影响而言,Kim等人(2022b)得出了相反的结论,即正确的输入标签映射确实会影响ICL的性能,这取决于特定的实验设置。Wei等人(2023b)进一步发现,当一个模型足够大时,它将表现出学习输入标签映射的紧急能力,即使标签被翻转或语义无关。从组成概括的角度来看,An等人(2023)验证了ICL演示应该是多样的、简单的,并且在结构方面与测试示例相似。Lu等人(2022)指出,示范样本顺序也是一个重要因素。此外,刘等人(2022)发现,嵌入距离查询样本更近的演示样本通常比嵌入距离更远的演示样本带来更好的性能。
- Sewon Min : Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
- Junyeob Kim: Groundtruth labels matter: A deeper look into inputlabel demonstrations.
- Jerry W Wei: Larger language models do in-context learning differently.
- An 2023: How do in-context examples affect compositional generalization?
- Lu 2022: Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity.
- Liu 2022: What makes good in-context examples for GPT-3?
7.2 Understanding why ICL Works
训练数据的分布: Chan等人(2022)对预训练数据的研究表明,ICL能力是由数据分布属性驱动的。他们发现,当训练数据具有出现在集群中的示例并且有足够的稀有类时,ICL 能力就会出现。谢等人。 (2022) 将 ICL 解释为隐式贝叶斯推理,并构建了一个合成数据集来证明当预训练分布遵循隐马尔可夫模型的混合时,ICL 能力会出现。
- Chan 2022 : Data distributional properties drive emergent in-context learning in transformers
- Sang Michael Xie 2022: An explanation of in-context learning as implicit bayesian inference
学习机制: 通过学习线性函数,Garg等人(2022)证明了Transformers可以根据演示样本编码有效的学习算法来学习看不见的线性函数。他们还发现,ICL模型中编码的学习算法可以实现与最小二乘估计器相当的误差。李等人(2023g)将ICL抽象为一个算法学习问题,并表明Transformers可以通过隐式经验风险最小化来实现适当的函数类。潘等人(2023)将ICL能力解耦为任务识别能力和任务学习能力,并进一步展示了它们如何利用演示。从信息论的角度来看,Hahn和Goyal(2023)在语言学动机的假设下展示了ICL的误差界,以解释下一个表征预测如何带来ICL能力。Si等人(2023)发现,大型语言模型表现出先前的特征偏差,并展示了一种使用干预来避免ICL中意外特征的方法。
- Shivam Garg: 2022: What can transformers learn in-context? A case study of simple function classes.
- Yingcong Li 2023g: Transformers as algorithms: Generalization and implicit model selection in in-context learning.
- Jane Pan 2023: What in-context learning “learns” in-context: Disentangling task recognition and task learning.
- Michael Hahn/ Navin Goyal: A Theory of Emergent In-Context Learning as Implicit Structure Induction
- Si 2023: Measuring inductive biases of in-context learning with underspecified demonstrations.
另一项工作试图建立 ICL 和梯度下降之间的联系。将线性回归作为起点,Akyürek 等人 (2022) 发现基于 Transformer 的上下文学习器可以隐式实现标准微调算法,von Oswald 等人 (2022) 表明,具有手工构建参数和梯度下降学习的模型的线性仅注意力 Transformer 高度相关。基于 softmax 回归,Li 等人 (2023e) 发现仅自注意力的 Transformer 与梯度下降学习的模型表现出相似性。戴等人 (2022) 找出 Transformer attention 和梯度下降之间的对偶形式,并进一步提出将 ICL 理解为隐式微调。此外,他们比较了基于GPT的ICL和对实际任务的显式微调,发现ICL的行为确实类似于从多个角度进行的调优。
- Ajyurek 2022: What learning algorithm is in-context learning? Investigations with linear models
- von Oswald 2022: . Transformers learn in-context by gradient descent.
- Li 2023e: The Closeness of In-Context Learning and Weight Shifting for Softmax Regression
- Dai 2022: Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta Optimizers
功能组件: 专注于特定的功能模块,Olsson等人(2022)发现transformer 中存在一些感应头,它们复制之前的模式来完成下一个令牌。进一步,他们将感应头的功能扩展到更抽象的模式匹配和补全,这可能实现ICL。Wang et al. (2023b)对Transformers中的信息流进行了研究,发现在ICL过程中,示范标签词作为锚点,聚集和分发关键信息,用于最终的预测。
- Olsson 2022: In-Context learning and INduction heads
- Wang 2023b: Label words are anchors: An information flow perspective for understanding in-context learning.
要点:
(1)了解和考虑ICL的工作方式可以帮助我们提高ICL的性能,表3列出了与ICL性能密切相关的因素。
(2) 尽管一些分析研究已经为解释ICL迈出了初步的一步,但它们大多局限于简单的任务和小模型。对大量任务和大型模型进行扩展分析可能是下一步需要考虑的问题。此外,在现有的工作中,用梯度下降解释ICL似乎是一个合理、普遍和有前景的未来研究方向。如果我们在ICL和基于梯度下降的学习之间建立明确的联系,我们可以借鉴传统深度学习的历史来改进ICL。
8. 验证和资源 Evaluation and Resources
8.1 传统任务 Traditional Tasks
作为一种通用的学习范式,ICL可以在各种传统数据集和基准上进行检查,例如SuperGLUE(Wang et al.,2019)、SQuAD(Rajpurkar et al.,2018)。Brown等人在SuperGLUE上用32个随机采样的例子实现ICL。(2020)发现,GPT3可以在COPA和ReCoRD上实现与先进状态(SOTA)微调性能相当的结果,但在大多数NLU任务上仍然落后于微调。Hao等人(2022b)显示了扩大示范示例数量的潜力。然而,缩放带来的改进是非常有限的。目前,与微调相比,ICL在传统的NLP任务上仍有一些空间。
8.2 新的有挑战性的任务 New Challenging Tasks
在具有上下文学习能力的大型语言模型时代,研究人员更感兴趣的是在没有下游任务微调的情况下评估大型语言模型的内在能力(Bommasani et al.,2021)。
为了探索LLM在各种任务上的能力限制,Srivastava等人(2022)提出了BIG Bench(Srivastawa等人,2022),这是一个涵盖广泛任务的大型基准,包括语言学、化学、生物学、社会行为等。通过ICL,在65%的BIG Bench任务中,最佳模型已经超过了平均报告的人工评分结果(Suzgun等人,2022)。为了进一步探索当前语言模型实际上无法解决的任务,Suzgun等人(2022)提出了一个更具挑战性的ICL基准,即BIG Bench Hard(BBH)。BBH包括23个未解决的任务,通过选择最先进的模型性能远低于人类性能的具有挑战性的任务来构建。此外,研究人员正在搜索逆缩放任务,1也就是说,当放大模型大小时,模型性能会降低的任务。这些任务也突出了ICL当前范式的潜在问题。为了进一步探索模型的泛化能力,Iyer等人(2022)提出了OPT-IML Bench,由来自8个现有基准的2000个NLP任务组成,特别是ICL在保留类别上的基准。
具体而言,一系列研究集中在探索ICL的推理能力。Saparov和He(2022)从一阶逻辑中表示的合成世界模型中生成了一个例子,并将ICL生成解析为符号证明以进行形式分析。他们发现LLM可以通过ICL做出正确的个人推断步骤。施等人(2022)构建了MGSM基准来评估LLM在多语言环境中的思维链推理能力,发现LLM表现出跨多种语言的复杂推理。为了进一步探索LLM更复杂的规划和推理能力,Valmickam等人(2022)提供了多个测试案例,用于评估行动和变化的各种推理能力,其中现有的LLM ICL方法表现出较差的性能。
8.3 开源工具
注意到ICL方法通常以不同的方式实现,并使用不同的LLM和任务进行评估,Wu等人(2023)开发了OpenICL,这是一个开源工具包,能够实现灵活统一的ICL评估。凭借其适应性强的体系结构,OpenICL促进了不同组件的组合,并提供了最先进的检索和推理技术,以加速ICL与高级研究的集成。
- Openicl: An open-source framework for in-context learning
要点:
(1) 由于ICL对演示示例数量的限制,传统的评估任务必须适应较少的镜头设置;否则,传统的基准无法直接评估LLM的ICL能力
(2)由于ICL是一种在许多方面不同于传统学习范式的新范式,因此对ICL的评价提出了新的挑战和机遇。面对挑战,现有评估方法的结果是不稳定的,尤其是对演示示例和说明敏感。Chen等人(2022b)观察到,现有的准确性评估低估了ICL对指令扰动的敏感性。进行一致的ICL评估仍然是一个悬而未决的问题,而OpenICL(Wu et al.,2023)代表了应对这一挑战的一次有价值的初步尝试。对于评估的机会,由于ICL只需要几个实例进行演示,它降低了评估数据构建的成本。
- On the relation between sensitivity and accuracy in in-context learning.
- Meta-learning via language model in-context tuning.
9 文本以外的上下文学习 In-context learning beyond Text
ICL在NLP中的巨大成功激发了研究人员在不同模式下探索其潜力,包括视觉、视觉+语言和语音任务
9.1 视觉上下文学习 visual In-context learning
9.2 多模态上下文学习 Multi-modal in-context learning
9.3 语音上下文学习 Speech in-context learning
总结:
(1)最近的研究探索了自然语言之外的语境学习,取得了有希望的结果。正确格式化的数据(例如,用于视觉语言任务的交错图像-文本数据集)和架构设计是激活上下文学习潜力的关键因素。在更复杂的结构空间(如图形数据)中探索它是具有挑战性和前景的(Huang et al.,2023a)。
(2) 语境中的文本学习示范设计和选择的发现不能简单地转移到其他模式。需要进行特定领域的调查,以充分利用各种模式的情境学习的潜力。
10 应用
CL在传统的NLP任务和方法上表现出优异的性能(Kim等人,2022a;Min等人,2022b),如机器翻译(Zhu等人,2023b;Sia和Duh,2023)、信息提取(Wan等人,2020;He等人,2021)和文本到SQL(Pourreza和Rafiei,2023。特别是,通过明确指导推理过程的演示,ICL在需要复杂推理的任务上表现出显著的效果(Wei et al.,2022c;李等人,2023b;周等人,2022b)和组合泛化(Zhou et al.,2021)
此外,ICL为元学习和指令调整等流行方法提供了潜力。Chen等人(2022d)将ICL应用于元学习,适应具有冻结模型参数的新任务,从而解决了复杂的嵌套优化问题。(Ye et al.,2023b)通过将无正文学习应用于教学学习,增强了预训练模型和教学网络模型的零样本任务泛化性能。具体来说,我们探讨了ICL的几个新兴和流行的应用,在下面的段落中展示了它们的潜力。
数据工程: ICL已经显示出在数据工程中广泛应用的潜力。得益于强大的ICL能力,使用GPT-3的标签比使用人类的标签进行数据注释的成本低50%至96%。将GPT-3的伪标签与人类标签相结合,可以以较小的成本获得更好的性能(Wang等人,2021)。在更复杂的场景中,如知识图构建,Khorashadizadeh等人(2023)已经证明,ICL有潜力显著提高知识图的自动构建和完成的技术水平,从而以最小的工程工作量降低人工成本。因此,在各种数据工程应用程序中利用ICL的功能可以产生显著的好处。与人工注释(例如,众包)或嘈杂的自动注释(例如远程监督)相比,ICL以低成本生成相对高质量的数据。然而,如何使用ICL进行数据注释仍然是一个悬而未决的问题。例如,丁等人(2022)进行了全面分析,发现基于生成的方法在使用GPT-3时比通过ICL注释未标记的数据更具成本效益。
模型增强 ICL的上下文灵活性显示了增强检索增强方法的巨大潜力。通过保持LM架构不变并为输入准备基础文档,在上下文中,RALMRam等人(2023)有效地利用了现成的通用检索器,从而在各种模型大小和不同的语料库中获得了显著的LM增益。此外,用于检索的ICL也显示出提高安全性的潜力。除了效率和灵活性外,ICL还显示出安全性潜力(Panda等人,2023),(Meade等人,2024)使用ICL进行检索演示,以引导模型朝着更安全的世代发展,减少模型中的偏差和毒性。
知识更新 LLM可能包含过时或不正确的知识,但ICL展示了有效编辑和更新这些信息的潜力。在一项初步试验中,Si等人(2022)发现,当提供反事实示例时,GPT-3 85%的时间更新了其答案,较大的模型在上下文知识更新方面表现更好。然而,这种方法可能会影响LLM中的其他正确知识。与微调模型的知识编辑相比(De Cao et al.,2021),ICL已被证明对轻量级模型编辑有效。Si等人(2022)探索了通过上下文演示编辑LLM记忆知识的可能性,发现更大的模型规模和演示示例的组合提高了基于ICL的知识编辑成功率。在一项综合研究中,郑等人(2023)调查了ICL编辑事实知识的策略,发现与基于梯度的方法相比,精心设计的演示能够实现有竞争力的成功率,副作用显著减少。这突出了ICL在知识编辑方面的潜力。
11 挑战和未来研究方向
在本节中,我们回顾了一些现有的挑战,并为ICL的未来研究提出了可能的方向。
11.1. 新的预训练策略 New pretraining Strategies
正如Shin等人(2022b)所研究的那样,语言模型目标并不等于ICL能力。研究人员提出,通过推理前的中间调整来弥合预训练目标和ICL之间的差距(第4节),这表明了有希望的性能改进。更进一步,为ICL量身定制的预训练目标和指标有可能提高具有卓越ICL能力的LLM。
-
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
11.2. 上下文学习能力的蒸馏 ICL Ability Distillation
先前的研究表明,当计算规模和参数超过一定阈值时,推理任务的上下文学习就会出现(Wei et al.,2022b)。将ICL能力转移到较小的模型可以极大地促进模型部署。Magister等人(2022)表明,可以将推理能力提取到T5-XXL等小型语言模型中。蒸馏是通过对大型教师模型生成的思维链数据(Wei et al.,2022c)上的小模型进行微调来实现的。尽管实现了有希望的性能,但改进可能取决于任务。进一步研究通过向更大的LLM学习来提高推理能力可能是一个有趣的方向。
11.3. 上下文学习鲁棒性 ICL Roubstness
先前的研究表明,ICL性能极不稳定,从随机猜测到SOTA,并且可能对许多因素敏感,包括演示排列、演示格式等(赵等人,2021;Lu等人,2022)。ICL的稳健性是一个关键但具有挑战性的问题。然而,现有的大多数方法都陷入了准确性和稳健性的困境(Chen et al.,2022c),甚至以牺牲推理效率为代价。为了有效地提高ICL的鲁棒性,我们需要对ICL的工作机制进行更深入的分析。我们认为,从更理论的角度而不是实证的角度来分析ICL的稳健性,可以突出未来对更稳健ICL的研究
11.4. 上下文学习的效率和规模 ICL Efficiency and Scalability
ICL需要在这种背景下准备大量的示威活动。然而,它提出了两个挑战:(1)演示的数量受到LM的最大输入长度的限制,与微调(可扩展性)相比,这一长度要少得多;(2) 随着演示次数的增加,由于注意力机制(效率)的二次复杂性,计算成本变得更高。§5中先前的工作侧重于探索如何使用有限数量的演示来实现更好的ICL性能,并提出了几种演示设计策略。将ICL扩展到更多的演示并提高其效率仍然是一项具有挑战性的任务。最近,已经提出了一些工作来解决ICL的可扩展性和效率问题。努力通过结构化提示(Hao et al.,2022b)、演示整合(Khalifa et al.,2021)、动态提示(Zhou et al.,2020)和迭代前向调整(Yang et al.,2022)来优化提示策略。此外,李等人(2023d)提出了具有更长上下文长度和增强的远程语言建模能力的EVaLM。此模型级别的改进旨在提高ICL的可扩展性和效率。随着LMs的不断扩大,探索有效利用ICL中大量演示的方法仍然是一个正在进行的研究领域。
12 结论
在本文中,我们调查了现有的ICL文献,并对先进的ICL技术进行了广泛的综述,包括训练策略、演示设计策略、评估数据集和资源,以及相关的分析研究。此外,我们强调了未来研究的关键挑战和潜在方向。据我们所知,这是关于ICL的第一次调查。我们希望这项调查能够突出ICL目前的研究现状,并为未来在这一有前景的范式上的工作提供线索。