1、ES原理
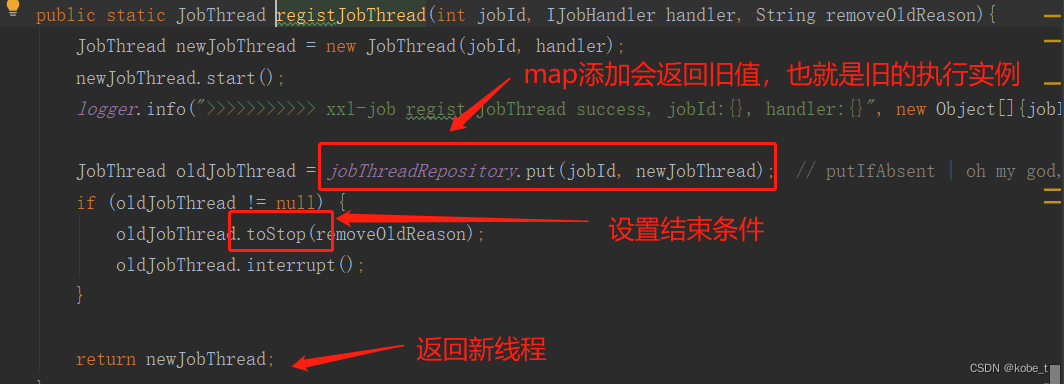
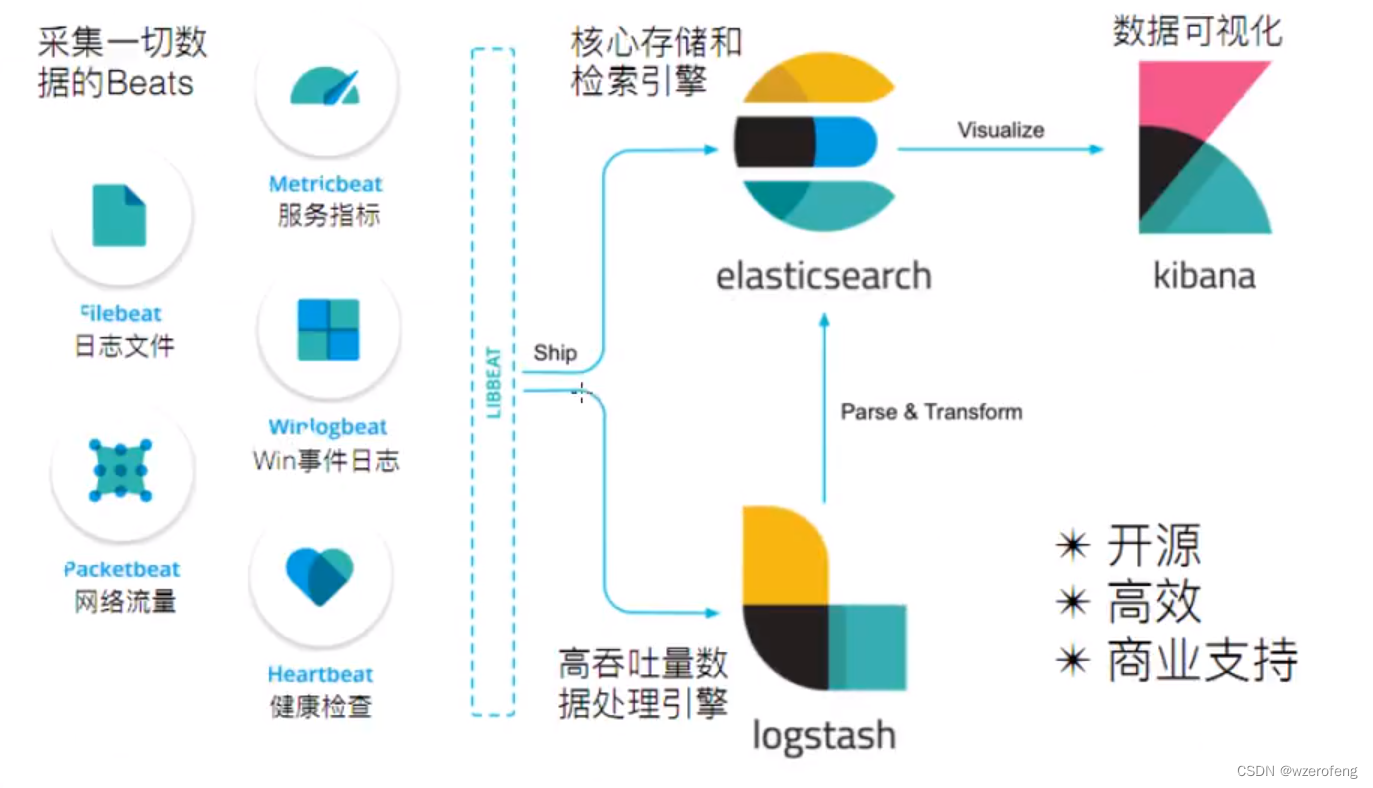
原理 使⽤filebeat来上传⽇志数据,logstash进⾏⽇志收集与处理,elasticsearch作为⽇志存储与搜索引擎,最后使⽤kibana展现⽇志的可视化输出。所以不难发现,⽇志解析主要还 是logstash做的事情

从上图中可以看到,logstash主要包含三⼤模块:
1、INPUTS: 收集所有数据源的⽇志数据([源有file、redis、beats等,filebeat就是使⽤了beats源*);
2、FILTERS: 负责数据处理与转换、解析、整理⽇志数据(常⽤:grok、mutate、drop、clone、geoip)
3、OUTPUTS: 将解析的⽇志数据输出⾄存储器([elasticseach、file、syslog等);
通过配置Logstash的管道(pipeline),你可以定义数据的收集、处理和输出过程。每个管道由输入插件、过滤器插件和输出插件组成,它们一起协作来实现特定的数据流转
filters常用的过滤器插件如下:
-
grok 过滤器: 场景:解析包含时间戳、日志级别和消息的日志行。
rubyCopy codegrok {match => {"message" => "\[%{TIMESTAMP_ISO8601:time}\] \[%{WORD:level}\] %{GREEDYDATA:msg}"}} -
mutate 过滤器: 场景:清理字段,将 IP 地址字段重命名为 "client_ip"。
rubyCopy codemutate {rename => { "ip" => "client_ip" }} -
date 过滤器: 场景:将时间戳字段转换为可操作的日期类型。
rubyCopy codedate {match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]target => "log_date"} -
json 过滤器: 场景:解析包含嵌套 JSON 数据的日志消息。
rubyCopy codejson {source => "message"target => "parsed_json"} -
kv 过滤器: 场景:解析 HTTP 查询字符串中的参数。
rubyCopy codekv {field_split => "&"value_split => "="source => "query_string"} -
xml 过滤器: 场景:解析包含 XML 数据的日志消息。
rubyCopy codexml {source => "message"store_xml => falsexpath => ["//user/name/text()", "username","//user/age/text()", "user_age"]} -
translate 过滤器: 场景:将日志中的状态码映射为更可读的状态描述。
rubyCopy codetranslate {field => "status_code"dictionary => ["200", "OK","404", "Not Found","500", "Internal Server Error"]} -
useragent 过滤器: 场景:解析用户代理字符串,提取浏览器和操作系统信息。
rubyCopy codeuseragent {source => "user_agent"target => "user_agent_info"} -
geoip 过滤器: 场景:将 IP 地址解析为地理位置信息。
rubyCopy codegeoip {source => "client_ip"target => "geoip"} -
multiline 过滤器: 场景:合并多行堆栈跟踪日志成单个事件。
rubyCopy codemultiline {pattern => "^\s"negate => truewhat => "previous"}
2.Logstash性能优化主要体现在以下几个方面:
1.多pipeline配置
多pipeline配置。可以将不同的输入分割到不同的pipeline,每个pipeline有独立的过滤器和输出,这可以提高处理效率。pipeline之间的数据交互可以通过队列实现。
ruby# 管道1:接收日志输入input { stdin { } } filter { grok { } }output { stdout { } }# 管道2:从Kafka读取数据input { kafka { } }filter { json { } } output { elasticsearch { } }
2.Grok过滤器配置
rubyfilter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" }add_field => { "timestamp" => "%{DATE:timestamp}" }}}
3.Elasticsearch输出配置
ruby output {elasticsearch { hosts => ["http://localhost:9200"]index => "logstash-%{+YYYY.MM.dd}"}}
4.Redis队列配置
rubyoutput {redis { host => "127.0.0.1"port => 6379db => 0key => "logstash" }}
5.batching编辑模式配置
rubyinput {file {path => "/var/log/messages"start_position => "beginning" sincedb_path => "/dev/null"codec => "json"mode => "batch" # 配置batching模式batch_size => 1000 # 每1000条记录批量读取}}
6.调整JVM内存配置在 jvm.options文件中配置,例如:
-Xms2g-Xmx2g
7.并行处理配置 在 logstash.yml中配置:
yml
pipeline.workers: 2 #配置工作线程数为2
pipeline.output.workers: 2 #输出线程也配置为2
logstash 配置文件
logstash 配置文件配置
vim logstash.conf
input {
kafka {
bootstrap_servers => ["192.168.190.159:9092"]
topics_pattern => ["hwb\.test|ywyth-sc|zj_test"]
consumer_threads => 5
codec => json
auto_offset_reset => latest
group_id => "hwb"
}
}filter {
ruby {
code => "event.timestamp.time.localtime"
}
mutate {
remove_field => ["beat"]
}
mutate {
split => ["message"," "]
add_field => { "level" => "%{[message][3]}" }
}
mutate {
add_field => {
"index_name" => "hwb.test,%{[ywyth-sc]}"
}
}
grok {
match => {"message" => "\[(?<time>\d+-\d+-\d+\s\d+:\d+:\d+)\] \[(?<level>\w+)\] (?<thread>[\w|-]+) (?<class>[\w|\.]+) (?<lineNum>\d+):(?<msg>.+)"
}
}
}output {
elasticsearch {
hosts => ["192.168.190.161:9200"]
index => "%{[fields][log_topic]}"
codec => "json"
}
}
启动logstash
nohup ./logstash -f ../config/logstash.conf &