文章目录
- 前言
- 一、数据准备
- 1.1 数据集介绍
- 1.2 数据集文件结构
- 二、项目实战
- 2.1 数据标签划分
- 2.2 数据预处理
- 2.3 构建模型
- 2.4 开始训练
- 2.5 结果可视化
- 三、数据集个体预测
前言
SqueezeNet是一种轻量且高效的CNN模型,它参数比AlexNet少50倍,但模型性能(accuracy)与AlexNet接近。顾名思义,Squeeze的中文意思是压缩和挤压的意思,所以我们通过算法的名字就可以猜想到,该算法一定是通过压缩模型来降低模型参数量的。当然任何算法的改进都是在原先的基础上提升精度或者降低模型参数,因此该算法的主要目的就是在于降低模型参数量的同时保持模型精度。
我的环境:
- 基础环境:python3.7
- 编译器:pycharm
- 深度学习框架:pytorch
- 数据集代码获取:链接(提取码:2357 )
一、数据准备
本案例使用的数据集是眼疾识别数据集iChallenge-PM。
1.1 数据集介绍
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。
- training.zip:包含训练中的图片和标签
- validation.zip:包含验证集的图片
- valid_gt.zip:包含验证集的标签
该数据集是从AI Studio平台中下载的,具体信息如下:

1.2 数据集文件结构
数据集中共有三个压缩文件,分别是:
- training.zip
├── PALM-Training400
│ ├── PALM-Training400.zip
│ │ ├── H0002.jpg
│ │ └── ...
│ ├── PALM-Training400-Annotation-D&F.zip
│ │ └── ...
│ └── PALM-Training400-Annotation-Lession.zip└── ...
- valid_gt.zip:标记的位置 里面的PM_Lable_and_Fovea_Location.xlsx就是标记文件
├── PALM-Validation-GT
│ ├── Lession_Masks
│ │ └── ...
│ ├── Disc_Masks
│ │ └── ...
│ └── PM_Lable_and_Fovea_Location.xlsx- validation.zip:测试数据集
├── PALM-Validation
│ ├── V0001.jpg
│ ├── V0002.jpg
│ └── ...二、项目实战
项目结构如下:
2.1 数据标签划分
该眼疾数据集格式有点复杂,这里我对数据集进行了自己的处理,将训练集和验证集写入txt文本里面,分别对应它的图片路径和标签。
import os
import pandas as pd
# 将训练集划分标签
train_dataset = r"F:\SqueezeNet\data\PALM-Training400\PALM-Training400"
train_list = []
label_list = []train_filenames = os.listdir(train_dataset)for name in train_filenames:filepath = os.path.join(train_dataset, name)train_list.append(filepath)if name[0] == 'N' or name[0] == 'H':label = 0label_list.append(label)elif name[0] == 'P':label = 1label_list.append(label)else:raise('Error dataset!')with open('F:/SqueezeNet/train.txt', 'w', encoding='UTF-8') as f:i = 0for train_img in train_list:f.write(str(train_img) + ' ' +str(label_list[i]))i += 1f.write('\n')
# 将验证集划分标签
valid_dataset = r"F:\SqueezeNet\data\PALM-Validation400"
valid_filenames = os.listdir(valid_dataset)
valid_label = r"F:\SqueezeNet\data\PALM-Validation-GT\PM_Label_and_Fovea_Location.xlsx"
data = pd.read_excel(valid_label)
valid_data = data[['imgName', 'Label']].values.tolist()with open('F:/SqueezeNet/valid.txt', 'w', encoding='UTF-8') as f:for valid_img in valid_data:f.write(str(valid_dataset) + '/' + valid_img[0] + ' ' + str(valid_img[1]))f.write('\n')
2.2 数据预处理
这里采用到的数据预处理,主要有调整图像大小、随机翻转、归一化等。
import os.path
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import transformstransform_BZ = transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5]
)class LoadData(Dataset):def __init__(self, txt_path, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flagself.train_tf = transforms.Compose([transforms.Resize(224), # 调整图像大小为224x224transforms.RandomHorizontalFlip(), # 随机左右翻转图像transforms.RandomVerticalFlip(), # 随机上下翻转图像transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transform_BZ # 执行某些复杂变换操作])self.val_tf = transforms.Compose([transforms.Resize(224), # 调整图像大小为224x224transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transform_BZ # 执行某些复杂变换操作])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))return imgs_infodef padding_black(self, img):w, h = img.sizescale = 224. / max(w, h)img_fg = img.resize([int(x) for x in [w * scale, h * scale]])size_fg = img_fg.sizesize_bg = 224img_bg = Image.new("RGB", (size_bg, size_bg))img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,(size_bg - size_fg[1]) // 2))img = img_bgreturn imgdef __getitem__(self, index):img_path, label = self.imgs_info[index]img_path = os.path.join('', img_path)img = Image.open(img_path)img = img.convert("RGB")img = self.padding_black(img)if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)
2.3 构建模型
import torch
import torch.nn as nn
import torch.nn.init as initclass Fire(nn.Module):def __init__(self, inplanes, squeeze_planes,expand1x1_planes, expand3x3_planes):super(Fire, self).__init__()self.inplanes = inplanesself.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)self.squeeze_activation = nn.ReLU(inplace=True)self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,kernel_size=1)self.expand1x1_activation = nn.ReLU(inplace=True)self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,kernel_size=3, padding=1)self.expand3x3_activation = nn.ReLU(inplace=True)def forward(self, x):x = self.squeeze_activation(self.squeeze(x))return torch.cat([self.expand1x1_activation(self.expand1x1(x)),self.expand3x3_activation(self.expand3x3(x))], 1)class SqueezeNet(nn.Module):def __init__(self, version='1_0', num_classes=1000):super(SqueezeNet, self).__init__()self.num_classes = num_classesif version == '1_0':self.features = nn.Sequential(nn.Conv2d(3, 96, kernel_size=7, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(96, 16, 64, 64),Fire(128, 16, 64, 64),Fire(128, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 32, 128, 128),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(512, 64, 256, 256),)elif version == '1_1':self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(64, 16, 64, 64),Fire(128, 16, 64, 64),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(128, 32, 128, 128),Fire(256, 32, 128, 128),nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),Fire(256, 48, 192, 192),Fire(384, 48, 192, 192),Fire(384, 64, 256, 256),Fire(512, 64, 256, 256),)else:# FIXME: Is this needed? SqueezeNet should only be called from the# FIXME: squeezenet1_x() functions# FIXME: This checking is not done for the other modelsraise ValueError("Unsupported SqueezeNet version {version}:""1_0 or 1_1 expected".format(version=version))# Final convolution is initialized differently from the restfinal_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)self.classifier = nn.Sequential(nn.Dropout(p=0.5),final_conv,nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)))for m in self.modules():if isinstance(m, nn.Conv2d):if m is final_conv:init.normal_(m.weight, mean=0.0, std=0.01)else:init.kaiming_uniform_(m.weight)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):x = self.features(x)x = self.classifier(x)return torch.flatten(x, 1)2.4 开始训练
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from model import SqueezeNet
import torchsummary
from dataloader import LoadData
import copydevice = "cuda:0" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = SqueezeNet(num_classes=2).to(device)
# print(model)
#print(torchsummary.summary(model, (3, 224, 224), 1))# 加载训练集和验证集
train_data = LoadData(r"F:\SqueezeNet\train.txt", True)
train_dl = torch.utils.data.DataLoader(train_data, batch_size=16, pin_memory=True,shuffle=True, num_workers=0)
test_data = LoadData(r"F:\SqueezeNet\valid.txt", True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=16, pin_memory=True,shuffle=True, num_workers=0)# 编写训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)print('num_batches:', num_batches)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss# 编写验证函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss# 开始训练epochs = 20train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标loss_function = nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 定义Adam优化器for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_function, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_function)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,epoch_test_acc * 100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
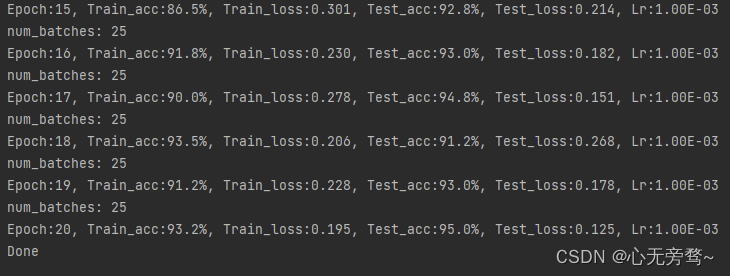
torch.save(best_model.state_dict(), PATH)print('Done')
2.5 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Test Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Test Loss')
plt.show()
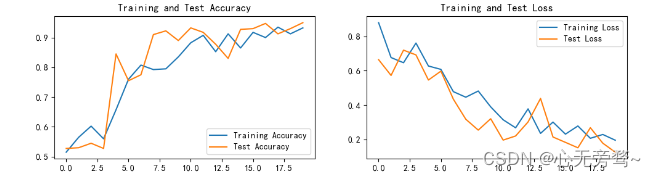
可视化结果如下:
可以自行调整学习率以及batch_size,这里我的超参数并没有调整。
三、数据集个体预测
import matplotlib.pyplot as plt
from PIL import Image
from torchvision.transforms import transforms
from model import SqueezeNet
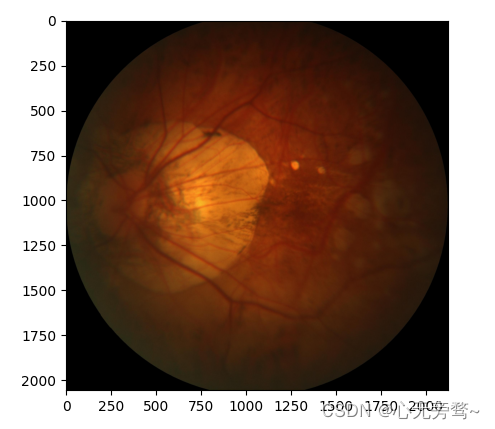
import torchdata_transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((224, 224)),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])img = Image.open("F:\SqueezeNet\data\PALM-Validation400\V0008.jpg")
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
name = ['非病理性近视', '病理性近视']
model_weight_path = r"F:\SqueezeNet\best_model.pth"
model = SqueezeNet(num_classes=2)
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():output = torch.squeeze(model(img))predict = torch.softmax(output, dim=0)# 获得最大可能性索引predict_cla = torch.argmax(predict).numpy()print('索引为', predict_cla)
print('预测结果为:{},置信度为: {}'.format(name[predict_cla], predict[predict_cla].item()))
plt.show()
索引为 1
预测结果为:病理性近视,置信度为: 0.9768268465995789
更详细的请看paddle版本的实现:深度学习实战基础案例——卷积神经网络(CNN)基于SqueezeNet的眼疾识别