文章目录
- 一. 参考博客or文献
- 二. Proprocess GLUE task data
- 2.1 下载GLUE的数据集
- 2.2 预处理GLUE的数据集
- 2.2.1 算法思路与整体代码以及运行结果图
- 2.2.2 完整代码与处理结果
- 三. 使用预处理好的数据集进行 finetune
- 3.1 将RoBERTa的模型下载到本地
- 3.2 微调任务之RTE(句子二分类任务)
一. 参考博客or文献
Finetuning RoBERTa on GLUE tasks
二. Proprocess GLUE task data
2.1 下载GLUE的数据集
GLUE数据集的下载链接: GLUE
import os
import sys
import shutil
import argparse
import tempfile
import urllib.request
import zipfileTASKS = ["CoLA", "SST", "MRPC", "QQP", "STS", "MNLI", "SNLI", "QNLI", "RTE", "WNLI", "diagnostic"]
TASK2PATH = {"CoLA":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FCoLA.zip?alt=media&token=46d5e637-3411-4188-bc44-5809b5bfb5f4',"SST":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSST-2.zip?alt=media&token=aabc5f6b-e466-44a2-b9b4-cf6337f84ac8',"MRPC":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2Fmrpc_dev_ids.tsv?alt=media&token=ec5c0836-31d5-48f4-b431-7480817f1adc',"QQP":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FQQP.zip?alt=media&token=700c6acf-160d-4d89-81d1-de4191d02cb5',"STS":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSTS-B.zip?alt=media&token=bddb94a7-8706-4e0d-a694-1109e12273b5',"MNLI":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FMNLI.zip?alt=media&token=50329ea1-e339-40e2-809c-10c40afff3ce',"SNLI":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSNLI.zip?alt=media&token=4afcfbb2-ff0c-4b2d-a09a-dbf07926f4df',"QNLI": 'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FQNLIv2.zip?alt=media&token=6fdcf570-0fc5-4631-8456-9505272d1601',"RTE":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FRTE.zip?alt=media&token=5efa7e85-a0bb-4f19-8ea2-9e1840f077fb',"WNLI":'https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FWNLI.zip?alt=media&token=068ad0a0-ded7-4bd7-99a5-5e00222e0faf',"diagnostic":'https://storage.googleapis.com/mtl-sentence-representations.appspot.com/tsvsWithoutLabels%2FAX.tsv?GoogleAccessId=firebase-adminsdk-0khhl@mtl-sentence-representations.iam.gserviceaccount.com&Expires=2498860800&Signature=DuQ2CSPt2Yfre0C%2BiISrVYrIFaZH1Lc7hBVZDD4ZyR7fZYOMNOUGpi8QxBmTNOrNPjR3z1cggo7WXFfrgECP6FBJSsURv8Ybrue8Ypt%2FTPxbuJ0Xc2FhDi%2BarnecCBFO77RSbfuz%2Bs95hRrYhTnByqu3U%2FYZPaj3tZt5QdfpH2IUROY8LiBXoXS46LE%2FgOQc%2FKN%2BA9SoscRDYsnxHfG0IjXGwHN%2Bf88q6hOmAxeNPx6moDulUF6XMUAaXCSFU%2BnRO2RDL9CapWxj%2BDl7syNyHhB7987hZ80B%2FwFkQ3MEs8auvt5XW1%2Bd4aCU7ytgM69r8JDCwibfhZxpaa4gd50QXQ%3D%3D'}MRPC_TRAIN = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt'
MRPC_TEST = 'https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt'def download_and_extract(task, data_dir):print("Downloading and extracting %s..." % task)data_file = "%s.zip" % taskurllib.request.urlretrieve(TASK2PATH[task], data_file)with zipfile.ZipFile(data_file) as zip_ref:zip_ref.extractall(data_dir)os.remove(data_file)print("\tCompleted!")def format_mrpc(data_dir, path_to_data):print("Processing MRPC...")mrpc_dir = os.path.join(data_dir, "MRPC")if not os.path.isdir(mrpc_dir):os.mkdir(mrpc_dir)if path_to_data:mrpc_train_file = os.path.join(path_to_data, "msr_paraphrase_train.txt")mrpc_test_file = os.path.join(path_to_data, "msr_paraphrase_test.txt")else:print("Local MRPC data not specified, downloading data from %s" % MRPC_TRAIN)mrpc_train_file = os.path.join(mrpc_dir, "msr_paraphrase_train.txt")mrpc_test_file = os.path.join(mrpc_dir, "msr_paraphrase_test.txt")urllib.request.urlretrieve(MRPC_TRAIN, mrpc_train_file)urllib.request.urlretrieve(MRPC_TEST, mrpc_test_file)assert os.path.isfile(mrpc_train_file), "Train data not found at %s" % mrpc_train_fileassert os.path.isfile(mrpc_test_file), "Test data not found at %s" % mrpc_test_fileurllib.request.urlretrieve(TASK2PATH["MRPC"], os.path.join(mrpc_dir, "dev_ids.tsv"))dev_ids = []with open(os.path.join(mrpc_dir, "dev_ids.tsv"), encoding="utf8") as ids_fh:for row in ids_fh:dev_ids.append(row.strip().split('\t'))with open(mrpc_train_file, encoding="utf8") as data_fh, \open(os.path.join(mrpc_dir, "train.tsv"), 'w', encoding="utf8") as train_fh, \open(os.path.join(mrpc_dir, "dev.tsv"), 'w', encoding="utf8") as dev_fh:header = data_fh.readline()train_fh.write(header)dev_fh.write(header)for row in data_fh:label, id1, id2, s1, s2 = row.strip().split('\t')if [id1, id2] in dev_ids:dev_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))else:train_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))with open(mrpc_test_file, encoding="utf8") as data_fh, \open(os.path.join(mrpc_dir, "test.tsv"), 'w', encoding="utf8") as test_fh:header = data_fh.readline()test_fh.write("index\t#1 ID\t#2 ID\t#1 String\t#2 String\n")for idx, row in enumerate(data_fh):label, id1, id2, s1, s2 = row.strip().split('\t')test_fh.write("%d\t%s\t%s\t%s\t%s\n" % (idx, id1, id2, s1, s2))print("\tCompleted!")def download_diagnostic(data_dir):print("Downloading and extracting diagnostic...")if not os.path.isdir(os.path.join(data_dir, "diagnostic")):os.mkdir(os.path.join(data_dir, "diagnostic"))data_file = os.path.join(data_dir, "diagnostic", "diagnostic.tsv")urllib.request.urlretrieve(TASK2PATH["diagnostic"], data_file)print("\tCompleted!")returndef get_tasks(task_names):task_names = task_names.split(',')if "all" in task_names:tasks = TASKSelse:tasks = []for task_name in task_names:assert task_name in TASKS, "Task %s not found!" % task_nametasks.append(task_name)return tasksdef main(arguments):parser = argparse.ArgumentParser()parser.add_argument('--data_dir', help='directory to save data to', type=str, default='glue_data')parser.add_argument('--tasks', help='tasks to download data for as a comma separated string',type=str, default='all')parser.add_argument('--path_to_mrpc', help='path to directory containing extracted MRPC data, msr_paraphrase_train.txt and msr_paraphrase_text.txt',type=str, default='')args = parser.parse_args(arguments)if not os.path.isdir(args.data_dir):os.mkdir(args.data_dir)tasks = get_tasks(args.tasks)for task in tasks:if task == 'MRPC':format_mrpc(args.data_dir, args.path_to_mrpc)elif task == 'diagnostic':download_diagnostic(args.data_dir)else:download_and_extract(task, args.data_dir)if __name__ == '__main__':sys.exit(main(sys.argv[1:]))
起到的作用是, 每个数据集从网址上下载下来, 存储在文件夹中.
2.2 预处理GLUE的数据集
if [[ $# -ne 2 ]]; thenecho "Run as following:"echo "./examples/roberta/preprocess_GLUE_tasks.sh <glud_data_folder> <task_name>"exit 1
fi
- ‘$#’: 是一个特殊的变量, 它表示命令行参数的数量.
- ‘-ne’: 是一个比较运算符, 表示不等于.
- ‘echo “Run as following” ’: epoch是一个命令, 用于在终端输出文本, 所以这段代码表的含义是: 在终端输出这句话.
- ‘exit 1’: exit是一个内置命令, 用于退出当前的脚本或终端会话; 1是一个退出状态码, 用于指示脚本的非正常退出, 非零的退出状态码通常表示发生了错误.
TASKS=$2 # QQP
- ‘TASKS=’: 这是一个变量赋值的语法形式, TASKS是变量名.
- ‘$2’: 这是一个特殊的变量, 在Bash脚本中表示命令行参数的索引位置; '$2’表示命令行参数的第二个参数.
SPLITS="train dev test"INPUT_COUNT=2if [ "$TASK" = "QQP" ] thenINPUT_COLUMNS=( 4 5 ) # train.tsv: id, qid1, qid2, question1, question2, is_duplicateTEST_INPUT_COLUMNS=( 2 3 ) # test.tsv: id, question1, question2LABEL_COLUMN=6elif [ "$TASK" = "MNLI" ]thenSPLITS="train dev_matched dev_mismatched test_matched test_mismatched"INPUT_COLUMNS=( 9 10 ) # train.tsv: index, promptID, pairID, genre, sentence1_binary_parse, sentence2_binary_parse, sentence1_parse, sentence2_parse, sentence1, sentence2, label1, gold_labelTEST_INPUT_COLUMNS=( 9 10 ) DEV_LABEL_COLUMN=16 # dev.tsv: index promptID pairID genre sentence1_binary_parse sentence2_binary_parse sentence1_parse sentence2_parse sentence1 sentence2 label1 label2 label3 label4 label5 gold_labelLABEL_COLUMN=12elif [ "$TASK" = "QNLI" ]thenINPUT_COLUMNS=( 2 3 ) # train.tsv: index, question, sentence, labelTEST_INPUT_COLUMNS=( 2 3 ) LABEL_COLUMN=4elif [ "$TASK" = "MRPC" ]thenINPUT_COLUMNS=( 4 5 ) # train.txt: Quality, #1 ID, #2 ID, #1 String, #2 StringTEST_INPUT_COLUMNS=( 4 5 )LABEL_COLUMN=1elif [ "$TASK" = "RTE" ]thenINPUT_COLUMNS=( 2 3 ) # train.tsv: index, sentence1, sentence2, labelTEST_INPUT_COLUMNS=( 2 3 )LABEL_COLUMN=4elif [ "$TASK" = "STS-B" ]thenINPUT_COLUMNS=( 8 9 ) # train.tsv: index, genre, filename, year, old_index, source1, source2, sentence1, sentence2, scoreTEST_INPUT_COLUMNS=( 8 9 )LABEL_COLUMN=10# Following are single sentence tasks.elif [ "$TASK" = "SST-2" ]thenINPUT_COLUMNS=( 1 ) # train.tsv: sentece, labelTEST_INPUT_COLUMNS=( 2 ) # test.tsv: index, sentenceLABEL_COLUMN=2INPUT_COUNT=1elif [ "$TASK" = "CoLA" ]thenINPUT_COLUMNS=( 4 ) # train.tsv: gj04, 1, *, 'The gardener watered the flowers.'TEST_INPUT_COLUMNS=( 2 ) # test.tsv: index, sentenceLABEL_COLUMN=2INPUT_COUNT=1fi
- ‘INPUT_COLUMNS’: train数据集中的features. 举例: 如果是做两个句子的关联任务, 则features有两个, 分别代表两个句子.(第几列)
- ‘TEST_INPUT_COLUMNS’: test数据集中的features.(第几列)
- ‘LABEL_COLUMN’: train数据集中的flag/score.(第几列)
- ‘DEV_LABEL_COLUMN’: dev数据集中的features.(第几列)
- ‘INPUT_COUNT’: train数据集features的列数.
rm -rf "$TASK_DATA_FOLDER/processed"mkdir -p "$TASK_DATA_FOLDER/processed"
- 删除该数据集文件夹下的processed文件/文件夹, 并创建该数据集目录下文件夹processed, 猜测用于存放处理后的数据.
for SPLIT in $SPLITS # SPLITS: 'train, dev, test' or 'train, dev_matched, dev_mismatched, test_matched, test_mismatched'do# CoLA train and dev doesn't have header.if [[ ( "$TASK" = "CoLA") && ( "$SPLIT" != "test" ) ]]thencp "$TASK_DATA_FOLDER/$SPLIT.tsv" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv.temp";elsetail -n +2 "$TASK_DATA_FOLDER/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/$SPLIT.tsv.temp";fi# Remove unformatted lines from train and dev files for QQP dataset.if [[ ( "$TASK" = "QQP") && ( "$SPLIT" != "test" ) ]]thenawk -F '\t' -v NUM_FIELDS=6 'NF==NUM_FIELDS{print}{}' "$TASK_DATA_FOLDER/processed/$SPLIT.tsv.temp" > "$TASK_DATA_FOLDER/processed/$SPLIT.tsv";elsecp "$TASK_DATA_FOLDER/processed/$SPLIT.tsv.temp" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv";firm "$TASK_DATA_FOLDER/processed/$SPLIT.tsv.temp";done
- 如果是CoLA, 且为train与dev数据集, 则直接cp到/processed/xxx.tsv.temp; 否则将/xxx.temp 的第二行开始读取到/processed/xxx.tsv.temp中. 这其中tail -n +2, 指的是从数据集的第二行开始读取数据.
- 标准的QQP数据集一共有6列, 这里想要通过awk命令来去除掉那些非标准的数据.
# Split into input0, input1 and labelfor SPLIT in $SPLITSdofor INPUT_TYPE in $(seq 0 $((INPUT_COUNT-1)))doif [[ "$SPLIT" != test* ]]thenCOLUMN_NUMBER=${INPUT_COLUMNS[$INPUT_TYPE]}elseCOLUMN_NUMBER=${TEST_INPUT_COLUMNS[$INPUT_TYPE]}ficut -f"$COLUMN_NUMBER" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/$SPLIT.raw.input$INPUT_TYPE";doneif [[ "$SPLIT" != test* ]]thenif [ "$TASK" = "MNLI" ] && [ "$SPLIT" != "train" ]thencut -f"$DEV_LABEL_COLUMN" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/$SPLIT.label";elsecut -f"$LABEL_COLUMN" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/$SPLIT.label";fifi
这段代码的作用是将input, label给提取出来.其中利用了shell命令中的cut命令能够指定原文件的列到输出文件中.
所有的文件被处理到目录: xxx/processed/train.label, xxx/processed/test.raw.input0
# BPE encode.for INPUT_TYPE in $(seq 0 $((INPUT_COUNT-1)))doLANG="input$INPUT_TYPE"echo "BPE encoding $SPLIT/$LANG"python -m examples.roberta.multiprocessing_bpe_encoder \--encoder-json encoder.json \--vocab-bpe vocab.bpe \--inputs "$TASK_DATA_FOLDER/processed/$SPLIT.raw.$LANG" \--outputs "$TASK_DATA_FOLDER/processed/$SPLIT.$LANG" \--workers 60 \--keep-empty;done
使用BPE编码方式, 进行编码.
# Remove output directory.rm -rf "$TASK-bin"DEVPREF="$TASK_DATA_FOLDER/processed/dev.LANG"TESTPREF="$TASK_DATA_FOLDER/processed/test.LANG"if [ "$TASK" = "MNLI" ]thenDEVPREF="$TASK_DATA_FOLDER/processed/dev_matched.LANG,$TASK_DATA_FOLDER/processed/dev_mismatched.LANG"TESTPREF="$TASK_DATA_FOLDER/processed/test_matched.LANG,$TASK_DATA_FOLDER/processed/test_mismatched.LANG"fi# Run fairseq preprocessing:for INPUT_TYPE in $(seq 0 $((INPUT_COUNT-1)))doLANG="input$INPUT_TYPE"fairseq-preprocess \--only-source \--trainpref "$TASK_DATA_FOLDER/processed/train.$LANG" \--validpref "${DEVPREF//LANG/$LANG}" \--testpref "${TESTPREF//LANG/$LANG}" \--destdir "$TASK-bin/$LANG" \--workers 60 \--srcdict dict.txt;doneif [[ "$TASK" != "STS-B" ]]thenfairseq-preprocess \--only-source \--trainpref "$TASK_DATA_FOLDER/processed/train.label" \--validpref "${DEVPREF//LANG/label}" \--destdir "$TASK-bin/label" \--workers 60;else# For STS-B output range is converted to be between: [0.0, 1.0]mkdir -p "$TASK-bin/label"awk '{print $1 / 5.0 }' "$TASK_DATA_FOLDER/processed/train.label" > "$TASK-bin/label/train.label"awk '{print $1 / 5.0 }' "$TASK_DATA_FOLDER/processed/dev.label" > "$TASK-bin/label/valid.label"fi
调用fairseq-preprocess 命令来对数据集进行最后一步的处理.
2.2.1 算法思路与整体代码以及运行结果图
- 整体思路: 将九个glue的文件处理为vector类型的可训练文件.
- 需要的文件:
- glue的九个数据集: CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2, STS-B, WNLI.(第一次测试只处处理前8个数据集)
- 撰写 preprocess_GLUE_task.sh 脚本文件.
- 准备好 BPE encode 的单词表以及使用BPE的python文件, 其中包括 以下文件: examples.roberta.multiprocessing_bpe_encoder, encoder.json, multiprocessing_bpe_encoder.py.
- 细节思路:
-
- 获取各个下游任务的 input_features 以及 label 所在的列.
-
- 去除每个下游任务的head, 这里对于CoLA数据集需要特殊考虑, 因为它本身文件中就没有head.
-
- 去除QQP数据集中一些 unformatted 的 lines.
-
- 利用第一步得到的列以及2,3步得到的清洗后的数据集, 直接提取出features与label.
-
- 使用BPE文件, 对features进行encoding.
-
- 使用 fairseq-preprocess进行train, dev, test数据集的制作, 生成了bin, log与idx文件, 方便后续模型的训练.
-
- 实际操作的例子:
-
- 文件路径设置, 以 all task 为例子, 假设为
~/LLM/GLUE/MyProcess_Glue/preprocess_GLUE_tasks.sh data ALL.
- 文件路径设置, 以 all task 为例子, 假设为
-
- 去掉所有文件的header, 以CoLA为例子, 将 data/CoLA/train.tsv -> ‘data/CoLA/processed/train_temp.tsv’
-
- 去掉QQA数据集中的unformatted的数据line, 并它以及其他数据集存储到 'data/CoLA/processed/train.tsv’中, 将’data/CoLA/processed/train_temp.tsv’删除.
-
- 提取出文件中的 features 和 label 的columns, 这里需要注意MNLI数据集的dev与train中label所在的column是不一样的, 需要分开处理, 其他的都一样; features输出到 ‘data/CoLA/processed/train_raw_input0.tsv’, ‘data/CoLA/processed/train_raw_input1.tsv’; label输出到 ‘data/CoLA/processed/train_label.tsv’;
-
- 使用bpe进行encoding, 将encoding后的文件输出为 ‘CoLA/processed/train_input0.tsv’.
-
- 使用 fairseq-preprocess命令, 将encoding好的文件作为input, 输出对应的bin, log, idx文件, 并放到 CoLA-bin文件夹下.
-
2.2.2 完整代码与处理结果
完整代码
#!/bin/bash
# Copyright (c) Facebook, Inc. and its affiliates.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.# This is my program to address glue dataset.# judge the line
if [[ $# -ne 2 ]]; thenecho "Run as following:"echo "~/LLM/GLUE/MyProcess_Glue/preprocess_GLUE_tasks.sh <glue_data_folder> <tssk_name>"exit 1
fi# get the path of folder
GLUE_DATA_FOLDER=$1
# get the tasks of operating
TASKS=$2# download bpe encoder.json, vocabulary and fairseq dictionary
# wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json'
# wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe'
# wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt'if [ "$TASKS" = "ALL" ]
thenTASKS="QQP MNLI QNLI MRPC RTE STS-B SST-2 CoLA"
fi# the starting of preprocessing tasks
for TASK in $TASKS
doecho "Precessing $TASK"# get current task's directoryTASK_DATA_FOLDER="$GLUE_DATA_FOLDER/$TASK"echo "Raw data as download from glue directory: $TASK_DATA_FOLDER"# We will get three datasetSPLITS="train dev test"INPUT_COUNT=2 # default the number of input senteces# get the columns of features and label, in respect to train, dev, test.if [ "$TASK" = "QQP" ] # train,dev,testthenINPUT_COLUMNS=( 4 5 ) # id,qid1,qid2,question1,question2,is_duplicataTEST_INPUT_COLUMNS=( 2 3 ) # id,question1,question2LABEL_COLUMN=6elif [ "$TASK" = "MNLI" ] # train,test_match,test_mismatch,dev_m,dev_mthenSPLITS="train dev_matched dev_mismatched test_matched test_mismatched"INPUT_COLUMNS=( 9 10 ) # index,proptID,pairID,genre,sentence1_binary_parse,sentence2_binary_parse,sentence1_parse,sentence2_parse,sentence1,sentence2,label1,gold_labelTEST_INPUT_COLUMNS=( 9 10 ) # index,promptID,pairID,genre,sentence1_binary_parse,sentence2_binary_parse,sentence1_parse,sentence2_parse,sentence1,sentence2DEV_LABEL_COLUMN=16 # index,promptID,pairID,genre,sentence1_binary_parse,sentence2_binary_parse,sentence1_parse,sentence2_parse,sentence1,sentence2,label1,label2,label3,label4,label5,gold_labelLABEL_COLUMN=12 elif [ "$TASK" = "QNLI" ] # train,test,devthenINPUT_COLUMNS=( 2 3 ) # index,question,sentence,labelTEST_INPUT_COLUMNS=( 2 3 ) # index, question, sentenceLABEL_COLUMN=4elif [ "$TASK" = "MRPC" ] # train(dev), testthenINPUT_COLUMNS=( 4 5 ) # Quality,1ID,2ID,1String,2StringTEST_INPUT_COLUMNS=( 4 5 ) # Quality,1ID,2ID,1String,2StringLABEL_COLUMN=1elif [ "$TASK" = "RTE" ] # train,dev,testthenINPUT_COLUMNS=( 2 3 ) # index,sentence1,sentence2,labelTEST_INPUT_COLUMNS=( 2 3 ) # index,sentence1,sentence2LABEL_COLUMN=4elif [ "$TASK" = "STS-B" ] # train,dev,testthenINPUT_COLUMNS=( 8 9 ) # index,genre,filename,year,old_index,source1,source2,sentence1,sentence2,scoreTEST_INPUT_COLUMNS=( 8 9 ) # index,genre,filename,year,old_index,source1,source2,sentence1,sentence2LABEL_COLUMN=10elif [ "$TASK" = "SST-2" ] # train,dev,testthenINPUT_COLUMNS=( 1 ) # sentence,labelTEST_INPUT_COLUMNS=( 2 ) # index,sentenceLABEL_COLUMN=2INPUT_COUNT=1elif [ "$TASK" = "CoLA" ] # train(there aren't heads),dev(too),testthenINPUT_COLUMNS=( 4 ) # xxx,1,*,sentenceTEST_INPUT_COLUMNS=( 2 )LABEL_COLUMN=2INPUT_COUNT=1fi # mkdir a folder to save our new dataset processedrm -rf "$TASK_DATA_FOLDER/processed"mkdir -p "$TASK_DATA_FOLDER/processed"get the pointed columns from $TASK_DATA_FOLDER=$GLUE_DATA_FOLDER/$TASKfor SPLIT in $SPLITS do# CoLA train and dev doesn't have hdeader.if [[ ( "$TASK" = "GoLA" ) && ( "$SPLIT" != "test" ) ]]then # CoLA's train or devcp "$TASK_DATA_FOLDER/$SPLIT.tsv" "$TASK_DATA_FOLDER/processed/${SPLIT}_temp.tsv";elsetail -n +2 "$TASK_DATA_FOLDER/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/${SPLIT}_temp.tsv";fi# Remove unformatted lines from train and dev files for QQP dataset.if [[ ( "$TASK" = "QQP" ) && ( "$SPLIT" != "test" ) ]]thenawk -F '\t' -v NUM_FILELDS=6 'NF==NUM_FILELDS{print}{}' "$TASK_DATA_FOLDER/processed/${SPLIT}_temp.tsv" > "$TASK_DATA_FOLDER/processed/$SPLIT.tsv";elsecp "$TASK_DATA_FOLDER/processed/${SPLIT}_temp.tsv" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv";firm "$TASK_DATA_FOLDER/processed/${SPLIT}_temp.tsv";done# Get features and label columns, called them "input0, input1, label"for SPLIT in $SPLITSdo# Extract featuresfor INPUT_TYPE in $(seq 0 $(( INPUT_COUNT - 1 )))do # process the train and dev dataset.if [[ "$SPLIT" != test* ]]then COLUMN_NUMBER=${INPUT_COLUMNS[$INPUT_TYPE]}elseCOLUMN_NUMBER=${TEST_INPUT_COLUMNS[$INPUT_TYPE]}ficut -f "$COLUMN_NUMBER" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/${SPLIT}_raw_input$INPUT_TYPE.tsv";done# Extract labelsif [[ "$SPLIT" != test* ]]thenif [ "$TASK" = "MNLI" ] && [ "$SPLIT" != "train" ] # Only this dataset's dev have a different label column, in respect to train datasetthencut -f "$DEV_LABEL_COLUMN" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/${SPLIT}_label.tsv"; elsecut -f "$LABEL_COLUMN" "$TASK_DATA_FOLDER/processed/$SPLIT.tsv" > "$TASK_DATA_FOLDER/processed/${SPLIT}_label.tsv"; fifi# BPE encodefor INPUT_TYPE in $(seq 0 $(( INPUT_COUNT - 1 )))doLANG="input$INPUT_TYPE" echo "BPE encoding $SPLIT/$LANG"python -m multiprocessing_bpe_encoder \--encoder-json encoder.json \--vocab-bpe vocab.bpe \--inputs "$TASK_DATA_FOLDER/processed/${SPLIT}_raw_$LANG.tsv" \--outputs "$TASK_DATA_FOLDER/processed/${SPLIT}_$LANG.tsv" \--workers 60 \--keep-empty;donedone# Remove output directoryrm -rf "$TASK-bin"DEVPREF="$TASK_DATA_FOLDER/processed/dev_LANG"TESTPREF="$TASK_DATA_FOLDER/processed/test_LANG"if [ "$TASK" = "MNLI" ]thenDEVPREF="$TASK_DATA_FOLDER/processed/dev_matched_LANG,$TASK_DATA_FOLDER/processed/dev_mismatched_LANG"TESTPREF="$TASK_DATA_FOLDER/processed/test_matched_LANG,$TASK_DATA_FOLDER/processd/test_mismatched_LANG"fi# Run fairseq preprocessing:for INPUT_TYPE in $(seq 0 $(( INPUT_COUNT-1 )))doLANG="input$INPUT_TYPE.tsv"fairseq-preprocess \--only-source \--trainpref "$TASK_DATA_FOLDER/processed/train_$LANG" \--validpref "${DEVPREF//LANG/$LANG}" \--testpref "${TESTPREF//LANG/$LANG}" \--destdir "$TASK-bin/$LANG" \--workers 60 \--srcdict dict.txt;doneif [[ "$TASK" != "STS-B" ]]thenfairseq-preprocess \--only-source \--trainpref "$TASK_DATA_FOLDER/processed/train_label.tsv" \--validpref "${DEVPREF//LANG/label.tsv}" \--destdir "$TASK-bin/label" \--workers 60;else# For STS-B output range is converted to be between: [0.0, 1.0]awk '{print $1 / 5.0 }' "$TASK_DATA_FOLDER/processed/train_label.tsv" > "$TASK-bin/label/train_label.tsv"awk '{print $1 / 5.0 }' "$TASK_DATA_FOLDER/processed/dev_label.tsv" > "$TASK-bin/label/valid_label.tsv" fi
done
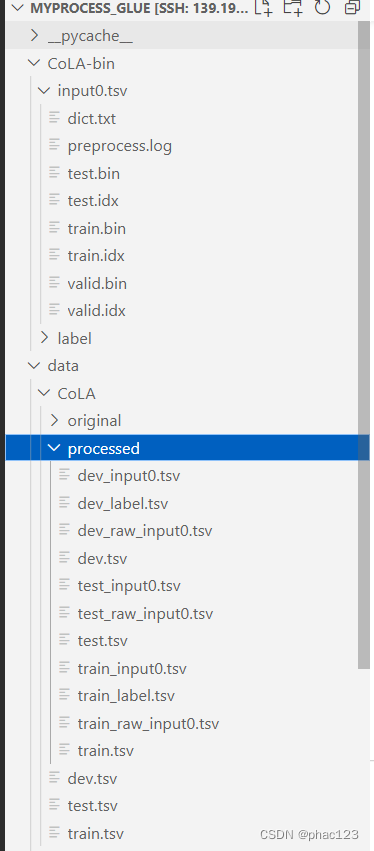
处理结果:
三. 使用预处理好的数据集进行 finetune
3.1 将RoBERTa的模型下载到本地
这里我使用base模型来做例子.

3.2 微调任务之RTE(句子二分类任务)
- 需要涉及到的文件
-
- Pretrain的model(.pt)文件
-
- 指令: fairseq-hydra-train
-
- 对应下游任务的yaml文件, 这里是RTE.yaml
-
- 微调的数据集文件(文件夹), RTE-bin.
-
- 指定需要存储的checkpoint路径文件.(一般与model文件是一样的).
-
- shell代码:
#!/bin/bashROBERTA_PATH=/home/phac123/LLM/RoBERTa/fine_tune_demo1_RTE/base/model.ptCUDA_VISIBLE_DEVICES=1 fairseq-hydra-train --config-dir /home/phac123/LLM/RoBERTa/fine_tune_demo1_RTE/ --config-name rte \
task.data=/home/phac123/LLM/RoBERTa/fine_tune_demo1_RTE/RTE-bin checkpoint.restore_file=$ROBERTA_PATH