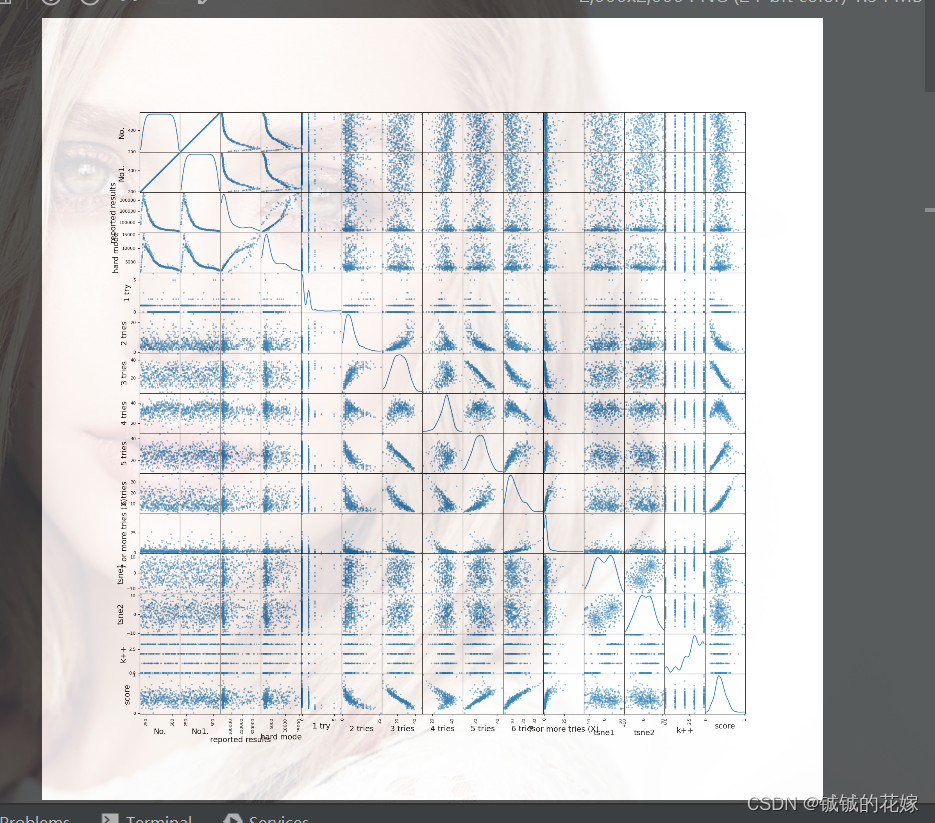
Python 数据集预处理指南:从混乱到有序
在数据分析和机器学习领域,数据预处理是至关重要的一步。预处理的目的是将不规则、混乱的数据转化为适合分析的数据格式,使得数据能够按照一定的规则进行处理和分析。本文将介绍 Python 数据集预处理的基本步骤和技巧,帮助你将混乱的数据集转化成有序的数据集。
1. 数据集的探索
在进行数据预处理之前,我们需要先了解数据集的全貌,并探明其中的问题。可以使用 pandas 这样的分析工具来打开数据集,通过 describe() 函数来查看数据的统计信息,或通过 head() 函数查看数据的前几行。
import pandas as pddata = pd.read_csv("data.csv")# 查看数据的前5行
print(data.head())# 查看数据的统计信息
print(data.describe())
2. 数据清洗
在探索数据集时,我们可能会发现数据集中存在缺失值、异常值或重复值,需要对其进行清洗。
- 缺失值处理:
缺失值指的是数据集中某些数据未被记录或记录不完整的情况。常见的处理方法是删除缺失值或进行填充处理。删除缺失值的方法通常使用 dropna() 函数,而填充缺失值的方法通常使用 fillna() 函数。
# 删除缺失值
data.dropna(inplace=True)# 将缺失值填充为均值
data.fillna(data.mean(), inplace=True)
- 异常值处理:
异常值指的是数据集中的值与其它值相差较大的情况,需要对其进行处理。可以使用 z-score 标准化方法或箱线图来识别和处理异常值。
# 计算 z-score 标准化值
z_score = (data - data.mean()) / data.std()# 删除 z-score 大于3的数据
data = data[(z_score < 3) & (z_score > -3)]# 通过箱线图筛选出异常值
data.boxplot()
- 重复值处理:
重复值指的是数据集中存在完全相同的数据。可以使用 Pandas 中的 drop_duplicates() 函数来删除重复值。
# 删除重复值
data.drop_duplicates(inplace=True)
3. 数据转换
数据清洗后,我们需要将数据转换为适合分析和建模的形式。可以使用如下方法进行转换:
- 数据类型转换:
根据数据的实际类型,将其转化为适合的数据类型,比如将字符串转化为数值型。
# 将字符串转化为数值型
data["age"] = pd.to_numeric(data["age"])
- 数据归一化:
归一化指的是将数据按比例缩小,使其数值域落在 [0,1] 之间。这种方法常用于数据的相似性分析或特征提取。
# 数据归一化
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()
scaling_data = scaler.fit_transform(data)
- 数据标准化:
标准化指的是将数据按照特征的数量级相除,使得数据的均值为0,标准差为1。常见的方法有 z-score 标准化和均值归一化方法。
# z-score 标准化
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
standard_data = scaler.fit_transform(data)# 均值归一化
from sklearn.preprocessing import scalemean_data = scale(data)
4. 数据集的重构
在完成数据清洗和转换后,我们还需要对数据集进行重构,以满足特定的分析或建模需求。可以使用 Pandas 中的 DataFrame 或 NumPy 中的数组来进行重构。
# 使用 Pandas DataFrame 进行重构
new_data = pd.DataFrame(data={"age": data["age"], "gender": data["gender"],"income": data["income"]
})# 使用 NumPy 数组进行重构
new_data = np.array([data["age"], data["gender"], data["income"]])
结论
数据预处理是进行数据分析和建模的关键步骤,合理的数据预处理可以提高数据模型的效率和准确性。在进行 Python 数据集预处理时,我们需要探索数据集、清洗数据、转换数据并对数据集进行重构。熟练掌握这些技能,可以为你提供更好的数据分析和建模帮助。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
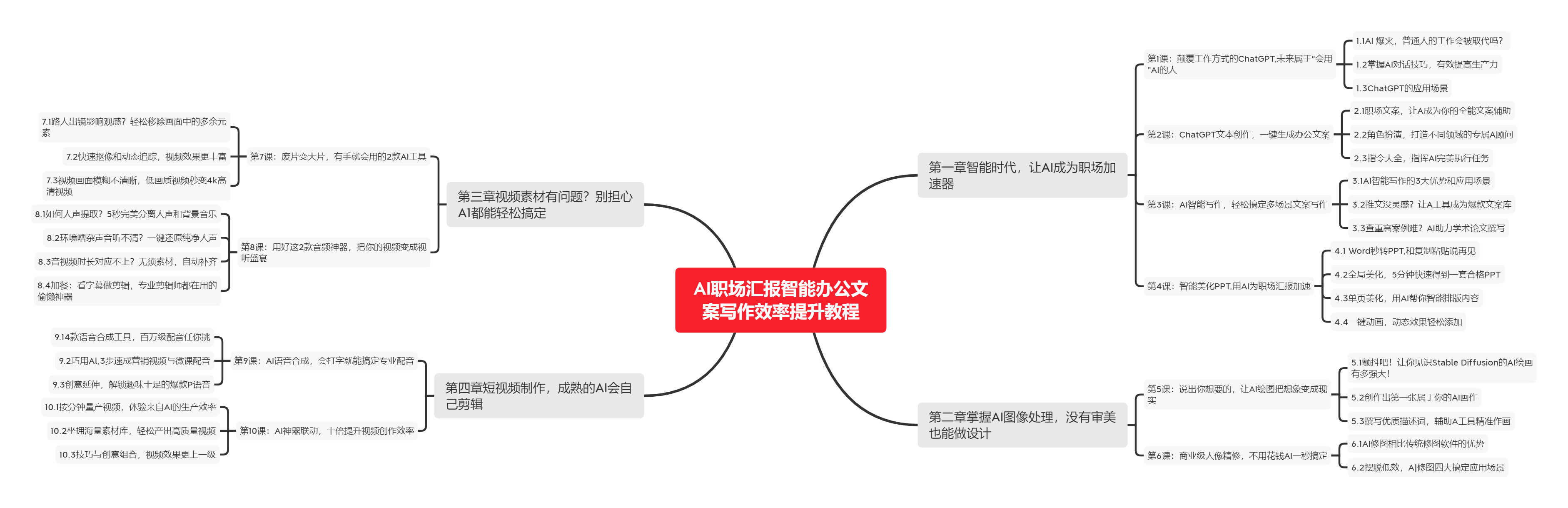
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |